
Paper List
-
Developing the PsyCogMetrics™ AI Lab to Evaluate Large Language Models and Advance Cognitive Science
This paper addresses the critical gap between sophisticated LLM evaluation needs and the lack of accessible, scientifically rigorous platforms that in...
-
Equivalence of approximation by networks of single- and multi-spike neurons
This paper resolves the fundamental question of whether single-spike spiking neural networks (SNNs) are inherently less expressive than multi-spike SN...
-
The neuroscience of transformers
提出了Transformer架构与皮层柱微环路之间的新颖计算映射,连接了现代AI与神经科学。
-
Framing local structural identifiability and observability in terms of parameter-state symmetries
This paper addresses the core challenge of systematically determining which parameters and states in a mechanistic ODE model can be uniquely inferred ...
-
Leveraging Phytolith Research using Artificial Intelligence
This paper addresses the critical bottleneck in phytolith research by automating the labor-intensive manual microscopy process through a multimodal AI...
-
Neural network-based encoding in free-viewing fMRI with gaze-aware models
This paper addresses the core challenge of building computationally efficient and ecologically valid brain encoding models for naturalistic vision by ...
-
Scalable DNA Ternary Full Adder Enabled by a Competitive Blocking Circuit
This paper addresses the core bottleneck of carry information attenuation and limited computational scale in DNA binary adders by introducing a scalab...
-
ELISA: An Interpretable Hybrid Generative AI Agent for Expression-Grounded Discovery in Single-Cell Genomics
This paper addresses the critical bottleneck of translating high-dimensional single-cell transcriptomic data into interpretable biological hypotheses ...
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
Indiana University, Bloomington, IN 47405, USA
30秒速读
IN SHORT: This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phylogenetic distance functions from simulated data, bridging the gap between simple distance methods and complex model-based inference.
核心创新
- Methodology Introduces minimal, permutation-invariant neural architectures (Sequence networks S and Pair networks P) specifically designed to approximate phylogenetic distance functions, ensuring invariance to taxa ordering without costly data augmentation.
