
Paper List
-
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to ide...
-
Unlocking hidden biomolecular conformational landscapes in diffusion models at inference time
This paper addresses the core challenge of efficiently and accurately sampling the conformational landscape of biomolecules from diffusion-based struc...
-
Personalized optimization of pediatric HD-tDCS for dose consistency and target engagement
This paper addresses the critical limitation of one-size-fits-all HD-tDCS protocols in pediatric populations by developing a personalized optimization...
-
Realistic Transition Paths for Large Biomolecular Systems: A Langevin Bridge Approach
This paper addresses the core challenge of generating physically realistic and computationally efficient transition paths between distinct protein con...
-
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the pe...
-
MoRSAIK: Sequence Motif Reactor Simulation, Analysis and Inference Kit in Python
This work addresses the computational bottleneck in simulating prebiotic RNA reactor dynamics by developing a Python package that tracks sequence moti...
-
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phyl...
-
EcoCast: A Spatio-Temporal Model for Continual Biodiversity and Climate Risk Forecasting
This paper addresses the critical bottleneck in conservation: the lack of timely, high-resolution, near-term forecasts of species distribution shifts ...
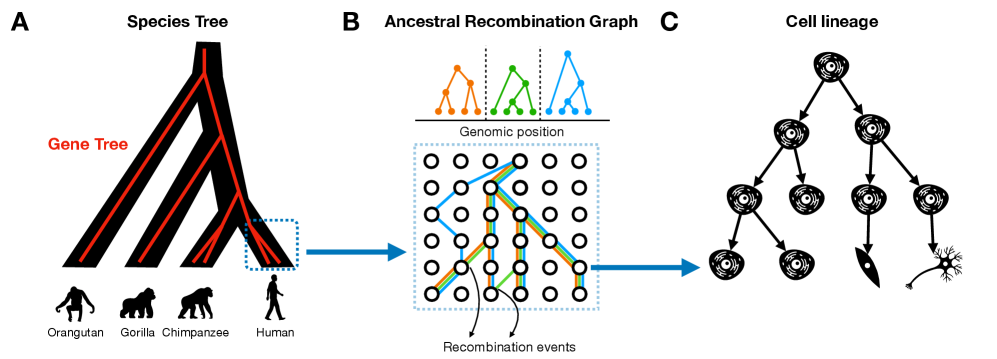
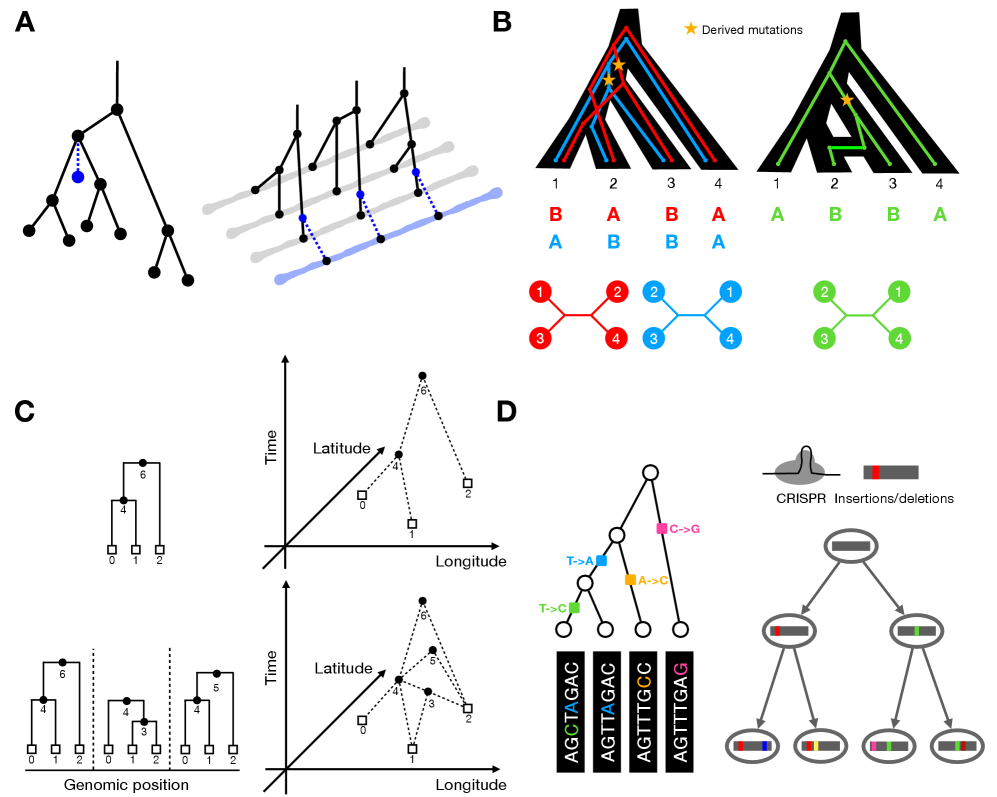
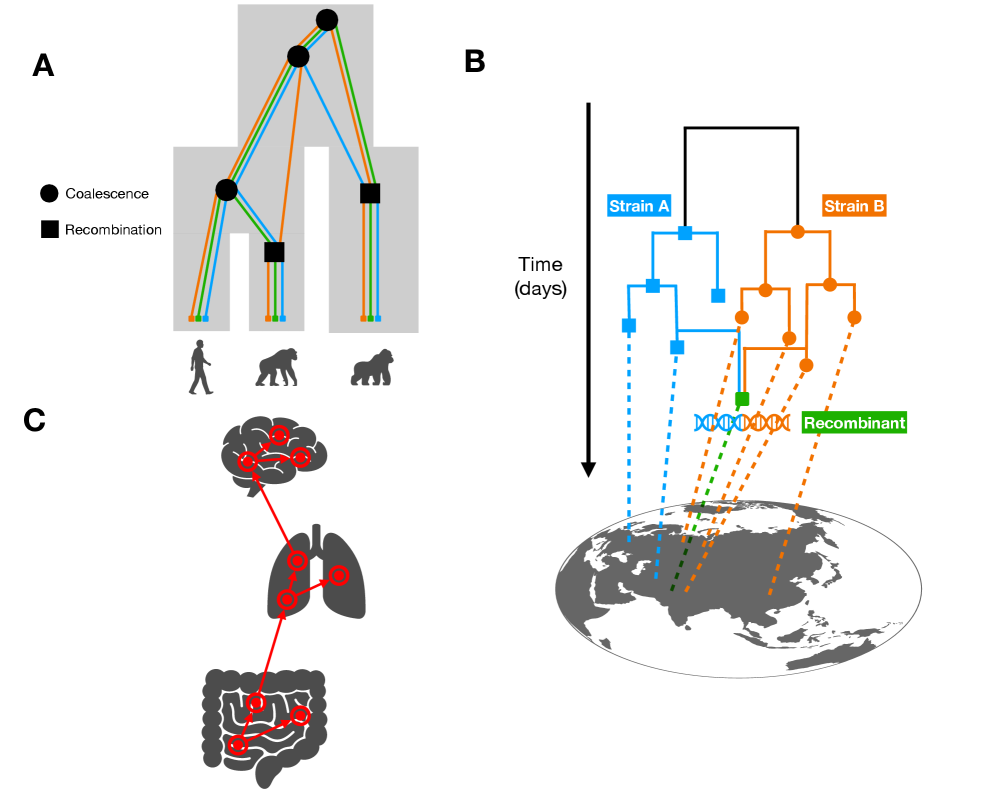
Tree Thinking in the Genomic Era: Unifying Models Across Cells, Populations, and Species
Stanford University | University of Oxford | University of California, Berkeley | Peking University | Guangzhou Medical University
30秒速读
IN SHORT: This paper addresses the fragmentation of tree-based inference methods across biological scales by identifying shared algorithmic principles and statistical challenges in phylogenetics, population genetics, and cell lineage tracing.
核心创新
- Methodology Identifies deep conceptual parallels between phylogenetic placement algorithms and ARG threading methods, demonstrating how phylogenetic placement generalizes to ARG reconstruction.
- Biology Shows that quartet-based network methods in phylogenetics and ABBA-BABA statistics in population genetics capture the same underlying signal of gene flow through asymmetric genealogical relationships.
