
Paper List
-
Developing the PsyCogMetrics™ AI Lab to Evaluate Large Language Models and Advance Cognitive Science
This paper addresses the critical gap between sophisticated LLM evaluation needs and the lack of accessible, scientifically rigorous platforms that in...
-
Equivalence of approximation by networks of single- and multi-spike neurons
This paper resolves the fundamental question of whether single-spike spiking neural networks (SNNs) are inherently less expressive than multi-spike SN...
-
The neuroscience of transformers
提出了Transformer架构与皮层柱微环路之间的新颖计算映射,连接了现代AI与神经科学。
-
Framing local structural identifiability and observability in terms of parameter-state symmetries
This paper addresses the core challenge of systematically determining which parameters and states in a mechanistic ODE model can be uniquely inferred ...
-
Leveraging Phytolith Research using Artificial Intelligence
This paper addresses the critical bottleneck in phytolith research by automating the labor-intensive manual microscopy process through a multimodal AI...
-
Neural network-based encoding in free-viewing fMRI with gaze-aware models
This paper addresses the core challenge of building computationally efficient and ecologically valid brain encoding models for naturalistic vision by ...
-
Scalable DNA Ternary Full Adder Enabled by a Competitive Blocking Circuit
This paper addresses the core bottleneck of carry information attenuation and limited computational scale in DNA binary adders by introducing a scalab...
-
ELISA: An Interpretable Hybrid Generative AI Agent for Expression-Grounded Discovery in Single-Cell Genomics
This paper addresses the critical bottleneck of translating high-dimensional single-cell transcriptomic data into interpretable biological hypotheses ...
SSDLabeler: Realistic semi-synthetic data generation for multi-label artifact classification in EEG
Sony Computer Science Laboratories, Inc., Tokyo, Japan
30秒速读
IN SHORT: This paper addresses the core challenge of training robust multi-label EEG artifact classifiers by overcoming the scarcity and limited diversity of manually labeled training data through a novel semi-synthetic data generation framework.
