
Paper List
-
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to ide...
-
Unlocking hidden biomolecular conformational landscapes in diffusion models at inference time
This paper addresses the core challenge of efficiently and accurately sampling the conformational landscape of biomolecules from diffusion-based struc...
-
Personalized optimization of pediatric HD-tDCS for dose consistency and target engagement
This paper addresses the critical limitation of one-size-fits-all HD-tDCS protocols in pediatric populations by developing a personalized optimization...
-
Realistic Transition Paths for Large Biomolecular Systems: A Langevin Bridge Approach
This paper addresses the core challenge of generating physically realistic and computationally efficient transition paths between distinct protein con...
-
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the pe...
-
MoRSAIK: Sequence Motif Reactor Simulation, Analysis and Inference Kit in Python
This work addresses the computational bottleneck in simulating prebiotic RNA reactor dynamics by developing a Python package that tracks sequence moti...
-
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phyl...
-
EcoCast: A Spatio-Temporal Model for Continual Biodiversity and Climate Risk Forecasting
This paper addresses the critical bottleneck in conservation: the lack of timely, high-resolution, near-term forecasts of species distribution shifts ...
EnzyCLIP: A Cross-Attention Dual Encoder Framework with Contrastive Learning for Predicting Enzyme Kinetic Constants
Vellore Institute of Technology | BIT (Department of Computer Science) | BIT (Department of Bioengineering and Biotechnology)
30秒速读
IN SHORT: This paper addresses the core challenge of jointly predicting enzyme kinetic parameters (Kcat and Km) by modeling dynamic enzyme-substrate interactions through a multimodal contrastive learning framework.
