
Paper List
-
Developing the PsyCogMetrics™ AI Lab to Evaluate Large Language Models and Advance Cognitive Science
This paper addresses the critical gap between sophisticated LLM evaluation needs and the lack of accessible, scientifically rigorous platforms that in...
-
Equivalence of approximation by networks of single- and multi-spike neurons
This paper resolves the fundamental question of whether single-spike spiking neural networks (SNNs) are inherently less expressive than multi-spike SN...
-
The neuroscience of transformers
提出了Transformer架构与皮层柱微环路之间的新颖计算映射,连接了现代AI与神经科学。
-
Framing local structural identifiability and observability in terms of parameter-state symmetries
This paper addresses the core challenge of systematically determining which parameters and states in a mechanistic ODE model can be uniquely inferred ...
-
Leveraging Phytolith Research using Artificial Intelligence
This paper addresses the critical bottleneck in phytolith research by automating the labor-intensive manual microscopy process through a multimodal AI...
-
Neural network-based encoding in free-viewing fMRI with gaze-aware models
This paper addresses the core challenge of building computationally efficient and ecologically valid brain encoding models for naturalistic vision by ...
-
Scalable DNA Ternary Full Adder Enabled by a Competitive Blocking Circuit
This paper addresses the core bottleneck of carry information attenuation and limited computational scale in DNA binary adders by introducing a scalab...
-
ELISA: An Interpretable Hybrid Generative AI Agent for Expression-Grounded Discovery in Single-Cell Genomics
This paper addresses the critical bottleneck of translating high-dimensional single-cell transcriptomic data into interpretable biological hypotheses ...
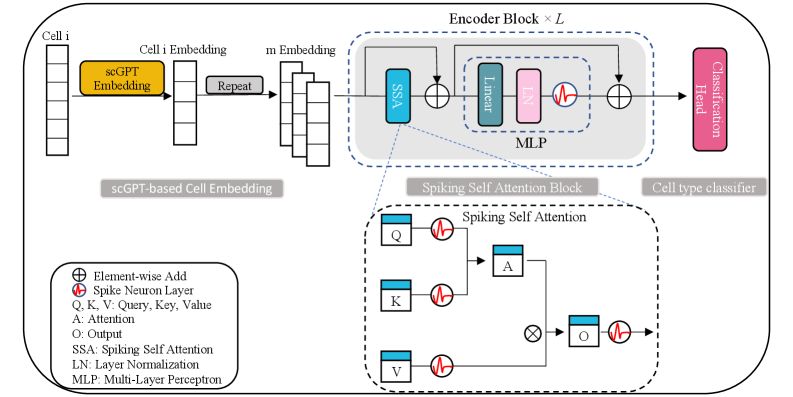
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
Department of Biomedical Informatics, Emory University | Department of Surgery, Duke University
30秒速读
IN SHORT: This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to identify previously unseen cell populations.
核心创新
- Methodology First integration of spiking neural networks with transformer architecture for single-cell analysis, using Leaky Integrate-and-Fire (LIF) neurons in a multi-head Spiking Self-Attention mechanism for energy-efficient computation.
- Methodology Novel two-step embedding expansion strategy: repeating cell embeddings along feature channels (default m=300) and temporal dimensions (default T=4) to enhance representation richness and training stability.
