
Paper List
-
Developing the PsyCogMetrics™ AI Lab to Evaluate Large Language Models and Advance Cognitive Science
This paper addresses the critical gap between sophisticated LLM evaluation needs and the lack of accessible, scientifically rigorous platforms that in...
-
Equivalence of approximation by networks of single- and multi-spike neurons
This paper resolves the fundamental question of whether single-spike spiking neural networks (SNNs) are inherently less expressive than multi-spike SN...
-
The neuroscience of transformers
提出了Transformer架构与皮层柱微环路之间的新颖计算映射,连接了现代AI与神经科学。
-
Framing local structural identifiability and observability in terms of parameter-state symmetries
This paper addresses the core challenge of systematically determining which parameters and states in a mechanistic ODE model can be uniquely inferred ...
-
Leveraging Phytolith Research using Artificial Intelligence
This paper addresses the critical bottleneck in phytolith research by automating the labor-intensive manual microscopy process through a multimodal AI...
-
Neural network-based encoding in free-viewing fMRI with gaze-aware models
This paper addresses the core challenge of building computationally efficient and ecologically valid brain encoding models for naturalistic vision by ...
-
Scalable DNA Ternary Full Adder Enabled by a Competitive Blocking Circuit
This paper addresses the core bottleneck of carry information attenuation and limited computational scale in DNA binary adders by introducing a scalab...
-
ELISA: An Interpretable Hybrid Generative AI Agent for Expression-Grounded Discovery in Single-Cell Genomics
This paper addresses the critical bottleneck of translating high-dimensional single-cell transcriptomic data into interpretable biological hypotheses ...
Training Dynamics of Learning 3D-Rotational Equivariance
Genentech Computational Sciences | New York University
30秒速读
IN SHORT: This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with data augmentation, by quantifying the speed and extent to which the latter learn 3D rotational symmetry.
核心创新
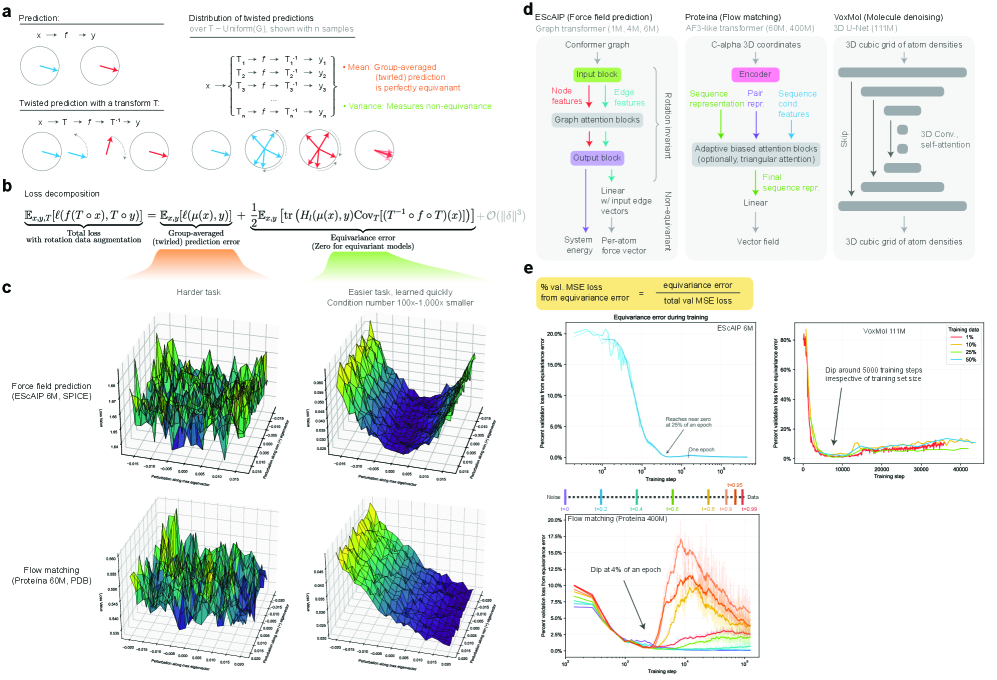
- Methodology Introduces a principled, generalizable framework to decompose total loss into a 'twirled prediction error' (ℒ_mean) and an 'equivariance error' (ℒ_equiv), enabling precise measurement of the percent of loss attributable to imperfect symmetry learning.
