
Paper List
-
Ill-Conditioning in Dictionary-Based Dynamic-Equation Learning: A Systems Biology Case Study
This paper addresses the critical challenge of numerical ill-conditioning and multicollinearity in library-based sparse regression methods (e.g., SIND...
-
Hybrid eTFCE–GRF: Exact Cluster-Size Retrieval with Analytical pp-Values for Voxel-Based Morphometry
This paper addresses the computational bottleneck in voxel-based neuroimaging analysis by providing a method that delivers exact cluster-size retrieva...
-
abx_amr_simulator: A simulation environment for antibiotic prescribing policy optimization under antimicrobial resistance
This paper addresses the critical challenge of quantitatively evaluating antibiotic prescribing policies under realistic uncertainty and partial obser...
-
PesTwin: a biology-informed Digital Twin for enabling precision farming
This paper addresses the critical bottleneck in precision agriculture: the inability to accurately forecast pest outbreaks in real-time, leading to su...
-
Equivariant Asynchronous Diffusion: An Adaptive Denoising Schedule for Accelerated Molecular Conformation Generation
This paper addresses the core challenge of generating physically plausible 3D molecular structures by bridging the gap between autoregressive methods ...
-
Omics Data Discovery Agents
This paper addresses the core challenge of making published omics data computationally reusable by automating the extraction, quantification, and inte...
-
Single-cell directional sensing at ultra-low chemoattractant concentrations from extreme first-passage events
This work addresses the core challenge of how a cell can rapidly and accurately determine the direction of a chemoattractant source when the signal is...
-
SDSR: A Spectral Divide-and-Conquer Approach for Species Tree Reconstruction
This paper addresses the computational bottleneck in reconstructing species trees from thousands of species and multiple genes by introducing a scalab...
Contrastive Deep Learning for Variant Detection in Wastewater Genomic Sequencing
Georgia State University, Atlanta, Georgia, USA
30秒速读
IN SHORT: This paper addresses the core challenge of detecting viral variants in wastewater sequencing data without reference genomes or labeled annotations, overcoming issues of high noise, low coverage, and fragmented reads.
核心创新
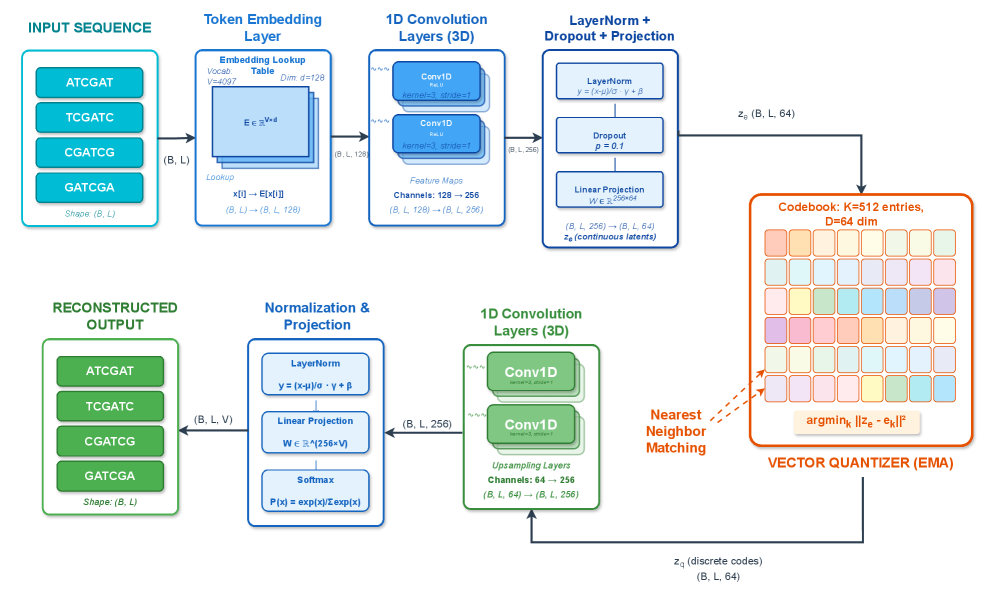
- Methodology First comprehensive application of VQ-VAE with EMA quantization to wastewater genomic surveillance, achieving 99.52% token-level reconstruction accuracy with 19.73% codebook utilization.