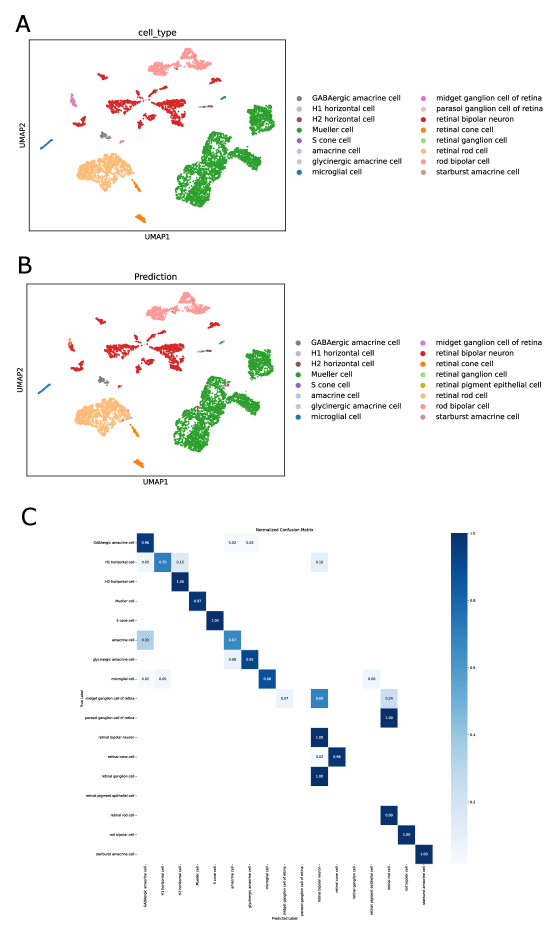
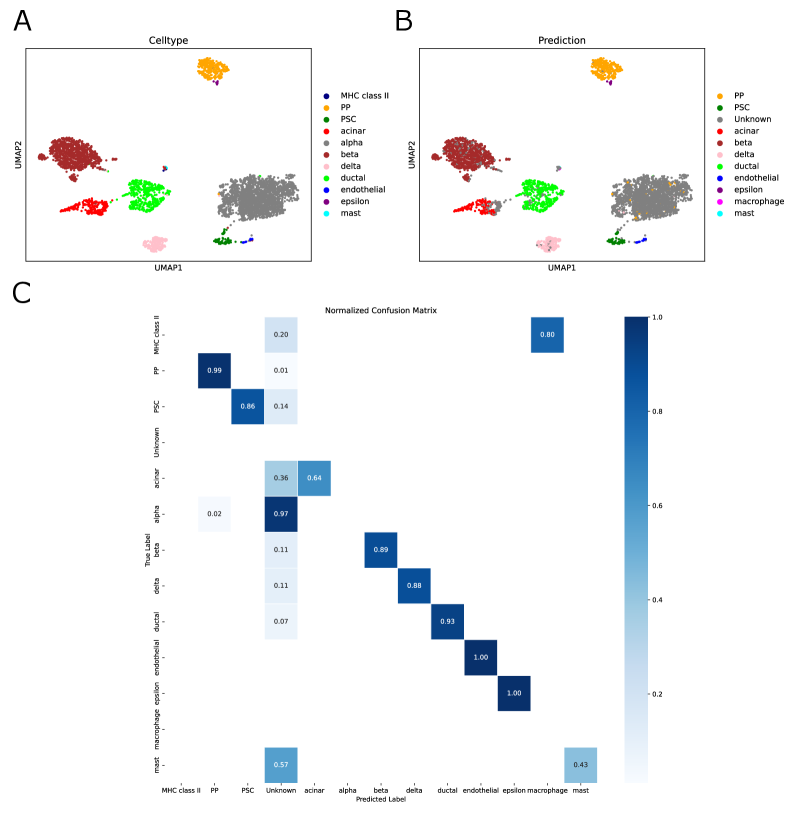
- Biology Confidence-based rejection mechanism that successfully identifies 97% of unseen 'alpha cells' as 'Unknown' in pancreas datasets, enabling robust detection of novel cell types absent from training data.
主要结论
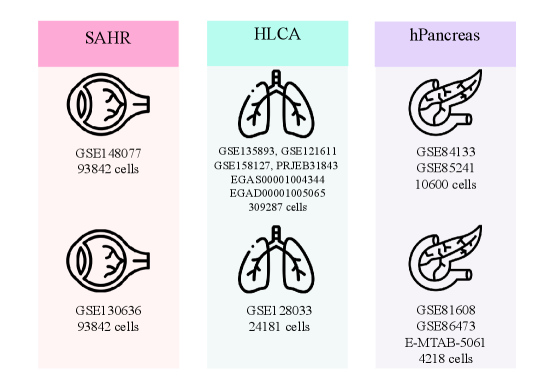
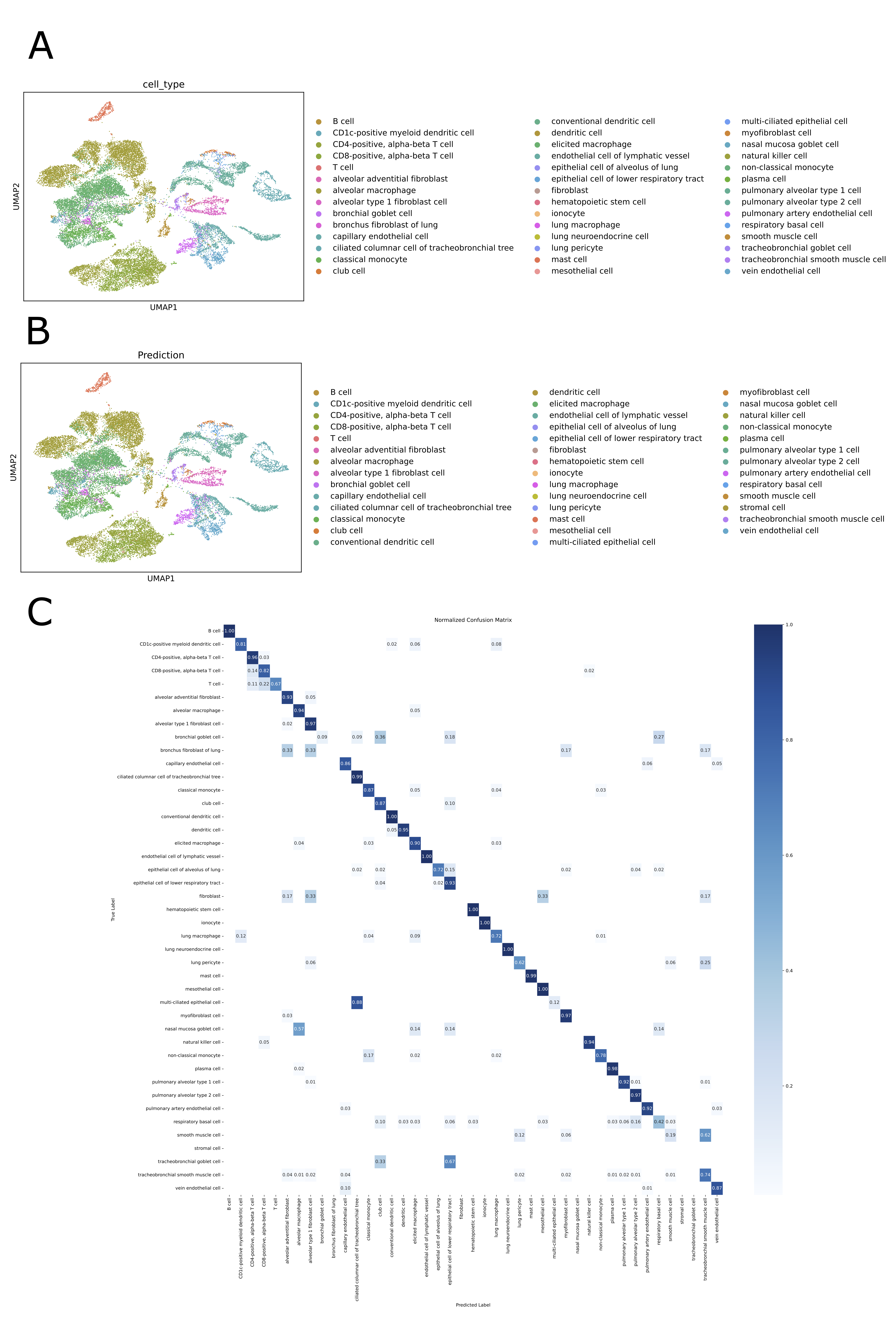
- SpikGPT achieves accuracy of 0.991 on SAHR dataset and 0.920 on HLCA dataset, outperforming or matching 8 benchmark methods including scGPT, CCA, and scPred.
- The model demonstrates superior robustness to batch effects, maintaining macro F1-score of 0.711 on heterogeneous HLCA data where traditional methods like SingleR drop to 0.207 F1-score.
- SpikGPT successfully identifies 97% of unseen 'alpha cells' as 'Unknown' using confidence thresholding (p<0.05), enabling reliable detection of novel cell populations.
摘要: Accurate and scalable cell type annotation remains a challenge in single-cell transcriptomics, especially when datasets exhibit strong batch effects or contain previously unseen cell populations. Here we introduce SpikGPT, a hybrid deep learning framework that integrates scGPT-derived cell embeddings with a spiking Transformer architecture to achieve efficient and robust annotation. scGPT provides biologically informed dense representations of each cell, which are further processed by a multi-head Spiking Self-Attention mechanism, energy-efficient feature extraction. Across multiple benchmark datasets, SpikGPT consistently matches or exceeds the performance of leading annotation tools. Notably, SpikGPT uniquely identifies unseen cell types by assigning low-confidence predictions to an 'Unknown' category, allowing accurate rejection of cell states absent from the training reference. Together, these results demonstrate that SpikGPT is a versatile and reliable annotation tool capable of generalizing across datasets, resolving complex cellular heterogeneity, and facilitating discovery of novel or disease-associated cell populations.