
Paper List
-
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to ide...
-
Unlocking hidden biomolecular conformational landscapes in diffusion models at inference time
This paper addresses the core challenge of efficiently and accurately sampling the conformational landscape of biomolecules from diffusion-based struc...
-
Personalized optimization of pediatric HD-tDCS for dose consistency and target engagement
This paper addresses the critical limitation of one-size-fits-all HD-tDCS protocols in pediatric populations by developing a personalized optimization...
-
Realistic Transition Paths for Large Biomolecular Systems: A Langevin Bridge Approach
This paper addresses the core challenge of generating physically realistic and computationally efficient transition paths between distinct protein con...
-
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the pe...
-
MoRSAIK: Sequence Motif Reactor Simulation, Analysis and Inference Kit in Python
This work addresses the computational bottleneck in simulating prebiotic RNA reactor dynamics by developing a Python package that tracks sequence moti...
-
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phyl...
-
EcoCast: A Spatio-Temporal Model for Continual Biodiversity and Climate Risk Forecasting
This paper addresses the critical bottleneck in conservation: the lack of timely, high-resolution, near-term forecasts of species distribution shifts ...
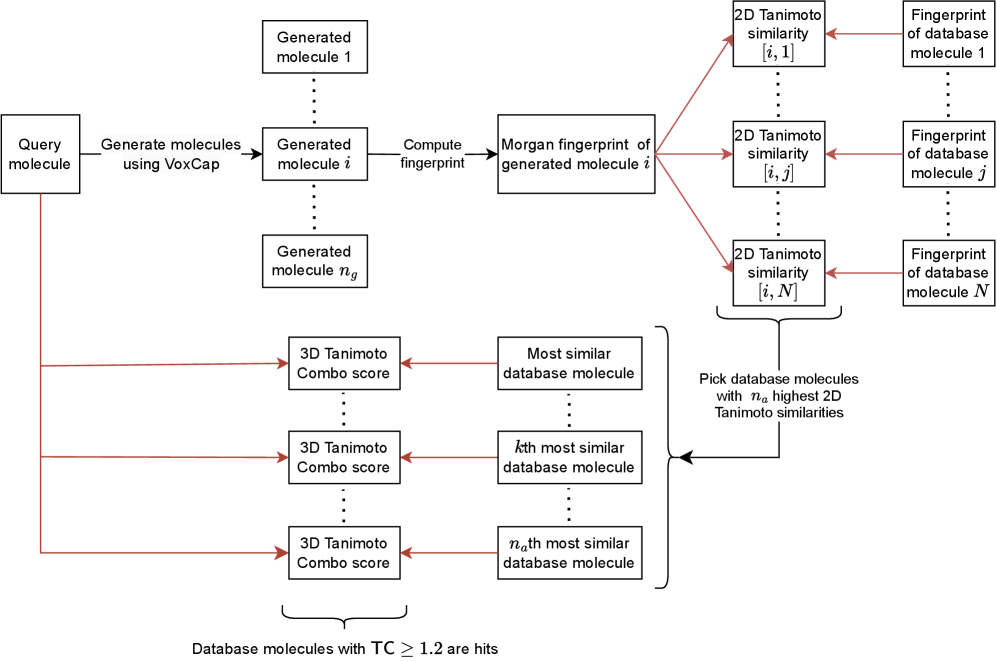
Pharmacophore-based design by learning on voxel grids
AIDD, Genentech
30秒速读
IN SHORT: This paper addresses the computational bottleneck and limited novelty in conventional pharmacophore-based virtual screening by introducing a voxel captioning method that generates novel molecules directly from 3D pharmacophore-shape profiles.
核心创新
- Methodology Proposes VoxCap, the first voxel captioning method for generating SMILES strings from voxelized 3D pharmacophore-shape profiles, bridging 3D structural information with 1D string generation.
- Methodology Introduces a 'fast search' workflow that reduces computational complexity from O(database size) to O(n_g × n_a), enabling screening of billion-compound libraries previously considered intractable.
- Biology Demonstrates superior performance in generating diverse, novel scaffolds with high pharmacophore-shape similarity (Tanimoto Combo score ≥1.2), addressing both in-distribution and out-of-distribution query molecules.
主要结论
- VoxCap generates significantly more hits than baseline methods, with median hits per query increasing from 0 (baseline) to 116.5 on GEOM-drugs and from 0 to 115 on ChEMBL (p<0.001).
- The model produces diverse scaffolds, with median unique scaffold hits of 55.5 (GEOM-drugs) and 72 (ChEMBL), compared to 0 for baselines and 7-8.5 for PGMG.
- The fast search workflow reduces computational requirements by orders of magnitude while maintaining hit rates, enabling practical screening of billion-compound libraries like Enamine Real (60B compounds).
摘要: Ligand-based drug discovery (LBDD) relies on making use of known binders to a protein target to find structurally diverse molecules similarly likely to bind. This process typically involves a brute force search of the known binder (query) against a molecular library using some metric of molecular similarity. One popular approach overlays the pharmacophore-shape profile of the known binder to 3D conformations enumerated for each of the library molecules, computes overlaps, and picks a set of diverse library molecules with high overlaps. While this virtual screening workflow has had considerable success in hit diversification, scaffold hopping, and patent busting, it scales poorly with library sizes and restricts candidate generation to existing library compounds. Leveraging recent advances in voxel-based generative modelling, we propose a pharmacophore-based generative model and workflows that address the scaling and fecundity issues of conventional pharmacophore-based virtual screening. We introduce VoxCap, a voxel captioning method for generating SMILES strings from voxelised molecular representations.We propose two workflows as practical use cases as well as benchmarks for pharmacophore-based generation: de-novo design, in which we aim to generate new molecules with high pharmacophore-shape similarities to query molecules, and fast search, which aims to combine generative design with a cheap 2D substructure similarity search for efficient hit identification. Our results show that VoxCap significantly outperforms previous methods in generating diverse de-novo hits. When combined with our fast search workflow, VoxCap reduces computational time by orders of magnitude while returning hits for all query molecules, enabling the search of large libraries that are intractable to search by brute force.