核心创新
- Methodology Introduces SSDLabeler, a framework that generates realistic semi-synthetic EEG data by simultaneously reinjecting multiple ICA-isolated artifact types into clean data, preserving the co-occurrence structure of real-world contamination.
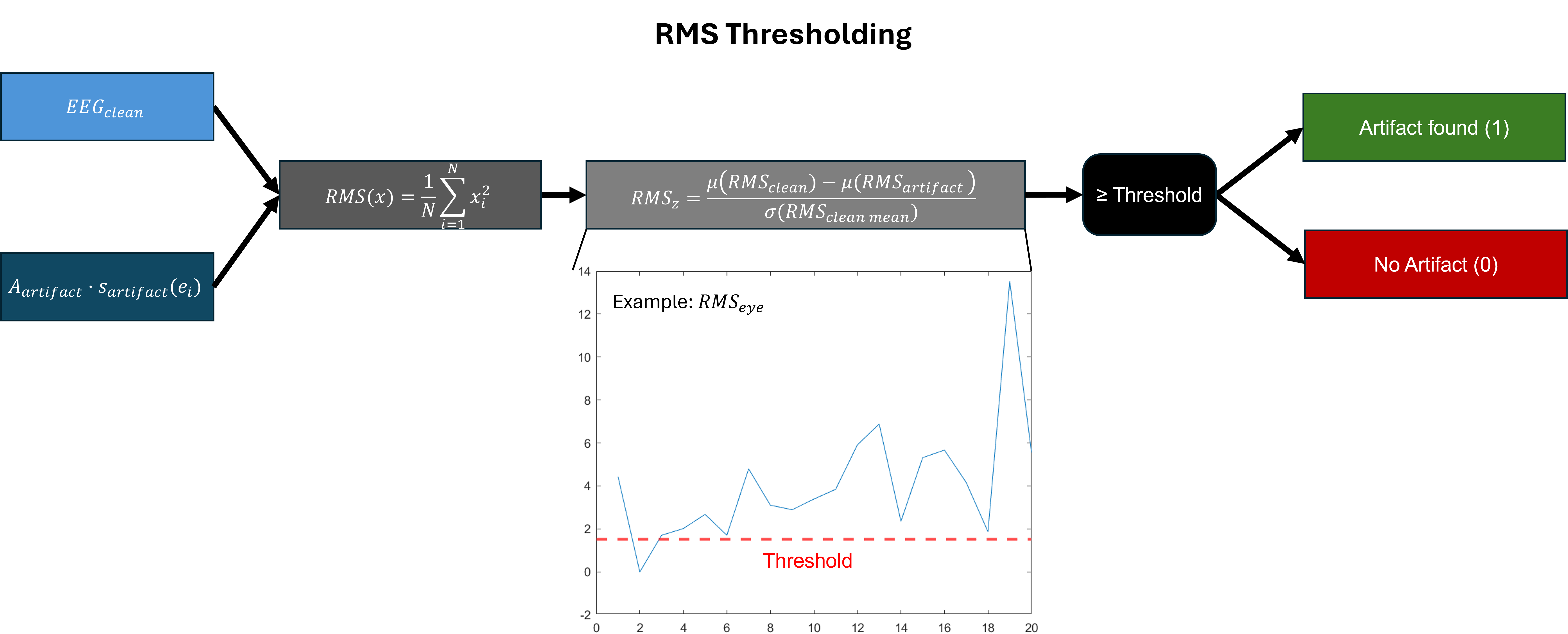
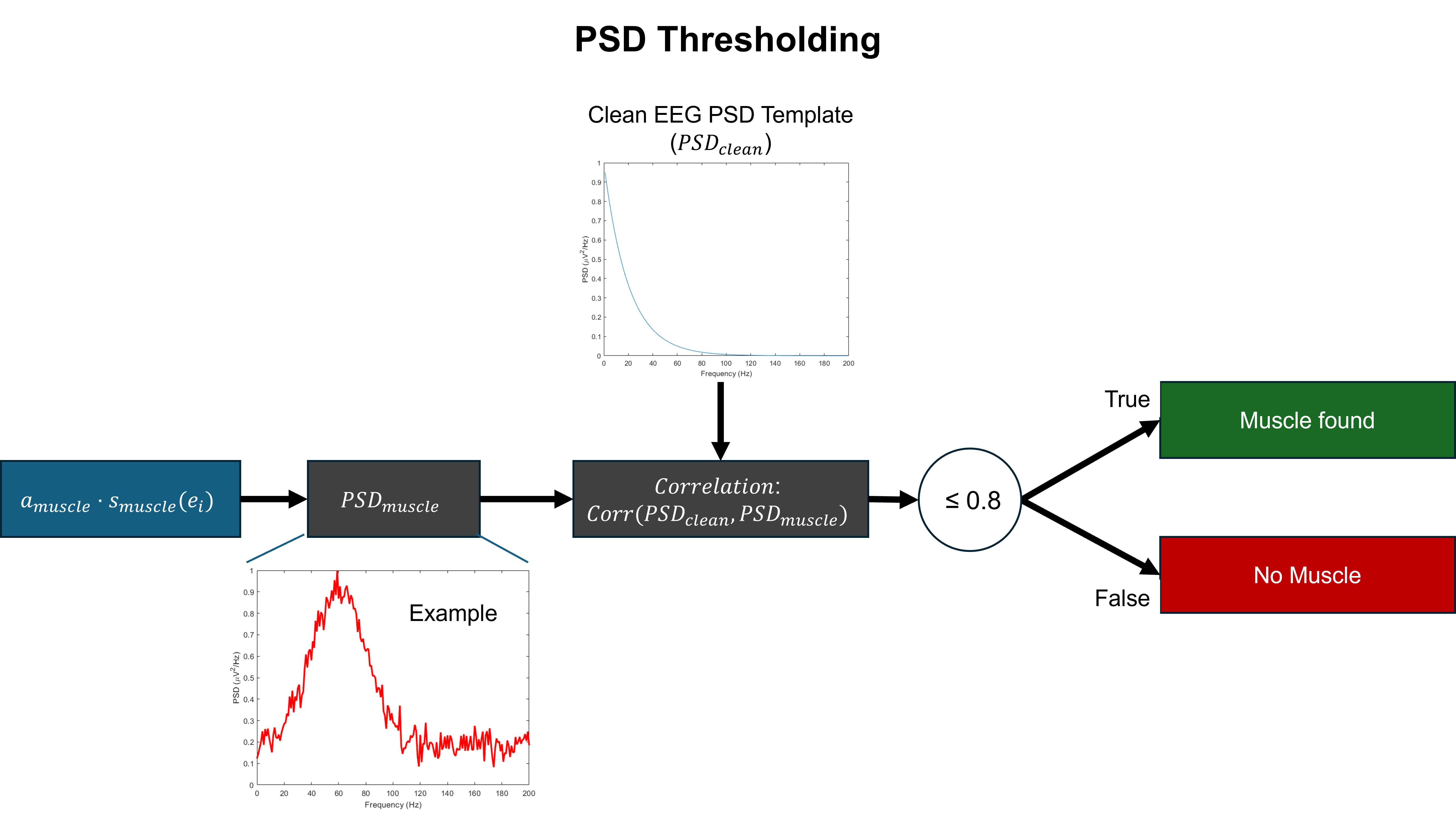
- Methodology Develops a novel artifact verification step using RMS and PSD thresholding criteria at the epoch level to ensure the physiological plausibility of generated contaminations, moving beyond simple ICA component injection.
- Biology Proposes a multi-label artifact classification paradigm that identifies multiple co-occurring artifact types (eye, muscle, heart, line, channel, other) within single EEG epochs, providing transparent contamination information for flexible preprocessing decisions.
主要结论
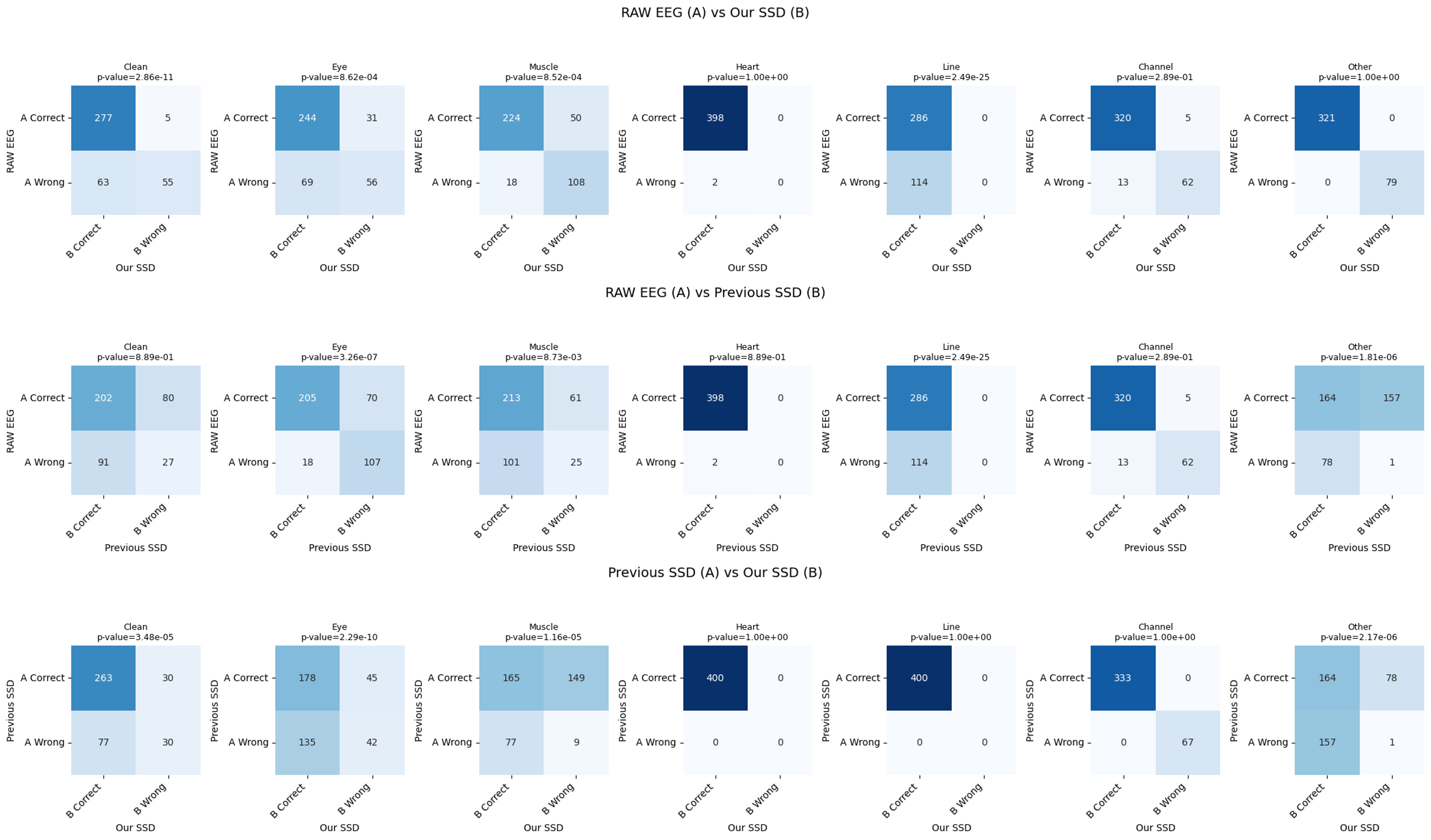
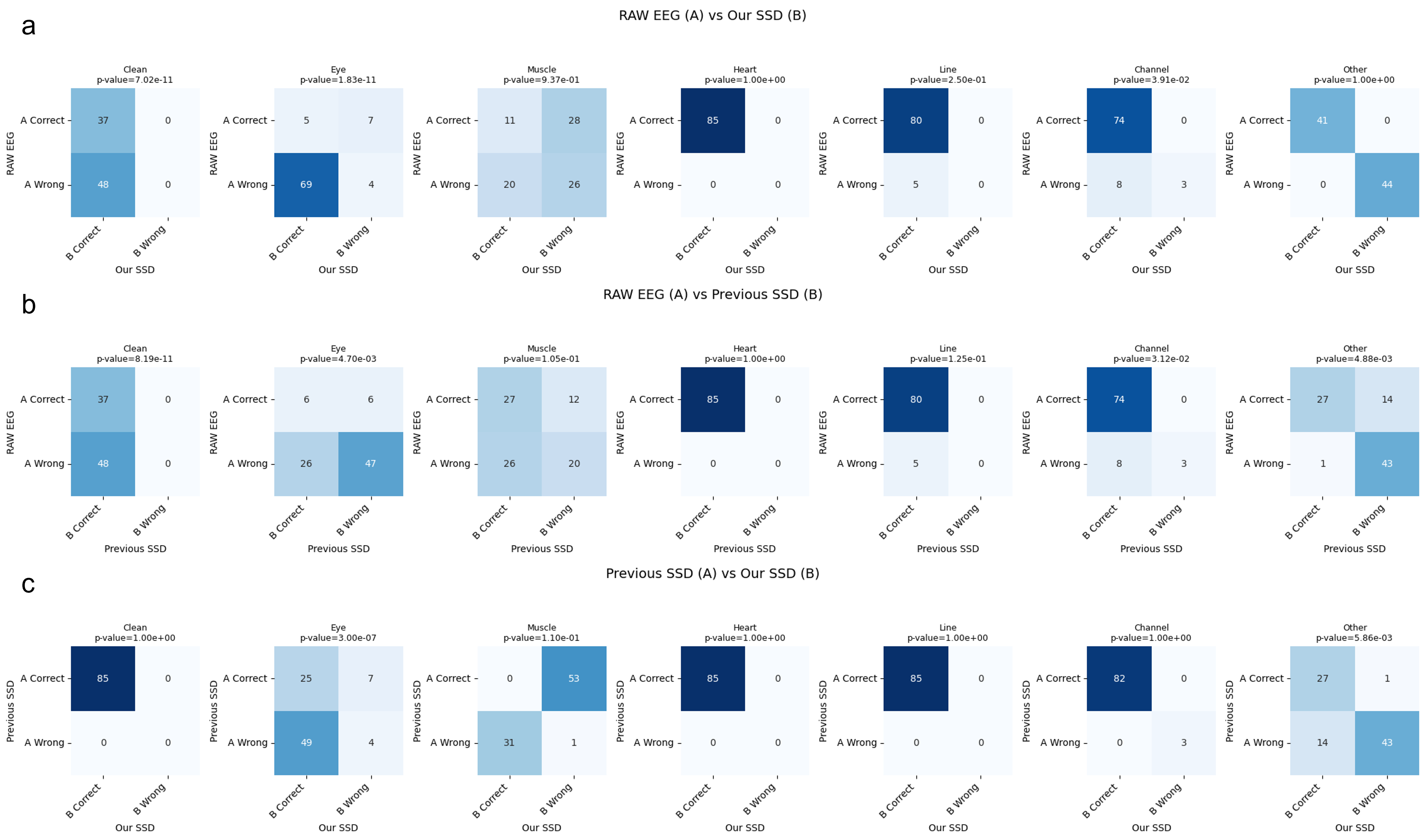
