
Paper List
-
A Unified Variational Principle for Branching Transport Networks: Wave Impedance, Viscous Flow, and Tissue Metabolism
This paper solves the core problem of predicting the empirically observed branching exponent (α≈2.7) in mammalian arterial trees, which neither Murray...
-
Household Bubbling Strategies for Epidemic Control and Social Connectivity
This paper addresses the core challenge of designing household merging (social bubble) strategies that effectively control epidemic risk while maximiz...
-
Empowering Chemical Structures with Biological Insights for Scalable Phenotypic Virtual Screening
This paper addresses the core challenge of bridging the gap between scalable chemical structure screening and biologically informative but resource-in...
-
A mechanical bifurcation constrains the evolution of cell sheet folding in the family Volvocaceae
This paper addresses the core problem of why there is an evolutionary gap in species with intermediate cell numbers (e.g., 256 cells) in Volvocaceae, ...
-
Bayesian Inference in Epidemic Modelling: A Beginner’s Guide Illustrated with the SIR Model
This guide addresses the core challenge of estimating uncertain epidemiological parameters (like transmission and recovery rates) from noisy, real-wor...
-
Geometric framework for biological evolution
This paper addresses the fundamental challenge of developing a coordinate-independent, geometric description of evolutionary dynamics that bridges gen...
-
A multiscale discrete-to-continuum framework for structured population models
This paper addresses the core challenge of systematically deriving uniformly valid continuum approximations from discrete structured population models...
-
Whole slide and microscopy image analysis with QuPath and OMERO
使QuPath能够直接分析存储在OMERO服务器中的图像而无需下载整个数据集,克服了大规模研究的本地存储限制。
Training Dynamics of Learning 3D-Rotational Equivariance
Genentech Computational Sciences | New York University
30秒速读
IN SHORT: This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with data augmentation, by quantifying the speed and extent to which the latter learn 3D rotational symmetry.
核心创新
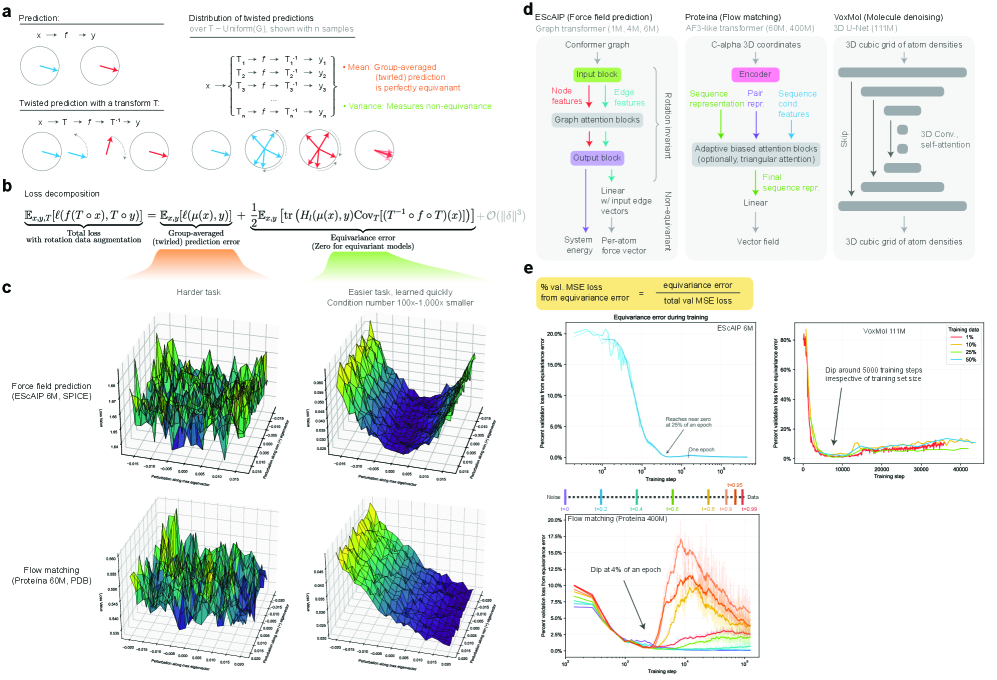
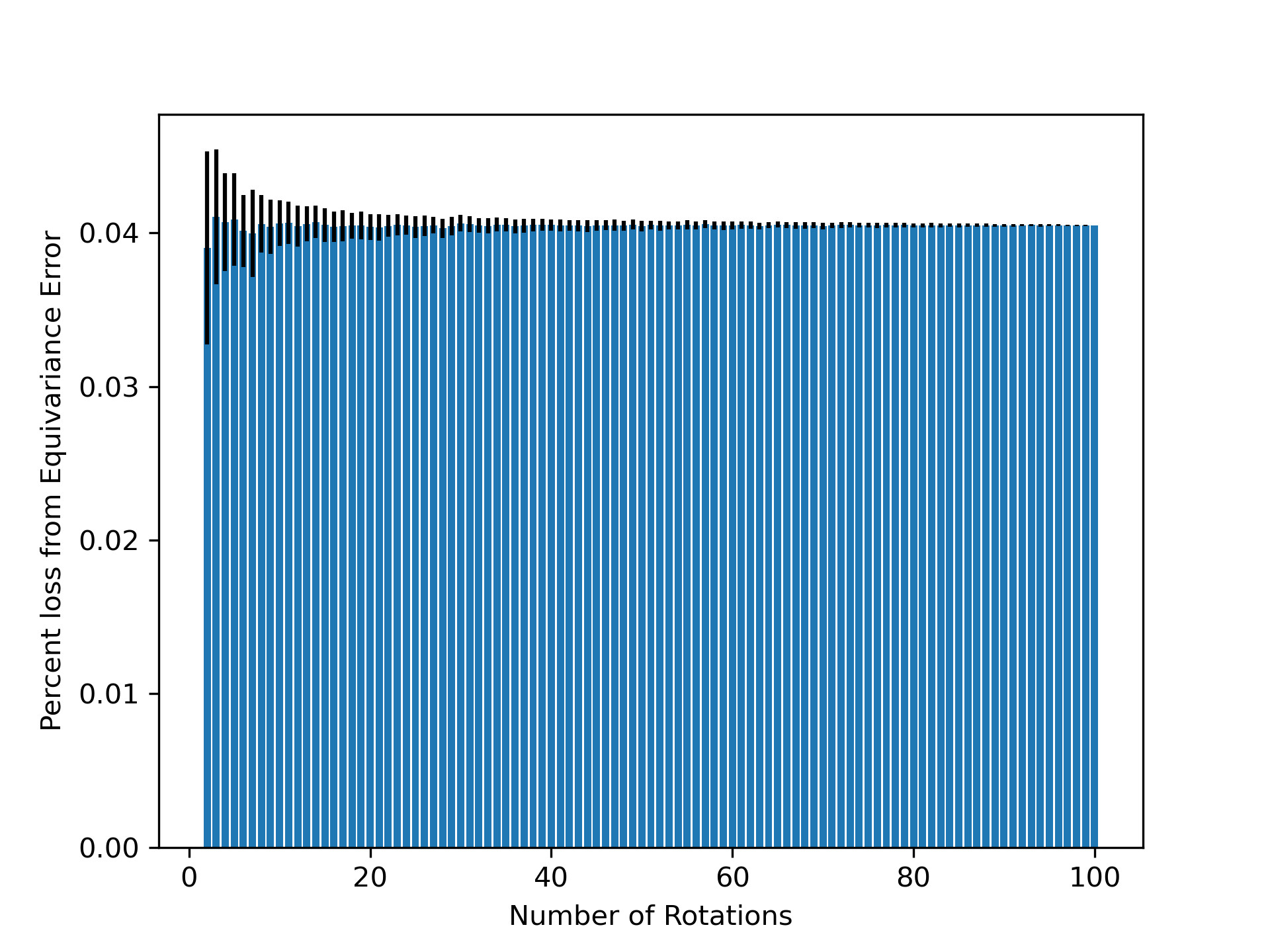
- Methodology Introduces a principled, generalizable framework to decompose total loss into a 'twirled prediction error' (ℒ_mean) and an 'equivariance error' (ℒ_equiv), enabling precise measurement of the percent of loss attributable to imperfect symmetry learning.
