
Paper List
-
A Unified Variational Principle for Branching Transport Networks: Wave Impedance, Viscous Flow, and Tissue Metabolism
This paper solves the core problem of predicting the empirically observed branching exponent (α≈2.7) in mammalian arterial trees, which neither Murray...
-
Household Bubbling Strategies for Epidemic Control and Social Connectivity
This paper addresses the core challenge of designing household merging (social bubble) strategies that effectively control epidemic risk while maximiz...
-
Empowering Chemical Structures with Biological Insights for Scalable Phenotypic Virtual Screening
This paper addresses the core challenge of bridging the gap between scalable chemical structure screening and biologically informative but resource-in...
-
A mechanical bifurcation constrains the evolution of cell sheet folding in the family Volvocaceae
This paper addresses the core problem of why there is an evolutionary gap in species with intermediate cell numbers (e.g., 256 cells) in Volvocaceae, ...
-
Bayesian Inference in Epidemic Modelling: A Beginner’s Guide Illustrated with the SIR Model
This guide addresses the core challenge of estimating uncertain epidemiological parameters (like transmission and recovery rates) from noisy, real-wor...
-
Geometric framework for biological evolution
This paper addresses the fundamental challenge of developing a coordinate-independent, geometric description of evolutionary dynamics that bridges gen...
-
A multiscale discrete-to-continuum framework for structured population models
This paper addresses the core challenge of systematically deriving uniformly valid continuum approximations from discrete structured population models...
-
Whole slide and microscopy image analysis with QuPath and OMERO
使QuPath能够直接分析存储在OMERO服务器中的图像而无需下载整个数据集,克服了大规模研究的本地存储限制。
Hypothesis-Based Particle Detection for Accurate Nanoparticle Counting and Digital Diagnostics
Institute for Digital Molecular Analytics and Science (IDMxS), Nanyang Technological University, Singapore | School of Electrical and Electronic Engineering, Nanyang Technological University, Singapore
30秒速读
IN SHORT: This paper addresses the core challenge of achieving accurate, interpretable, and training-free nanoparticle counting in digital diagnostic assays, which is critical for detecting low-abundance biomarkers with high sensitivity.
核心创新
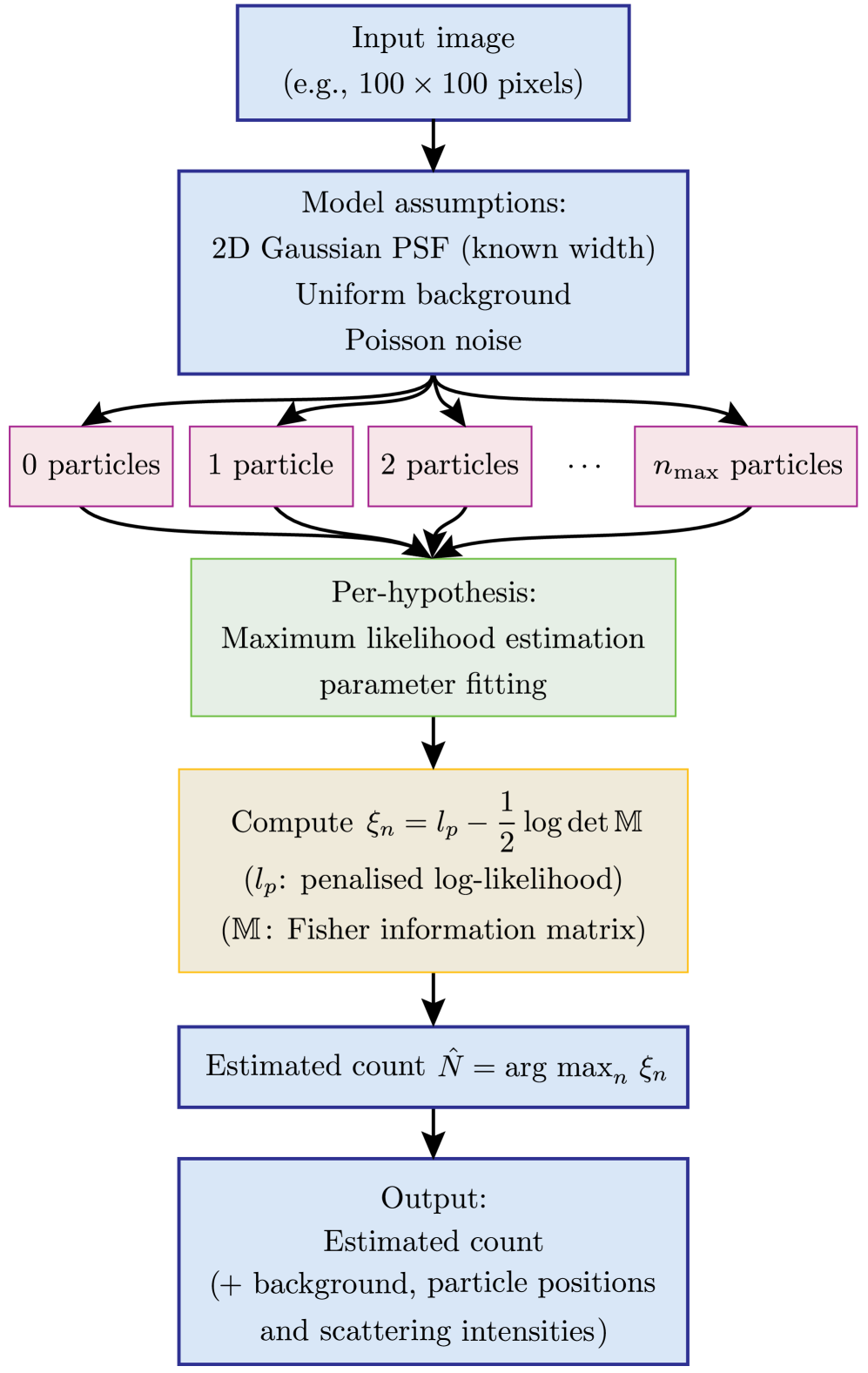
- Methodology Introduces a multiple-hypothesis statistical testing framework for particle counting, eliminating the need for empirical thresholds or training data common in traditional and ML-based methods.