核心创新
- Methodology Proposes a CLIP-inspired dual-encoder architecture with bidirectional cross-attention that dynamically models enzyme-substrate interactions, overcoming the limitation of separate processing in existing methods.
- Methodology Integrates contrastive learning (InfoNCE loss) with multi-task regression (Huber loss) to learn aligned multimodal representations while jointly predicting both Kcat and Km parameters.
- Biology Addresses the critical gap in existing literature that typically focuses on single parameter prediction (mainly Kcat) by providing a unified framework for joint prediction of both fundamental kinetic constants.
主要结论
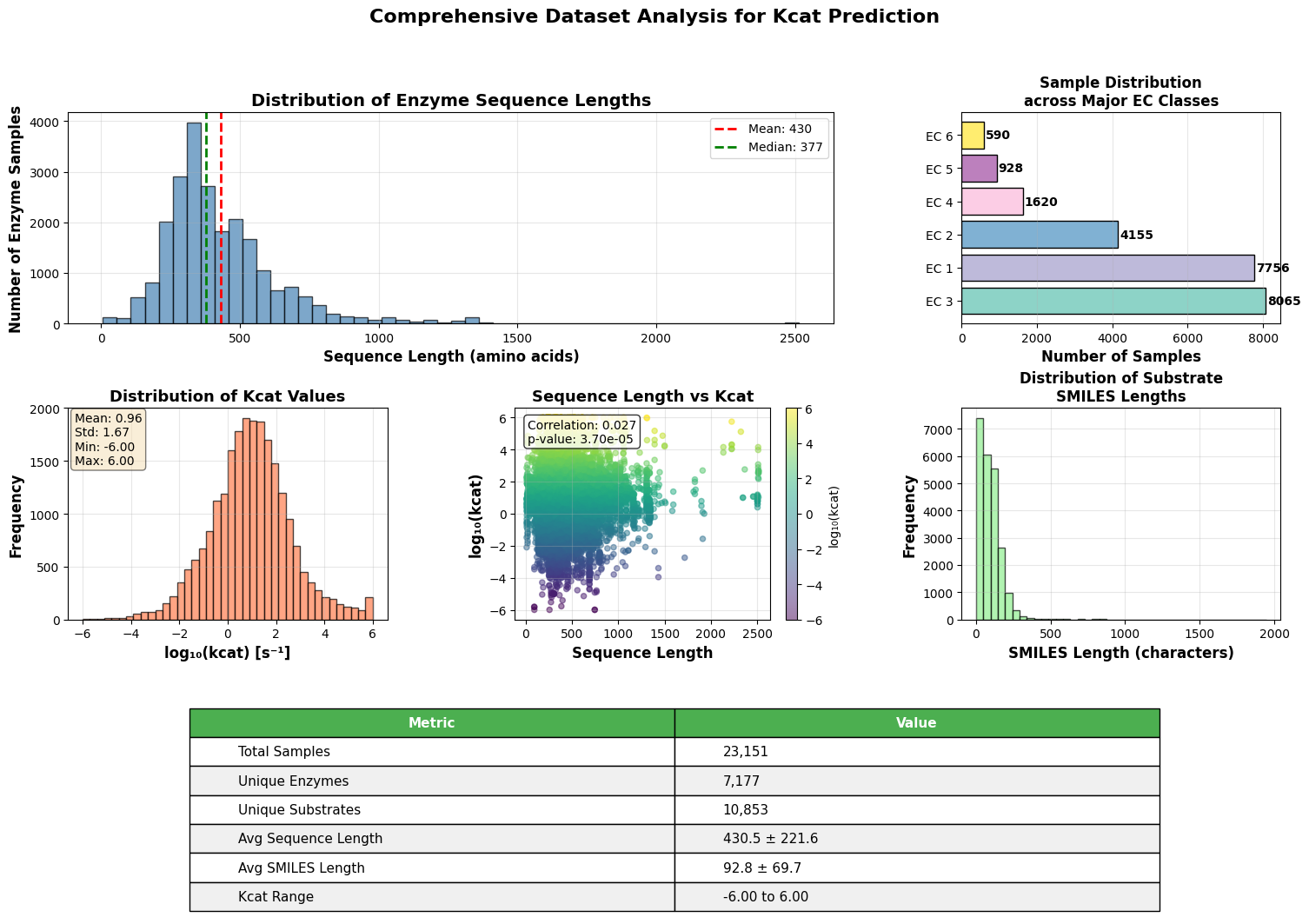
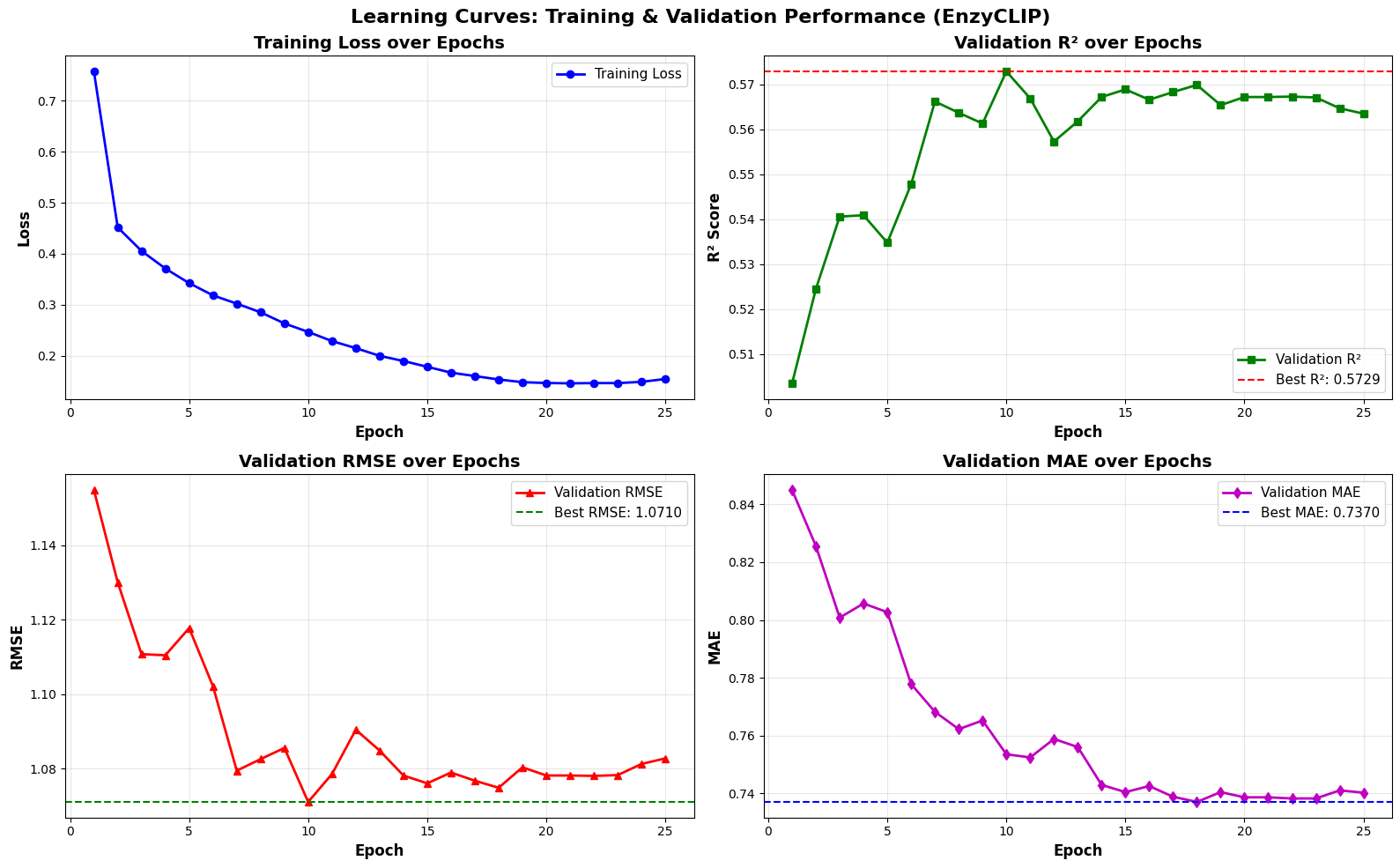
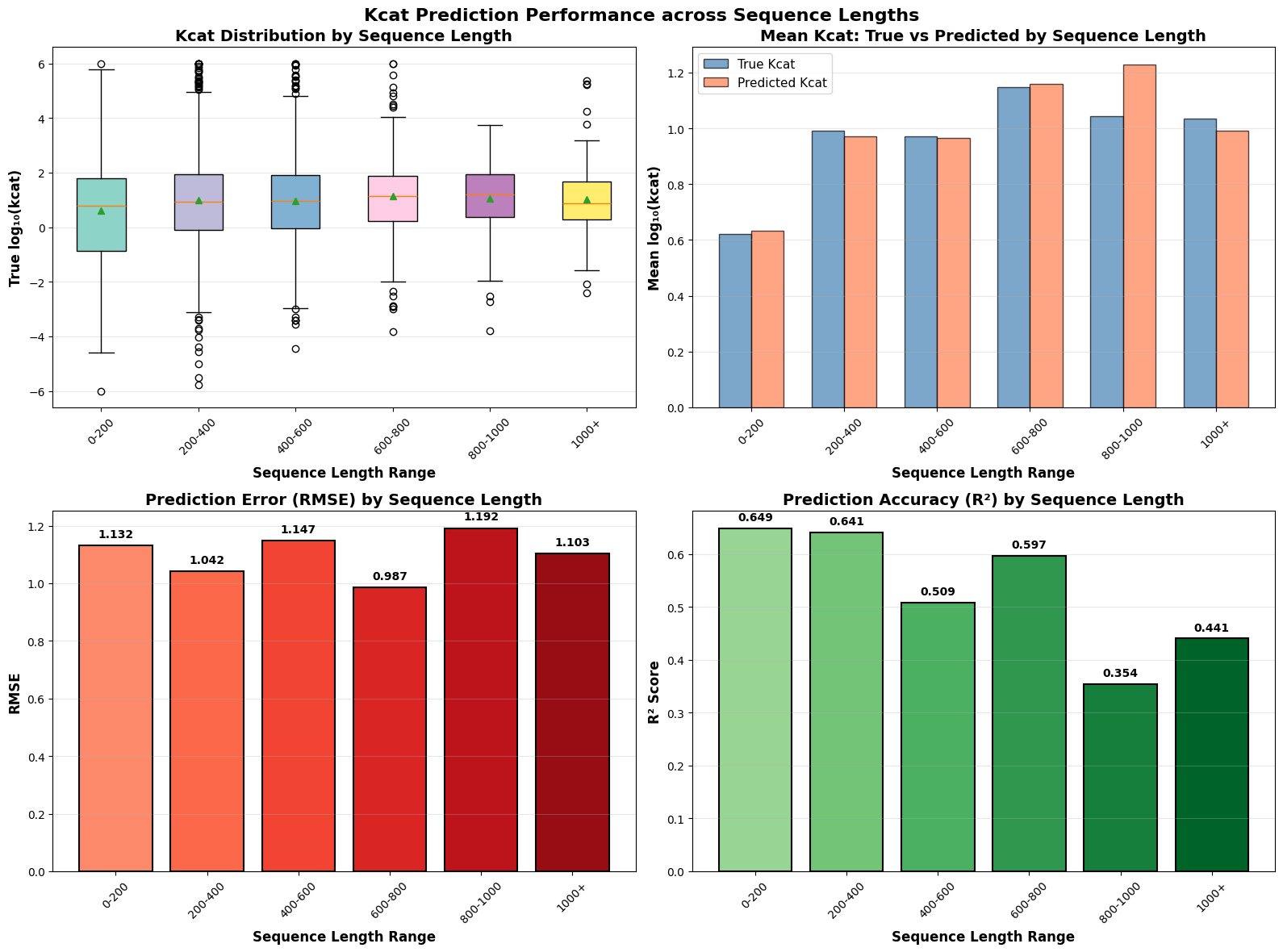
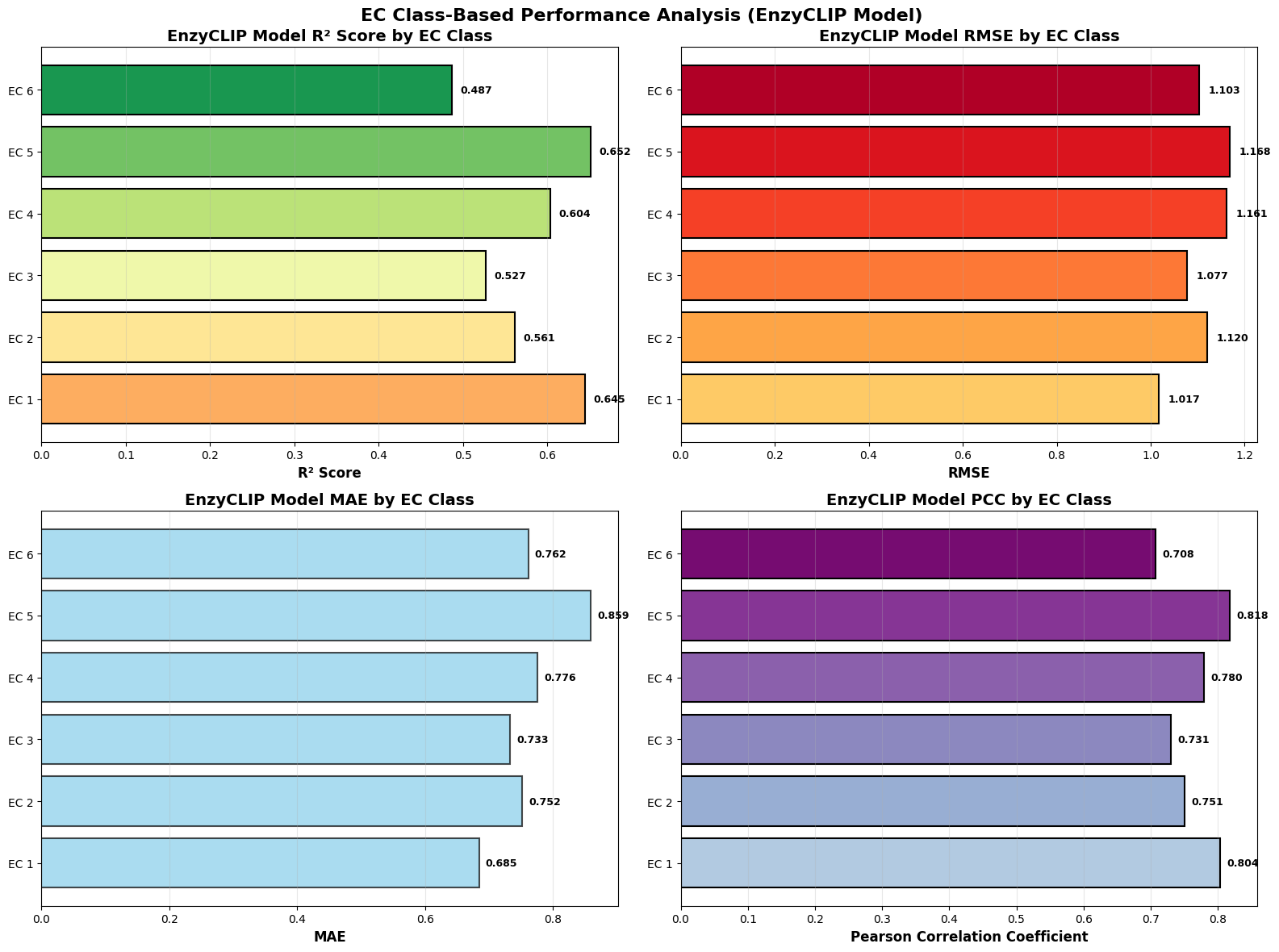
