
Paper List
-
Ill-Conditioning in Dictionary-Based Dynamic-Equation Learning: A Systems Biology Case Study
This paper addresses the critical challenge of numerical ill-conditioning and multicollinearity in library-based sparse regression methods (e.g., SIND...
-
Hybrid eTFCE–GRF: Exact Cluster-Size Retrieval with Analytical pp-Values for Voxel-Based Morphometry
This paper addresses the computational bottleneck in voxel-based neuroimaging analysis by providing a method that delivers exact cluster-size retrieva...
-
abx_amr_simulator: A simulation environment for antibiotic prescribing policy optimization under antimicrobial resistance
This paper addresses the critical challenge of quantitatively evaluating antibiotic prescribing policies under realistic uncertainty and partial obser...
-
PesTwin: a biology-informed Digital Twin for enabling precision farming
This paper addresses the critical bottleneck in precision agriculture: the inability to accurately forecast pest outbreaks in real-time, leading to su...
-
Equivariant Asynchronous Diffusion: An Adaptive Denoising Schedule for Accelerated Molecular Conformation Generation
This paper addresses the core challenge of generating physically plausible 3D molecular structures by bridging the gap between autoregressive methods ...
-
Omics Data Discovery Agents
This paper addresses the core challenge of making published omics data computationally reusable by automating the extraction, quantification, and inte...
-
Single-cell directional sensing at ultra-low chemoattractant concentrations from extreme first-passage events
This work addresses the core challenge of how a cell can rapidly and accurately determine the direction of a chemoattractant source when the signal is...
-
SDSR: A Spectral Divide-and-Conquer Approach for Species Tree Reconstruction
This paper addresses the computational bottleneck in reconstructing species trees from thousands of species and multiple genes by introducing a scalab...
GOPHER: Optimization-based Phenotype Randomization for Genome-Wide Association Studies with Differential Privacy
Department of Biomedical Informatics & Data Science, Yale School of Medicine | Department of Technology and Operations Management, Harvard Business School | Department of Computer Science, Yale University
30秒速读
IN SHORT: This paper addresses the core challenge of balancing rigorous privacy protection with data utility when releasing full GWAS summary statistics, overcoming the limitations of prior methods that either add excessive noise or restrict output to a small subset of results.
核心创新
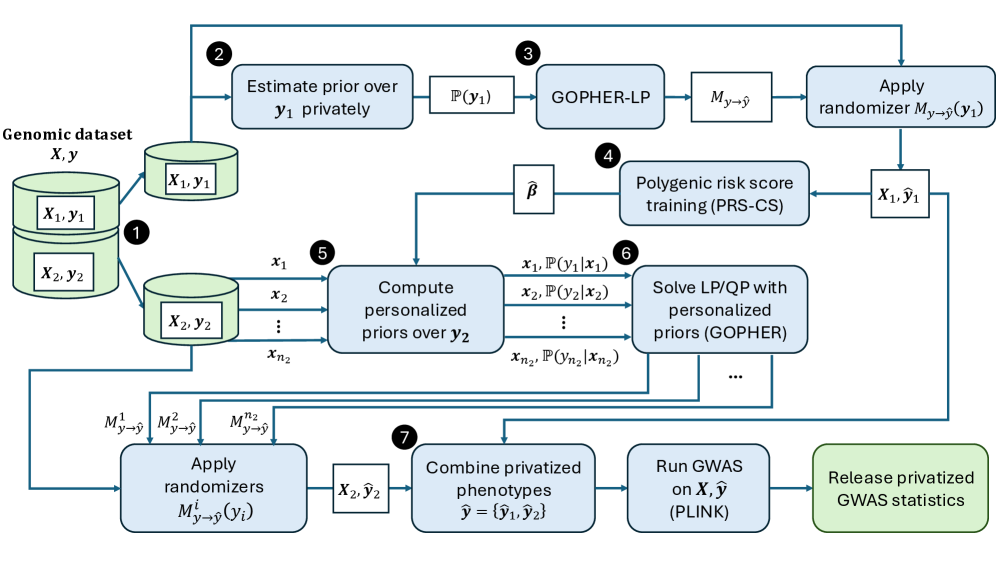
- Methodology Introduces an optimization-based phenotype randomization mechanism (GOPHER-LP) that directly minimizes expected error in GWAS statistics, formulated as a linear programming problem to enhance utility beyond baseline methods like randomized response.