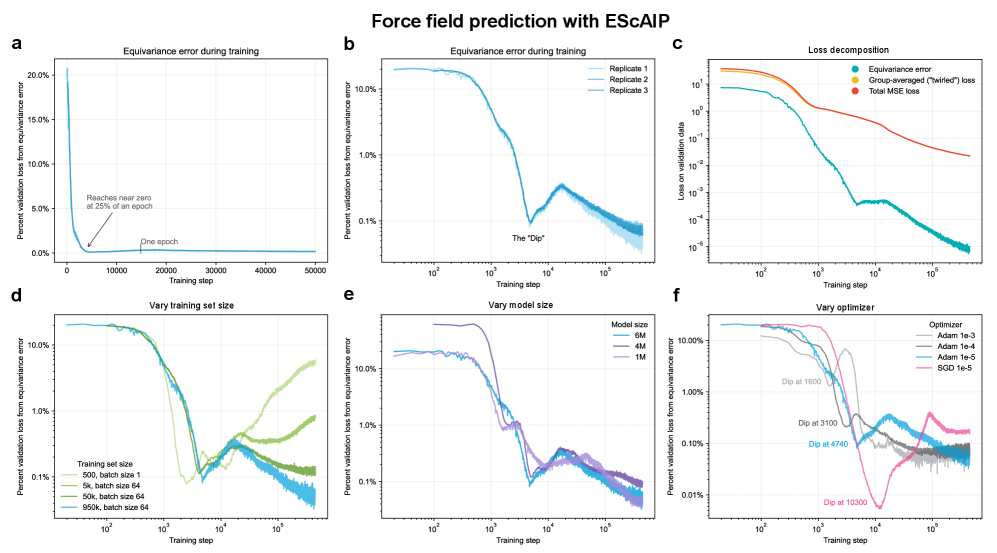
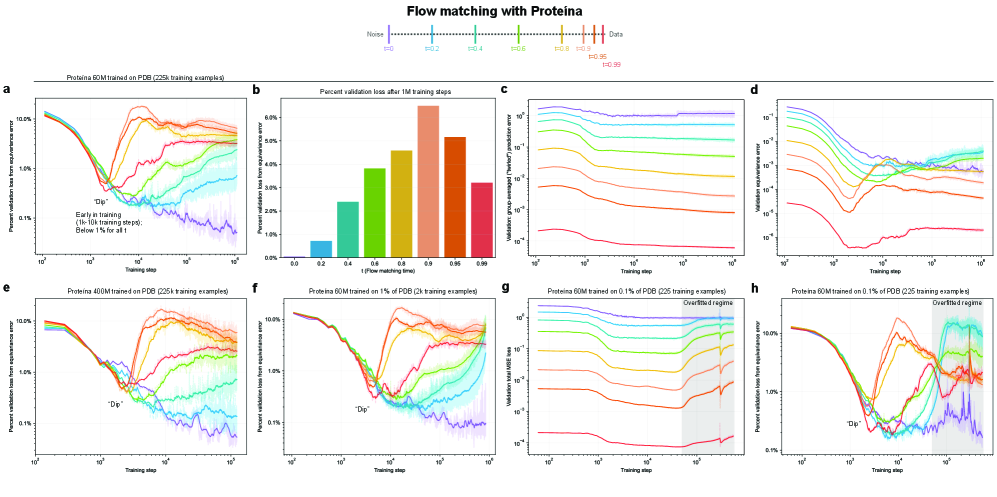
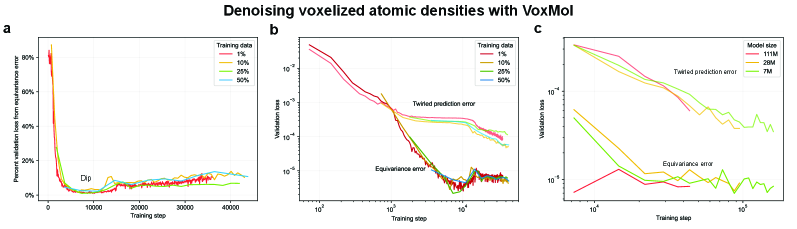
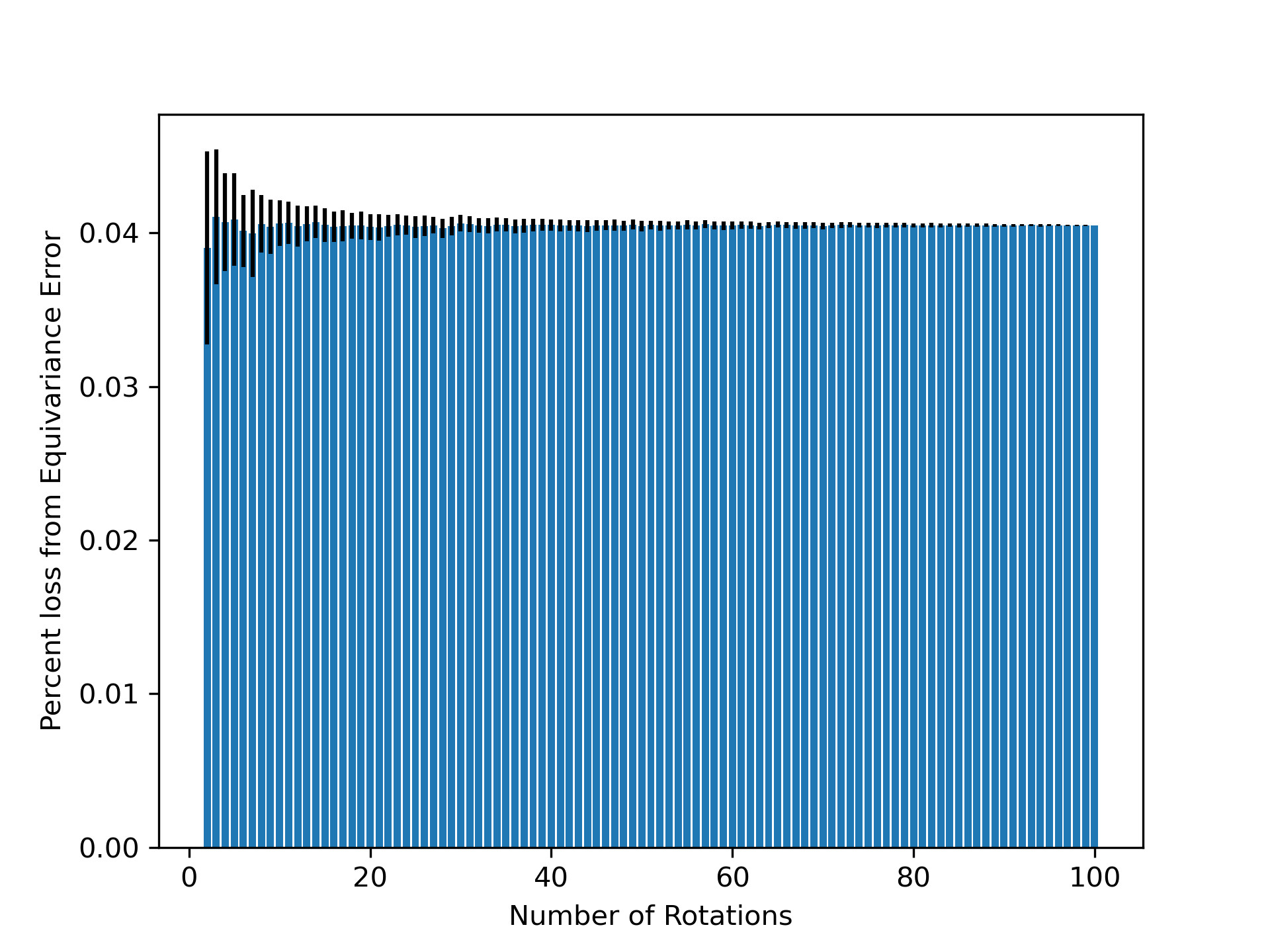
- Methodology Empirically demonstrates that models learning 3D-rotational equivariance via data augmentation achieve very low equivariance error (≤2% of total loss) remarkably quickly, within 1k-10k training steps, across diverse molecular tasks and model scales.
- Theory Provides theoretical and experimental evidence that learning equivariance is an easier task than the main prediction, characterized by a smoother and better-conditioned loss landscape (e.g., 1000x lower condition number for ℒ_equiv vs. ℒ_mean in force field prediction).
主要结论
- Non-equivariant models with data augmentation learn 3D rotational equivariance rapidly and effectively, reducing the equivariance error component to ≤2% of the total validation loss within the first 1k-10k training steps.
- The loss penalty for imperfect equivariance (ℒ_equiv) is small throughout training for 3D rotations, meaning the primary trade-off is the 'efficiency gap' (slower training/inference of equivariant models) rather than a significant accuracy penalty.
- The speed of learning equivariance is robust to model size (1M to 400M parameters), dataset size (500 to 1M samples), and optimizer choice, indicating it is a fundamental property of the learning task landscape.
摘要: While data augmentation is widely used to train symmetry-agnostic models, it remains unclear how quickly and effectively they learn to respect symmetries. We investigate this by deriving a principled measure of equivariance error that, for convex losses, calculates the percent of total loss attributable to imperfections in learned symmetry. We focus our empirical investigation to 3D-rotation equivariance on high-dimensional molecular tasks (flow matching, force field prediction, denoising voxels) and find that models reduce equivariance error quickly to ≤2% held-out loss within 1k-10k training steps, a result robust to model and dataset size. This happens because learning 3D-rotational equivariance is an easier learning task, with a smoother and better-conditioned loss landscape, than the main prediction task. For 3D rotations, the loss penalty for non-equivariant models is small throughout training, so they may achieve lower test loss than equivariant models per GPU-hour unless the equivariant “efficiency gap” is narrowed. We also experimentally and theoretically investigate the relationships between relative equivariance error, learning gradients, and model parameters.