- EnzyCLIP achieves competitive baseline performance with R² scores of 0.593 for Kcat and 0.607 for Km prediction on the CatPred-DB dataset containing 23,151 Kcat and 41,174 Km measurements.
- The integration of contrastive learning with cross-attention mechanisms enables the model to capture biochemical relationships and substrate preferences even for unseen enzyme-substrate pairs.
- XGBoost ensemble methods applied to learned embeddings further improved Km prediction performance to R² = 0.61 while maintaining robust Kcat prediction capabilities.
摘要: Accurate prediction of enzyme kinetic parameters is crucial for drug discovery, metabolic engineering, and synthetic biology applications. Current computational approaches face limitations in capturing complex enzyme–substrate interactions and often focus on single parameters while neglecting the joint prediction of catalytic turnover numbers (Kcat) and Michaelis–Menten constants (Km). We present EnzyCLIP, a novel dual-encoder framework that leverages contrastive learning and cross-attention mechanisms to predict enzyme kinetic parameters from protein sequences and substrate molecular structures. Our approach integrates ESM-2 protein language model embeddings with ChemBERTa chemical representations through a CLIP-inspired architecture enhanced with bidirectional cross-attention for dynamic enzyme–substrate interaction modeling. EnzyCLIP combines InfoNCE contrastive loss with Huber regression loss to learn aligned multimodal representations while predicting log10-transformed kinetic parameters. EnzyCLIP is trained on the CatPred-DB database containing 23,151 Kcat and 41,174 Km experimentally validated measurements, and achieved competitive baseline performance with R2 scores of 0.593 for Kcat and 0.607 for Km prediction. XGBoost ensemble methods on learned embeddings further improved Km prediction (R2 = 0.61) while maintaining robust Kcat performance.