
Paper List
-
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to ide...
-
Unlocking hidden biomolecular conformational landscapes in diffusion models at inference time
This paper addresses the core challenge of efficiently and accurately sampling the conformational landscape of biomolecules from diffusion-based struc...
-
Personalized optimization of pediatric HD-tDCS for dose consistency and target engagement
This paper addresses the critical limitation of one-size-fits-all HD-tDCS protocols in pediatric populations by developing a personalized optimization...
-
Realistic Transition Paths for Large Biomolecular Systems: A Langevin Bridge Approach
This paper addresses the core challenge of generating physically realistic and computationally efficient transition paths between distinct protein con...
-
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the pe...
-
MoRSAIK: Sequence Motif Reactor Simulation, Analysis and Inference Kit in Python
This work addresses the computational bottleneck in simulating prebiotic RNA reactor dynamics by developing a Python package that tracks sequence moti...
-
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phyl...
-
EcoCast: A Spatio-Temporal Model for Continual Biodiversity and Climate Risk Forecasting
This paper addresses the critical bottleneck in conservation: the lack of timely, high-resolution, near-term forecasts of species distribution shifts ...
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
Indiana University, Bloomington, IN 47405, USA
30秒速读
IN SHORT: This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phylogenetic distance functions from simulated data, bridging the gap between simple distance methods and complex model-based inference.
核心创新
- Methodology Introduces minimal, permutation-invariant neural architectures (Sequence networks S and Pair networks P) specifically designed to approximate phylogenetic distance functions, ensuring invariance to taxa ordering without costly data augmentation.
- Methodology Leverages theoretical results from metric embedding (Bourgain's theorem, Johnson-Lindenstrauss Lemma) to inform network design, explicitly linking embedding dimension to the number of taxa for efficient representation.
- Methodology Demonstrates how equivariant layers and attention mechanisms can be structured to handle both i.i.d. and spatially correlated sequence data (e.g., models with indels or rate variation), adapting to the complexity of the generative evolutionary model.
主要结论
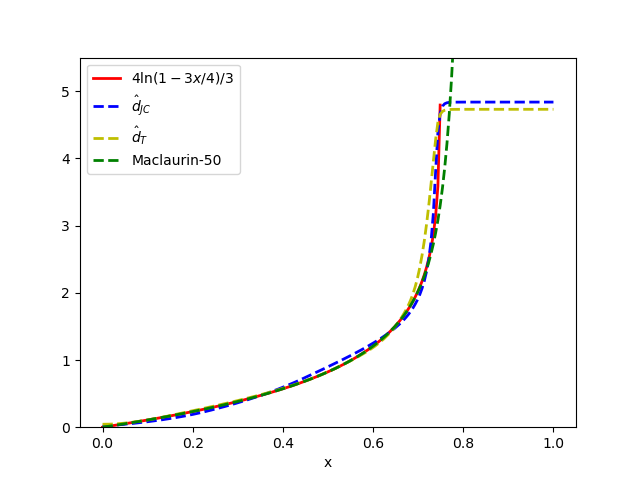
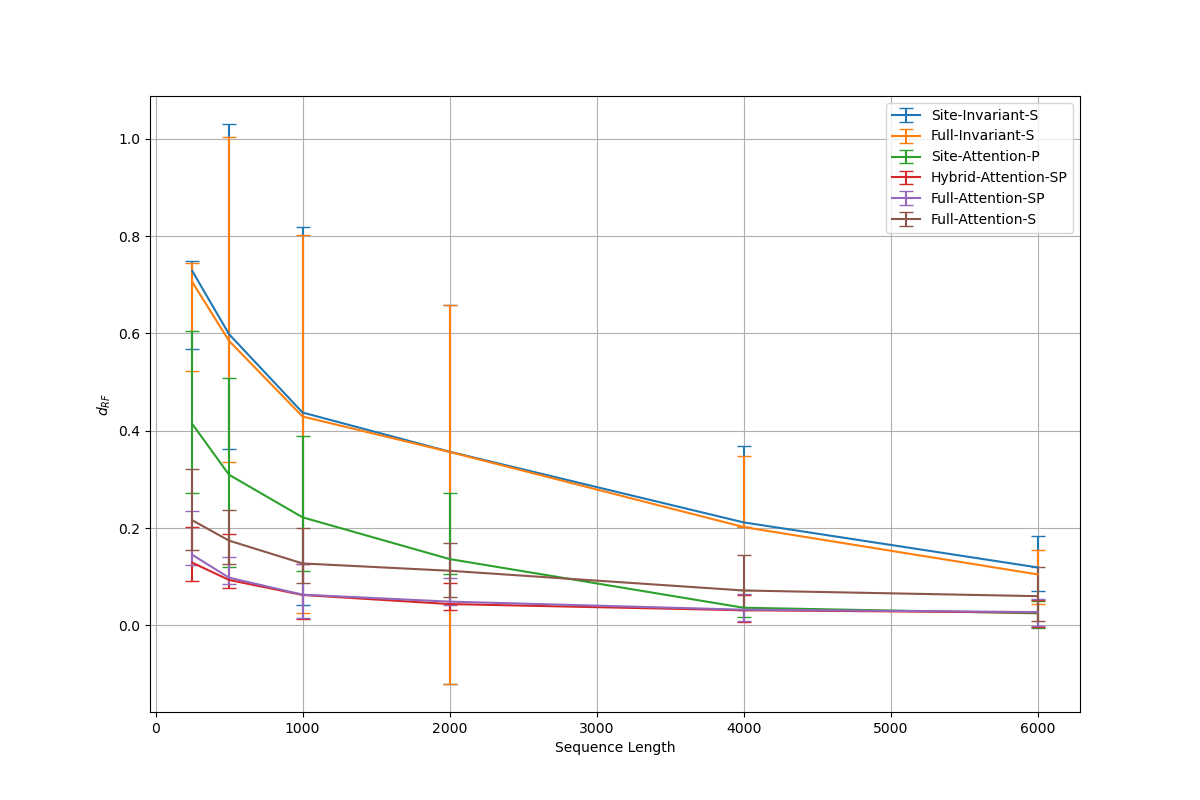
- The proposed minimal architectures (e.g., Sites-Invariant-S with ~7.6K parameters) achieve results comparable to state-of-the-art inference methods like IQ-TREE on simulated data under various models (JC, K2P, HKY, LG+indels), outperforming classic pairwise distance methods (d_H, d_JC, d_K2P) in most conditions.
- Architectures incorporating taxa-wise attention, while more memory-intensive, are necessary for complex evolutionary models with spatial dependencies; however, simpler networks suffice for simpler i.i.d. models, indicating an architecture-evolutionary model correspondence.
- Performance is highly sensitive to hyperparameters: validation error increases sharply with fewer than 4 attention heads or with hidden channel counts outside an optimal range (e.g., 32-128), aligning with theoretical requirements for learning graph-structured data.
摘要: Inferring the phylogenetic relationships among a sample of organisms is a fundamental problem in modern biology. While distance-based hierarchical clustering algorithms achieved early success on this task, these have been supplanted by Bayesian and maximum likelihood search procedures based on complex models of molecular evolution. In this work we describe minimal neural network architectures that can approximate classic phylogenetic distance functions and the properties required to learn distances under a variety of molecular evolutionary models. In contrast to model-based inference (and recently proposed model-free convolutional and transformer networks), these architectures have a small computational footprint and are scalable to large numbers of taxa and molecular characters. The learned distance functions generalize well and, given an appropriate training dataset, achieve results comparable to state-of-the art inference methods.