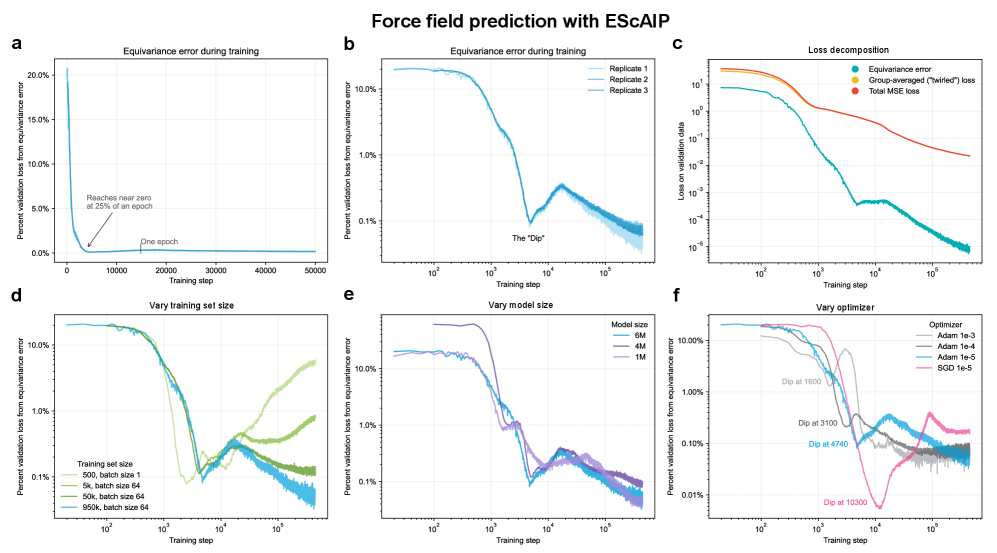
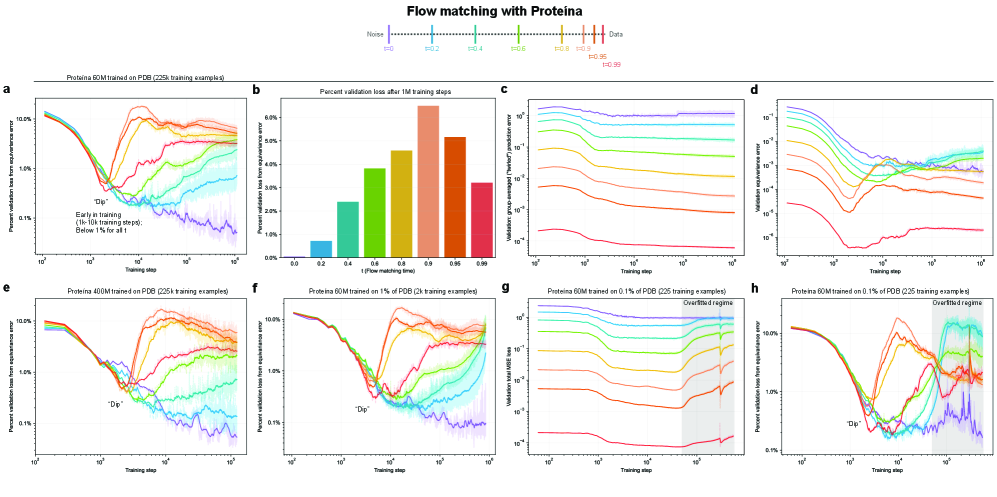
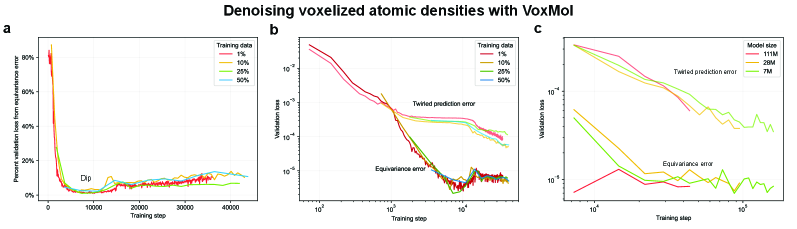
- Methodology Empirically demonstrates that models learning 3D-rotational equivariance via data augmentation achieve very low equivariance error (≤2% of total loss) remarkably quickly, within 1k-10k training steps, across diverse molecular tasks and model scales.
- Theory Provides theoretical and experimental evidence that learning equivariance is an easier task than the main prediction, characterized by a smoother and better-conditioned loss landscape (e.g., 1000x lower condition number for ℒ_equiv vs. ℒ_mean in force field prediction).
主要结论
- Non-equivariant models with data augmentation learn 3D rotational equivariance rapidly and effectively, reducing the equivariance error component to ≤2% of the total validation loss within the first 1k-10k training steps.
- The loss penalty for imperfect equivariance (ℒ_equiv) is small throughout training for 3D rotations, meaning the primary trade-off is the 'efficiency gap' (slower training/inference of equivariant models) rather than a significant accuracy penalty.
- The speed of learning equivariance is robust to model size (1M to 400M parameters), dataset size (500 to 1M samples), and optimizer choice, indicating it is a fundamental property of the learning task landscape.
摘要: While data augmentation is widely used to train symmetry-agnostic models, it remains unclear how quickly and effectively they learn to respect symmetries. We investigate this by deriving a principled measure of equivariance error that, for convex losses, calculates the percent of total loss attributable to imperfections in learned symmetry. We focus our empirical investigation to 3D-rotation equivariance on high-dimensional molecular tasks (flow matching, force field prediction, denoising voxels) and find that models reduce equivariance error quickly to ≤2% held-out loss within 1k-10k training steps, a result robust to model and dataset size. This happens because learning 3D-rotational equivariance is an easier learning task, with a smoother and better-conditioned loss landscape, than the main prediction task. For 3D rotations, the loss penalty for non-equivariant models is small throughout training, so they may achieve lower test loss than equivariant models per GPU-hour unless the equivariant “efficiency gap” is narrowed. We also experimentally and theoretically investigate the relationships between relative equivariance error, learning gradients, and model parameters.