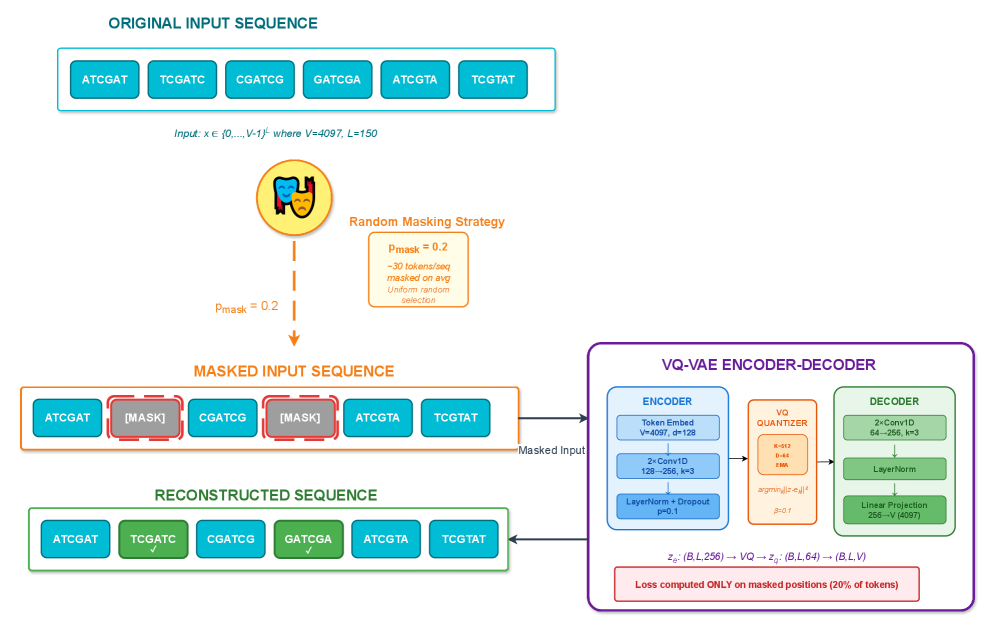
- Methodology Integration of masked reconstruction pretraining (BERT-style) maintaining ~95% accuracy under 20% token corruption, enabling robust inference with missing/low-quality data.
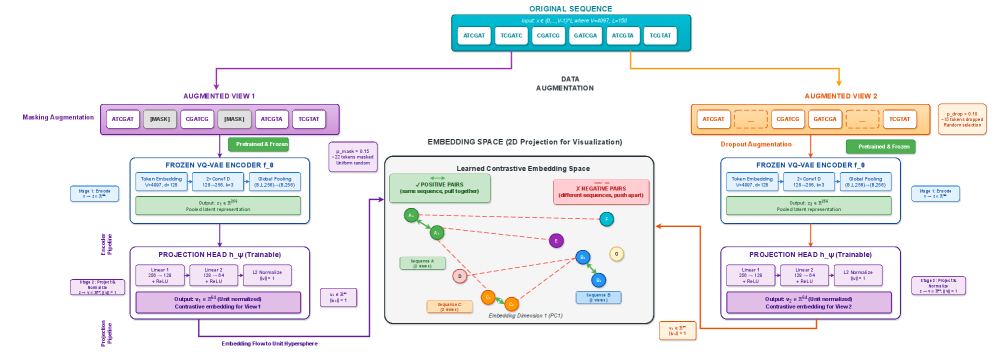
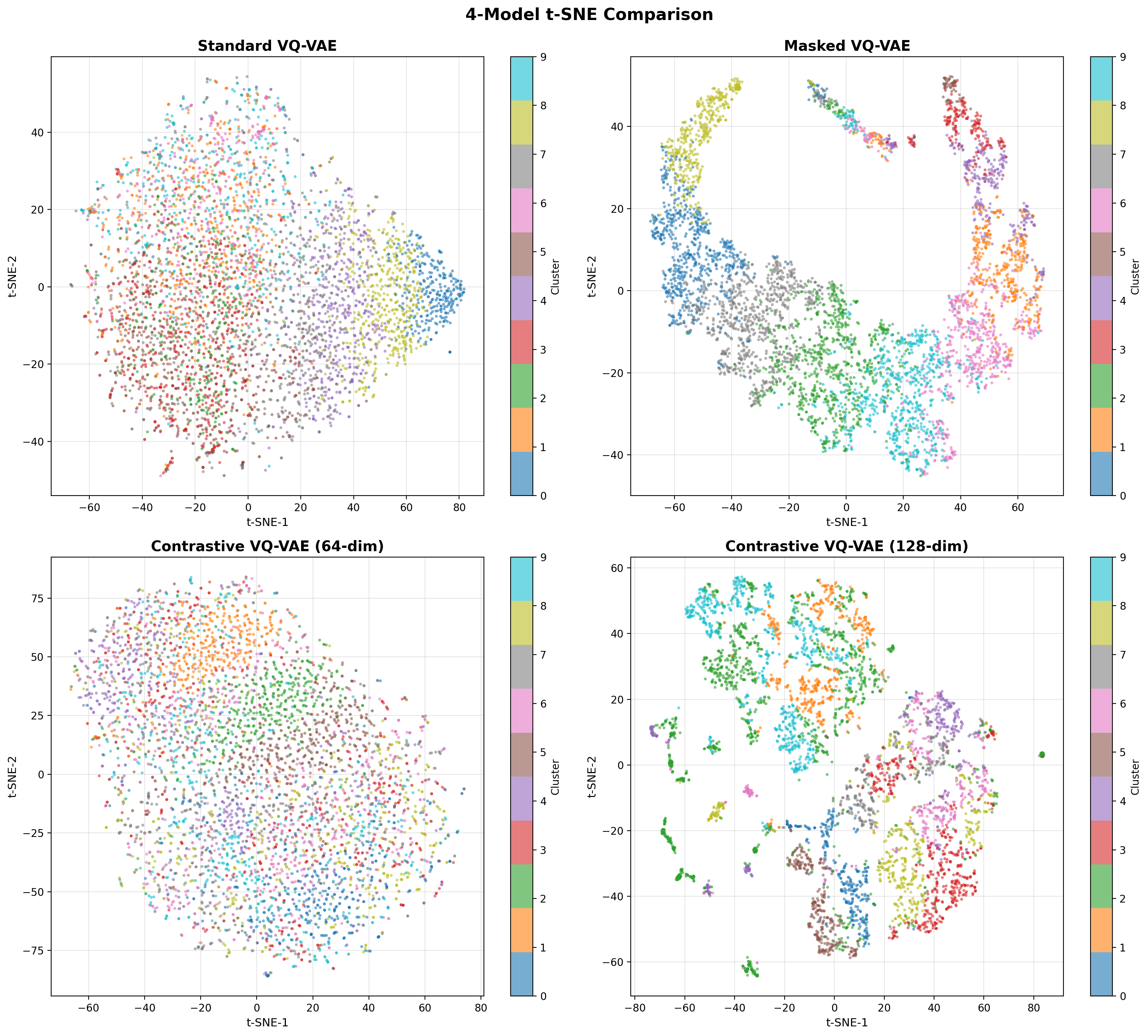
- Methodology Contrastive fine-tuning with varying embedding dimensions showing +35% (64-dim) and +42% (128-dim) Silhouette score improvements, establishing representation capacity impact on variant discrimination.
主要结论
- VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate on SARS-CoV-2 wastewater data with 100,000 reads.
- Contrastive fine-tuning improves clustering performance by +35% (0.31→0.42) with 64-dim embeddings and +42% (0.31→0.44) with 128-dim embeddings.
- The framework maintains efficient codebook utilization (19.73%, 101 of 512 codes active) while providing robust performance under data corruption.
摘要: Wastewater-based genomic surveillance has emerged as a powerful tool for population-level viral monitoring, offering comprehensive insights into circulating viral variants across entire communities. However, this approach faces significant computational challenges stemming from high sequencing noise, low viral coverage, fragmented reads, and the complete absence of labeled variant annotations. Traditional reference-based variant calling pipelines struggle with novel mutations and require extensive computational resources. We present a comprehensive framework for unsupervised viral variant detection using Vector-Quantized Variational Autoencoders (VQ-VAE) that learns discrete codebooks of genomic patterns from k-mer tokenized sequences without requiring reference genomes or variant labels. Our approach extends the base VQ-VAE architecture with masked reconstruction pretraining for robustness to missing data and contrastive learning for highly discriminative embeddings. Evaluated on SARS-CoV-2 wastewater sequencing data comprising approximately 100,000 reads, our VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate while maintaining 19.73% codebook utilization (101 of 512 codes active), demonstrating efficient discrete representation learning. Contrastive fine-tuning with different projection dimensions yields substantial clustering improvements: 64-dimensional embeddings achieve +35% Silhouette score improvement (0.31→0.42), while 128-dimensional embeddings achieve +42% improvement (0.31→0.44), clearly demonstrating the impact of embedding dimensionality on variant discrimination capability. Our reference-free framework provides a scalable, interpretable approach to genomic surveillance with direct applications to public health monitoring.