- Methodology Formulates the detection problem under an explicit image-formation model (Poisson noise, Gaussian PSF) and uses a penalized likelihood rule with an information-criterion complexity penalty for robust hypothesis selection.
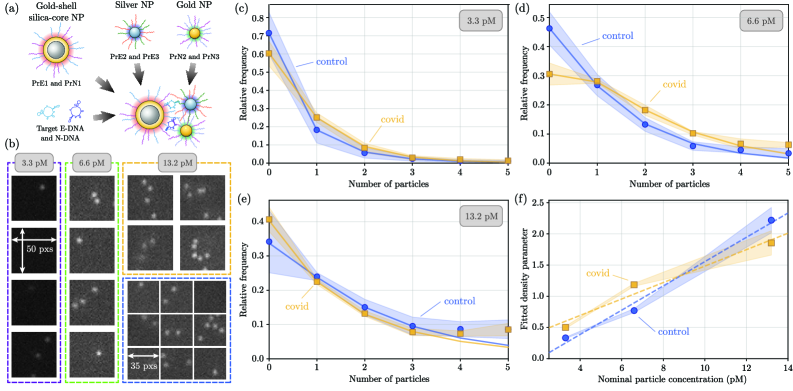
- Biology/Application Validates the method on experimental dark-field images of a nanoparticle-based assay for SARS-CoV-2 DNA biomarkers, demonstrating statistically significant differentiation between control and positive samples and providing insights into particle aggregation.
主要结论
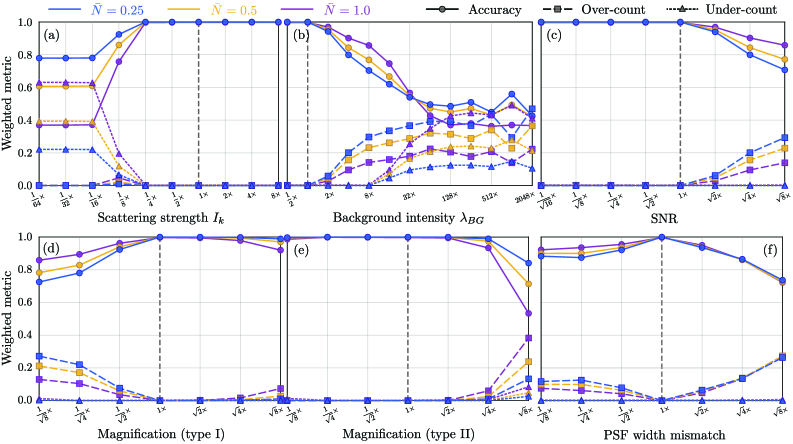
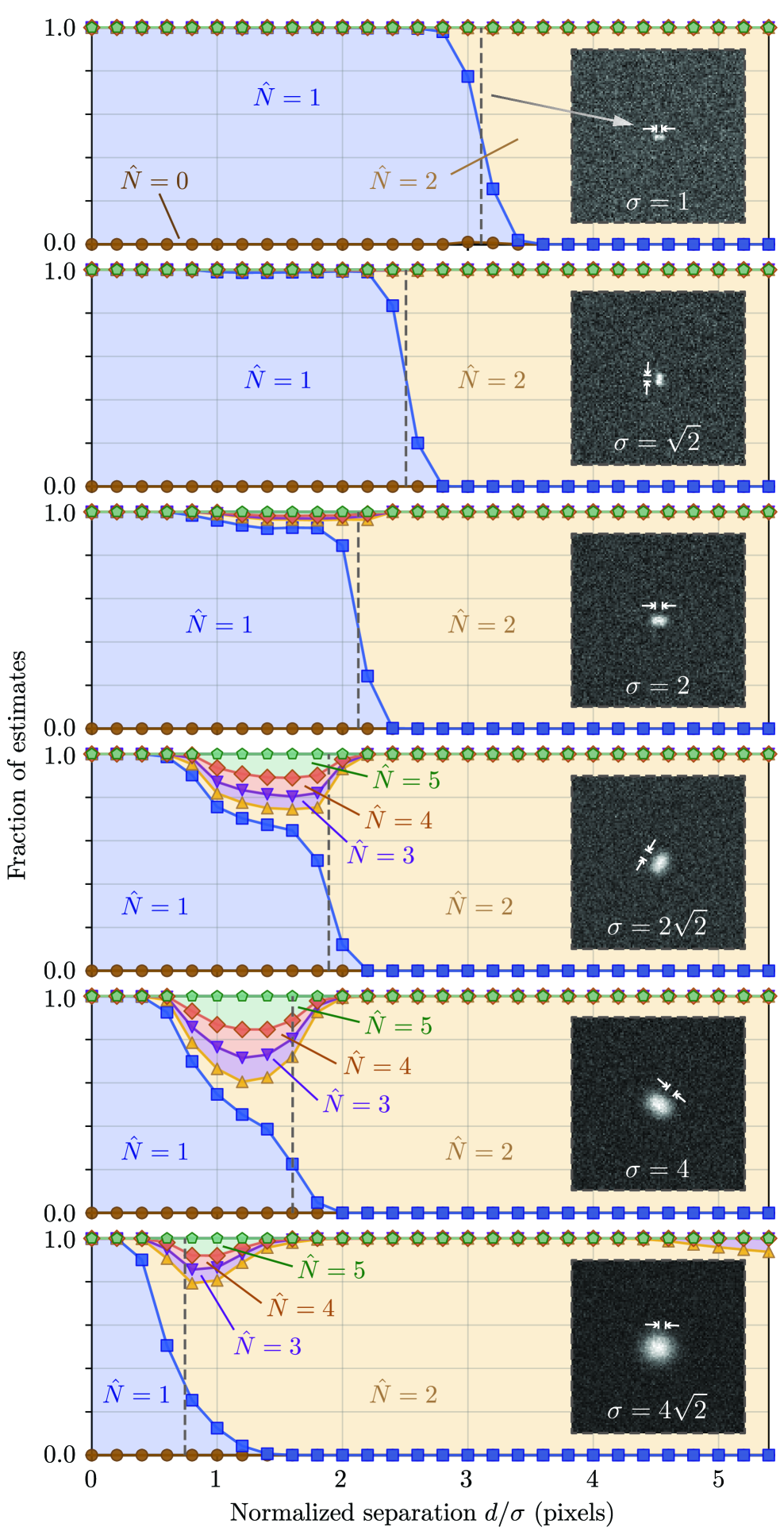
- The algorithm demonstrates robust count accuracy in simulations across challenging conditions: weak signals (low SBR), variable backgrounds, magnification changes, and moderate PSF mismatch.
- Applied to experimental SARS-CoV-2 biomarker detection, the method revealed statistically significant differences in particle count distributions between control and positive samples, confirming practical utility.
- Full count statistics from the experimental assay exhibited consistent over-dispersion, providing quantitative insight into non-specific and target-induced nanoparticle aggregation phenomena.
摘要: Digital assays represent a shift from traditional diagnostics and enable the precise detection of low-abundance analytes, critical for early disease diagnosis and personalized medicine, through discrete counting of biomolecular reporters. Within this paradigm, we present a particle counting algorithm for nanoparticle based imaging assays, formulated as a multiple-hypothesis statistical test under an explicit image-formation model and evaluated using a penalized likelihood rule. In contrast to thresholding or machine learning methods, this approach requires no training data or empirical parameter tuning, and its outputs remain interpretable through direct links to imaging physics and statistical decision theory. Through numerical simulations we demonstrate robust count accuracy across weak signals, variable backgrounds, magnification changes and moderate PSF mismatch. Particle resolvability tests further reveal characteristic error modes, including under-counting at very small separations and localized over-counting near the resolution limit. Practically, we also confirm the algorithm’s utility, through application to experimental dark-field images comprising a nanoparticle-based assay for detection of DNA biomarkers derived from SARS-CoV-2. Statistically significant differences in particle count distributions are observed between control and positive samples. Full count statistics obtained further exhibit consistent over-dispersion, and provide insight into non-specific and target-induced particle aggregation. These results establish our method as a reliable framework for nanoparticle-based detection assays in digital molecular diagnostics.