
Paper List
-
A Unified Variational Principle for Branching Transport Networks: Wave Impedance, Viscous Flow, and Tissue Metabolism
This paper solves the core problem of predicting the empirically observed branching exponent (α≈2.7) in mammalian arterial trees, which neither Murray...
-
Household Bubbling Strategies for Epidemic Control and Social Connectivity
This paper addresses the core challenge of designing household merging (social bubble) strategies that effectively control epidemic risk while maximiz...
-
Empowering Chemical Structures with Biological Insights for Scalable Phenotypic Virtual Screening
This paper addresses the core challenge of bridging the gap between scalable chemical structure screening and biologically informative but resource-in...
-
A mechanical bifurcation constrains the evolution of cell sheet folding in the family Volvocaceae
This paper addresses the core problem of why there is an evolutionary gap in species with intermediate cell numbers (e.g., 256 cells) in Volvocaceae, ...
-
Bayesian Inference in Epidemic Modelling: A Beginner’s Guide Illustrated with the SIR Model
This guide addresses the core challenge of estimating uncertain epidemiological parameters (like transmission and recovery rates) from noisy, real-wor...
-
Geometric framework for biological evolution
This paper addresses the fundamental challenge of developing a coordinate-independent, geometric description of evolutionary dynamics that bridges gen...
-
A multiscale discrete-to-continuum framework for structured population models
This paper addresses the core challenge of systematically deriving uniformly valid continuum approximations from discrete structured population models...
-
Whole slide and microscopy image analysis with QuPath and OMERO
使QuPath能够直接分析存储在OMERO服务器中的图像而无需下载整个数据集,克服了大规模研究的本地存储限制。
Emergent Bayesian Behaviour and Optimal Cue Combination in LLMs
Huawei Noah’s Ark Lab, London, UK | AI Centre, Department of Computer Science, University College London, London, UK
30秒速读
IN SHORT: This paper addresses the critical gap in understanding whether LLMs spontaneously develop human-like Bayesian strategies for processing uncertain information, revealing that high accuracy does not guarantee robust multimodal integration.
核心创新
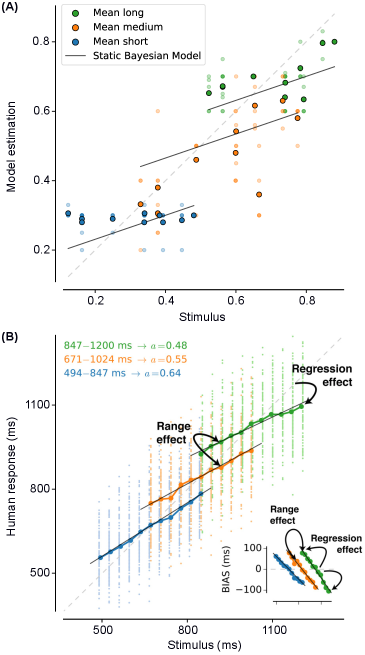
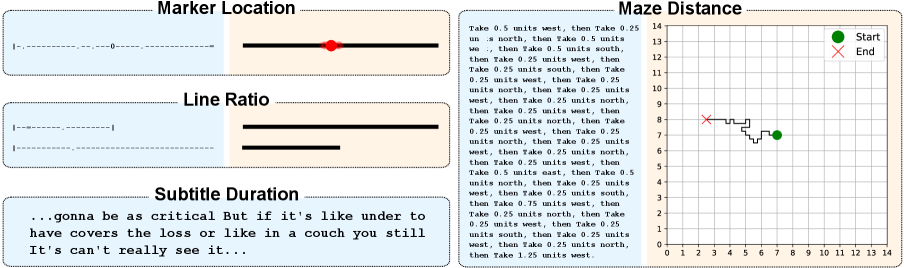
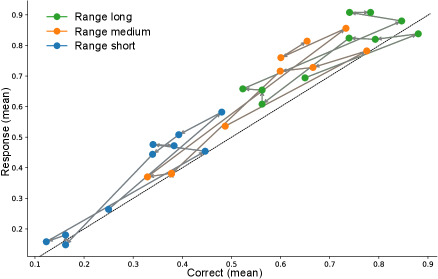
- Methodology Introduces BayesBench, the first psychophysics-inspired behavioral benchmark for LLMs with four magnitude estimation tasks (length, location, distance, duration) across text and image modalities.
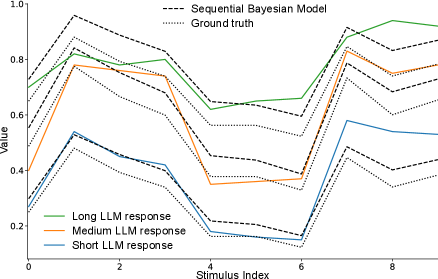
- Methodology Develops Bayesian Consistency Score (BCS) to detect Bayes-consistent behavioral shifts even when accuracy saturates, enabling separation of capability from computational strategy.
- Biology Demonstrates emergent Bayesian behavior in capable LLMs without explicit training, with Llama-4 Maverick showing cue-combination efficiency exceeding human biological systems (RRE > 1 against Bayesian oracle).
主要结论
- GPT-5 Mini achieves perfect text accuracy (NRMSE ≈ 0) but fails to integrate visual cues efficiently, showing poor cue-combination efficiency (RRE < 1) despite high capability.
- Llama-4 Maverick demonstrates emergent Bayesian behavior with cue-combination efficiency exceeding Bayesian reliability-weighted baselines (RRE > 1), suggesting non-linear integration strategies.
- Bayesian Consistency Score reveals that more accurate models show stronger evidence of Bayesian behavior, with BCS positively correlated with accuracy across nine evaluated LLMs.
摘要: Large language models (LLMs) excel at explicit reasoning, but their implicit computational strategies remain underexplored. Decades of psychophysics research show that humans intuitively process and integrate noisy signals using near-optimal Bayesian strategies in perceptual tasks. We ask whether LLMs exhibit similar behaviour and perform optimal multimodal integration without explicit training or instruction. Adopting the psychophysics paradigm, we infer computational principles of LLMs from systematic behavioural studies. We introduce a behavioural benchmark - BayesBench: four magnitude estimation tasks (length, location, distance, and duration) over text and image, inspired by classic psychophysics, and evaluate a diverse set of nine LLMs alongside human judgments for calibration. Through controlled ablations of noise, context, and instruction prompts, we measure performance, behaviour and efficiency in multimodal cue-combination. Beyond accuracy and efficiency metrics, we introduce a Bayesian Consistency Score that detects Bayes-consistent behavioural shifts even when accuracy saturates. Our results show that while capable models often adapt in Bayes-consistent ways, accuracy does not guarantee robustness. Notably, GPT-5 Mini achieves perfect text accuracy but fails to integrate visual cues efficiently. This reveals a critical dissociation between capability and strategy, suggesting accuracy-centric benchmarks may over-index on performance while missing brittle uncertainty handling. These findings reveal emergent principled handling of uncertainty and highlight the correlation between accuracy and Bayesian tendencies. We release our psychophysics benchmark and consistency metric as evaluation tools and to inform future multimodal architecture designs111Project webpage: https://bayes-bench.github.io.