- Methodology Demonstrates how ARG-based migration inference methods (e.g., GAIA, spacetrees) extend classical phylogeographic approaches by leveraging the full sequence of locally correlated genealogies along the genome.
主要结论
- Tree-based models provide a unified framework for ancestry inference across biological scales, with ARGs representing ~2.48 million SARS-CoV-2 genomes demonstrating pandemic-scale feasibility.
- Methodological parallels exist across domains: phylogenetic placement algorithms share core logic with ARG threading, and quartet-based methods in phylogenetics mirror ABBA-BABA statistics in population genetics for detecting gene flow.
- Current ARG inference algorithms remain constrained by simplifying assumptions (neutrality, panmixia, constant population size) and face challenges in uncertainty quantification, particularly for non-model species or limited sample sizes.
摘要: The ongoing explosion of genome sequence data is transforming how we reconstruct and understand the histories of biological systems. Across biological scales–from individual cells to populations and species–trees-based models provide a common framework for representing ancestry. Once limited to species phylogenetics, “tree thinking” now extends deeply to population genomics and cell biology, revealing the genealogical structure of genetic and phenotypic variation within and across organisms. Recently, there have been great methodological and computational advances on tree-based methods, including methods for inferring ancestral recombination graphs in populations, phylogenetic frameworks for comparative genomics, and lineage-tracing techniques in developmental and cancer biology. Despite differences in data types and biological contexts, these approaches share core statistical and algorithmic challenges: efficiently inferring branching histories from genomic information, integrating temporal and spatial signals, and connecting genealogical structures to evolutionary and functional processes. Recognizing these shared foundations opens opportunities for cross-fertilization between fields that are traditionally studied in isolation. By examining how tree-based methods are applied across cellular, population, and species scales, we identify the conceptual parallels that unite them and the distinct challenges that each domain presents. These comparisons offer new perspectives that can inform algorithmic innovations and lead to more powerful inference strategies across the full spectrum of biological systems.