- SSDLabeler-trained classifiers achieved the highest overall accuracy (0.839) on motor execution test data, significantly outperforming raw EEG training (0.772, p<0.05 for Clean, Eye, and Line categories) and prior SSD methods (0.788).
- On instructed-noise session data, the proposed method achieved 0.812 accuracy, demonstrating strong generalization with significant improvements over raw EEG (0.618, p<0.05 for Clean, Eye, and Channel categories) and prior SSD (0.756).
- The framework successfully captures artifact co-occurrence, with the classifier showing balanced performance across most artifact types, though muscle artifact detection remained challenging (accuracy 0.605 vs. 0.785 for prior SSD).
摘要: EEG recordings are inherently contaminated by artifacts such as ocular, muscular, and environmental noise, which obscure neural activity and complicate preprocessing. Artifact classification offers advantages in stability and transparency, providing a viable alternative to ICA-based methods that enable flexible use alongside human inspections and across various applications. However, artifact classification is limited by its training data as it requires extensive manual labeling, which cannot fully cover the diversity of real-world EEG. Semi-synthetic data (SSD) methods have been proposed to address this limitation, but prior approaches typically injected single artifact types using ICA components or required separately recorded artifact signals, reducing both the realism of the generated data and the applicability of the method. To overcome these issues, we introduce SSDLabeler, a framework that generates realistic, annotated SSDs by decomposing real EEG with ICA, epoch-level artifact verification using RMS and PSD criteria, and reinjecting multiple artifact types into clean data. When applied to train a multi-label artifact classifier, it improved accuracy on raw EEG across diverse conditions compared to prior SSD and raw EEG training, establishing a scalable foundation for artifact handling that captures the co-occurrence and complexity of real EEG.