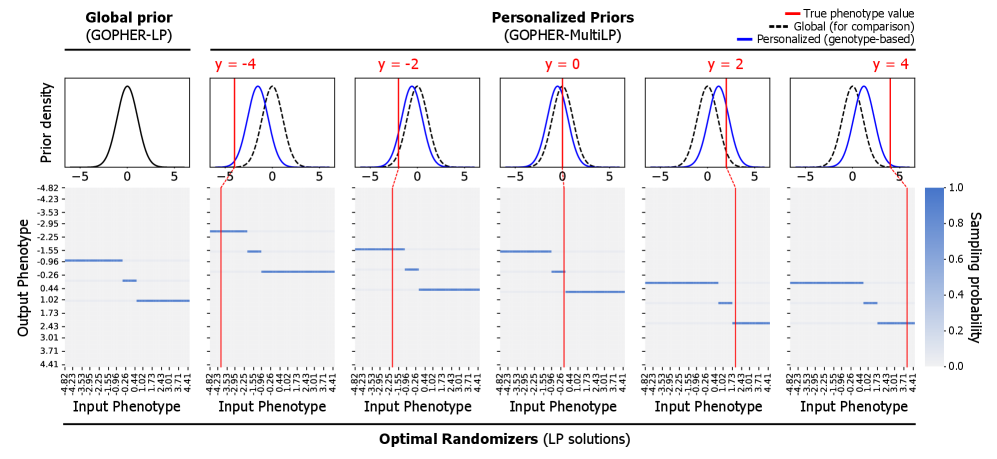
- Methodology Proposes GOPHER-MultiLP, which incorporates personalized priors derived from predictive models (e.g., polygenic risk scores) trained on a held-out subset, enabling sample-specific optimization that leverages genotype information to further reduce noise.
- Theory Adopts and extends the concept of phenotypic differential privacy (analogous to label DP), focusing protection on sensitive phenotypes while treating genotypes as public, providing a practical middle ground between full DP and unrestricted release.
主要结论
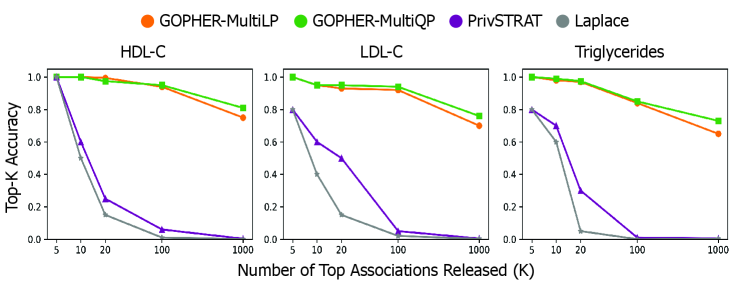
- The GOPHER framework enables the release of complete GWAS statistics (e.g., over 500,000 variants) with provable privacy guarantees, a significant scalability advance over prior methods limited to releasing only 3-5 top associations.
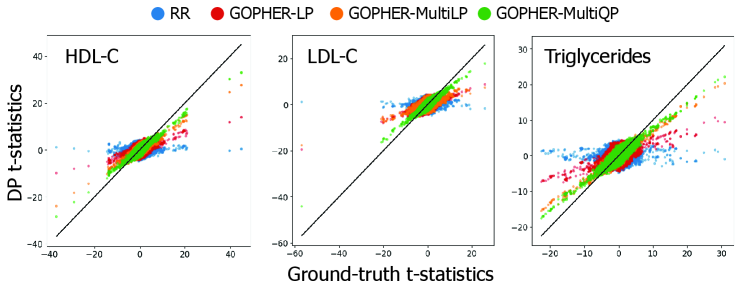
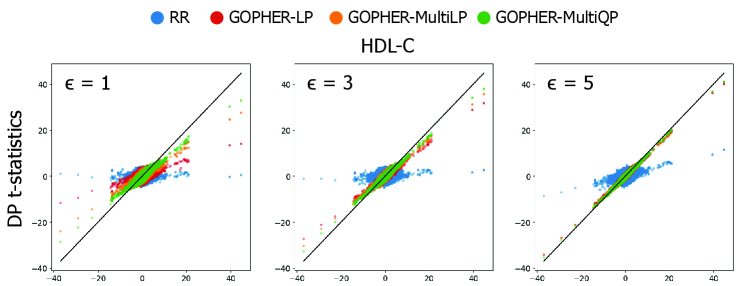
- Experiments on UK Biobank data (n=100,000) demonstrate that the mechanisms yield association statistics that accurately match non-private GWAS results while maintaining rigorous (ε, δ)-DP guarantees.
- The phenotype-randomization approach decouples the added noise from the number of genetic variants analyzed, addressing a fundamental scalability challenge not previously solved in the DP-GWAS literature.
摘要: Genome-wide association studies (GWAS) are an essential tool in biomedical research for identifying genetic factors linked to health and disease. However, publicly releasing GWAS summary statistics poses well-recognized privacy risks, including the potential to infer an individual’s participation in the study or to reveal sensitive phenotypic information (e.g., disease status). While differential privacy (DP) offers a rigorous mathematical framework for mitigating these risks, existing DP techniques for GWAS either introduce excessive noise or restrict the release to a limited set of results. In this work, we present practical DP mechanisms for releasing the complete set of genome-wide association statistics with privacy guarantees. We demonstrate the accuracy of the privacy-preserving statistics released by our mechanisms on a range of GWAS datasets from the UK Biobank, utilizing both real and simulated phenotypes. We introduce two key techniques to overcome the limitations of prior approaches: (1) an optimization-based randomization mechanism that directly minimizes the expected error in GWAS results to enhance utility, and (2) the use of personalized priors, derived from predictive models privately trained on a subset of the dataset, to enable sample-specific optimization which further reduces the amount of noise introduced by DP. Overall, our work provides practical tools for accurately releasing comprehensive GWAS results with provable protection of study participants.