
Paper List
-
Autonomous Agents Coordinating Distributed Discovery Through Emergent Artifact Exchange
This paper addresses the fundamental limitation of current AI-assisted scientific research by enabling truly autonomous, decentralized investigation w...
-
D-MEM: Dopamine-Gated Agentic Memory via Reward Prediction Error Routing
This paper addresses the fundamental scalability bottleneck in LLM agentic memory systems: the O(N²) computational complexity and unbounded API token ...
-
Countershading coloration in blue shark skin emerges from hierarchically organized and spatially tuned photonic architectures inside skin denticles
This paper solves the core problem of how blue sharks achieve their striking dorsoventral countershading camouflage, revealing that coloration origina...
-
Human-like Object Grouping in Self-supervised Vision Transformers
This paper addresses the core challenge of quantifying how well self-supervised vision models capture human-like object grouping in natural scenes, br...
-
Hierarchical pp-Adic Framework for Gene Regulatory Networks: Theory and Stability Analysis
This paper addresses the core challenge of mathematically capturing the inherent hierarchical organization and multi-scale stability of gene regulator...
-
Towards unified brain-to-text decoding across speech production and perception
This paper addresses the core challenge of developing a unified brain-to-text decoding framework that works across both speech production and percepti...
-
Dual-Laws Model for a theory of artificial consciousness
This paper addresses the core challenge of developing a comprehensive, testable theory of consciousness that bridges biological and artificial systems...
-
Pulse desynchronization of neural populations by targeting the centroid of the limit cycle in phase space
This work addresses the core challenge of determining optimal pulse timing and intensity for desynchronizing pathological neural oscillations when the...
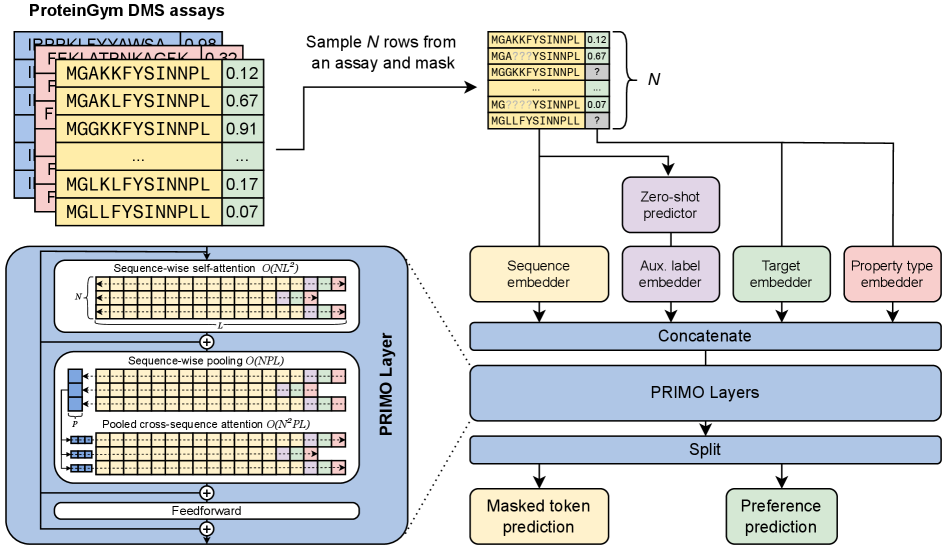
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.