
Paper List
-
A Unified Variational Principle for Branching Transport Networks: Wave Impedance, Viscous Flow, and Tissue Metabolism
This paper solves the core problem of predicting the empirically observed branching exponent (α≈2.7) in mammalian arterial trees, which neither Murray...
-
Household Bubbling Strategies for Epidemic Control and Social Connectivity
This paper addresses the core challenge of designing household merging (social bubble) strategies that effectively control epidemic risk while maximiz...
-
Empowering Chemical Structures with Biological Insights for Scalable Phenotypic Virtual Screening
This paper addresses the core challenge of bridging the gap between scalable chemical structure screening and biologically informative but resource-in...
-
A mechanical bifurcation constrains the evolution of cell sheet folding in the family Volvocaceae
This paper addresses the core problem of why there is an evolutionary gap in species with intermediate cell numbers (e.g., 256 cells) in Volvocaceae, ...
-
Bayesian Inference in Epidemic Modelling: A Beginner’s Guide Illustrated with the SIR Model
This guide addresses the core challenge of estimating uncertain epidemiological parameters (like transmission and recovery rates) from noisy, real-wor...
-
Geometric framework for biological evolution
This paper addresses the fundamental challenge of developing a coordinate-independent, geometric description of evolutionary dynamics that bridges gen...
-
A multiscale discrete-to-continuum framework for structured population models
This paper addresses the core challenge of systematically deriving uniformly valid continuum approximations from discrete structured population models...
-
Whole slide and microscopy image analysis with QuPath and OMERO
使QuPath能够直接分析存储在OMERO服务器中的图像而无需下载整个数据集,克服了大规模研究的本地存储限制。
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
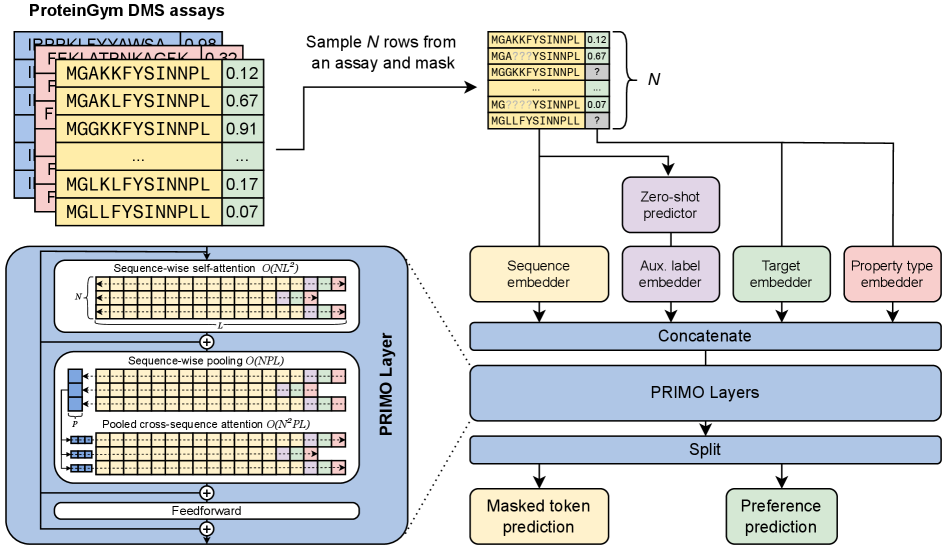
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.