- Methodology Leverages theoretical results from metric embedding (Bourgain's theorem, Johnson-Lindenstrauss Lemma) to inform network design, explicitly linking embedding dimension to the number of taxa for efficient representation.
- Methodology Demonstrates how equivariant layers and attention mechanisms can be structured to handle both i.i.d. and spatially correlated sequence data (e.g., models with indels or rate variation), adapting to the complexity of the generative evolutionary model.
主要结论
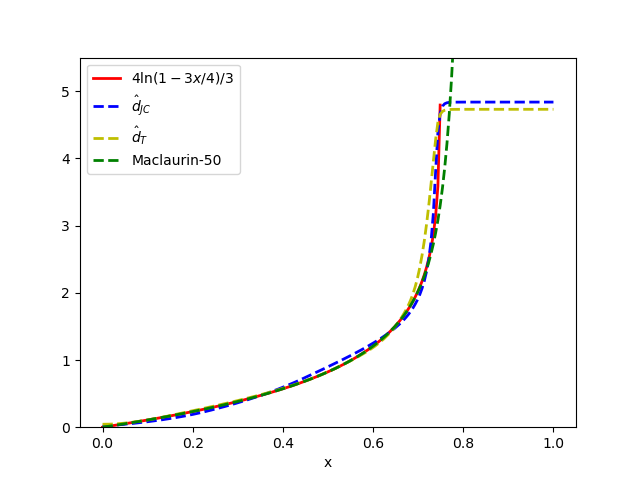
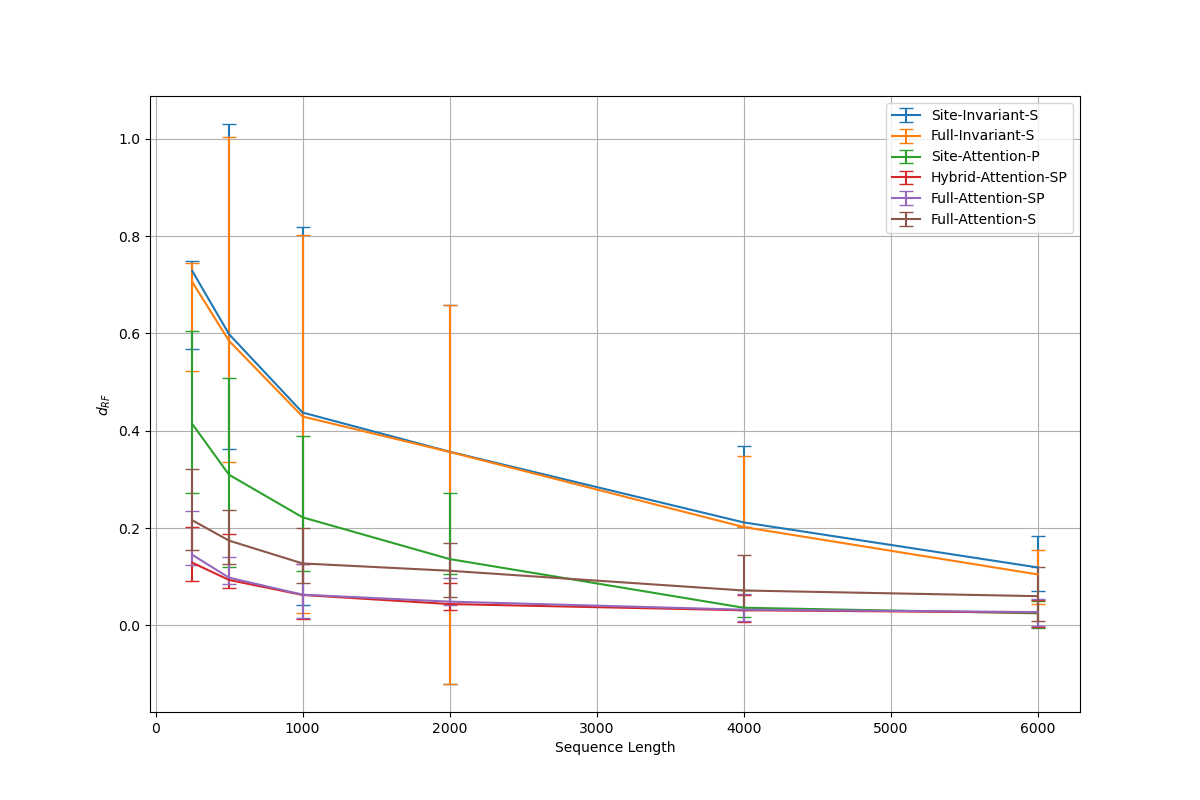
- The proposed minimal architectures (e.g., Sites-Invariant-S with ~7.6K parameters) achieve results comparable to state-of-the-art inference methods like IQ-TREE on simulated data under various models (JC, K2P, HKY, LG+indels), outperforming classic pairwise distance methods (d_H, d_JC, d_K2P) in most conditions.
- Architectures incorporating taxa-wise attention, while more memory-intensive, are necessary for complex evolutionary models with spatial dependencies; however, simpler networks suffice for simpler i.i.d. models, indicating an architecture-evolutionary model correspondence.
- Performance is highly sensitive to hyperparameters: validation error increases sharply with fewer than 4 attention heads or with hidden channel counts outside an optimal range (e.g., 32-128), aligning with theoretical requirements for learning graph-structured data.
摘要: Inferring the phylogenetic relationships among a sample of organisms is a fundamental problem in modern biology. While distance-based hierarchical clustering algorithms achieved early success on this task, these have been supplanted by Bayesian and maximum likelihood search procedures based on complex models of molecular evolution. In this work we describe minimal neural network architectures that can approximate classic phylogenetic distance functions and the properties required to learn distances under a variety of molecular evolutionary models. In contrast to model-based inference (and recently proposed model-free convolutional and transformer networks), these architectures have a small computational footprint and are scalable to large numbers of taxa and molecular characters. The learned distance functions generalize well and, given an appropriate training dataset, achieve results comparable to state-of-the art inference methods.