
Paper List
-
STAR-GO: Improving Protein Function Prediction by Learning to Hierarchically Integrate Ontology-Informed Semantic Embeddings
This paper addresses the core challenge of generalizing protein function prediction to unseen or newly introduced Gene Ontology (GO) terms by overcomi...
-
Incorporating indel channels into average-case analysis of seed-chain-extend
This paper addresses the core pain point of bridging the theoretical gap for the widely used seed-chain-extend heuristic by providing the first rigoro...
-
Competition, stability, and functionality in excitatory-inhibitory neural circuits
This paper addresses the core challenge of extending interpretable energy-based frameworks to biologically realistic asymmetric neural networks, where...
-
Enhancing Clinical Note Generation with ICD-10, Clinical Ontology Knowledge Graphs, and Chain-of-Thought Prompting Using GPT-4
This paper addresses the core challenge of generating accurate and clinically relevant patient notes from sparse inputs (ICD codes and basic demograph...
-
Learning From Limited Data and Feedback for Cell Culture Process Monitoring: A Comparative Study
This paper addresses the core challenge of developing accurate real-time bioprocess monitoring soft sensors under severe data constraints: limited his...
-
Cell-cell communication inference and analysis: biological mechanisms, computational approaches, and future opportunities
This review addresses the critical need for a systematic framework to navigate the rapidly expanding landscape of computational methods for inferring ...
-
Generating a Contact Matrix for Aged Care Settings in Australia: an agent-based model study
This study addresses the critical gap in understanding heterogeneous contact patterns within aged care facilities, where existing population-level con...
-
Emergent Spatiotemporal Dynamics in Large-Scale Brain Networks with Next Generation Neural Mass Models
This work addresses the core challenge of understanding how complex, brain-wide spatiotemporal patterns emerge from the interaction of biophysically d...
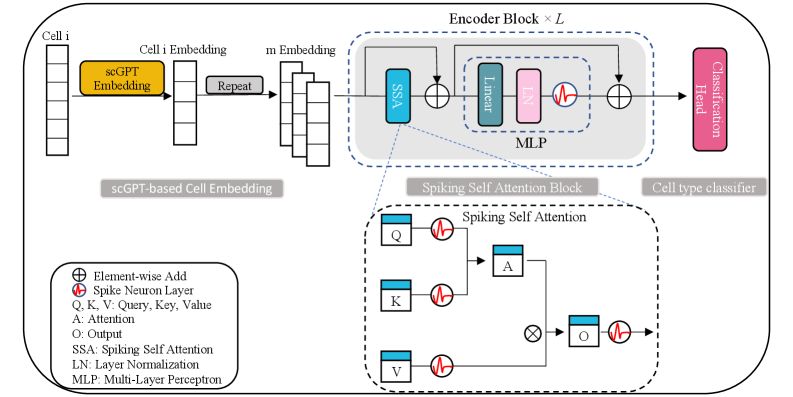
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
Department of Biomedical Informatics, Emory University | Department of Surgery, Duke University
30秒速读
IN SHORT: This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to identify previously unseen cell populations.
核心创新
- Methodology First integration of spiking neural networks with transformer architecture for single-cell analysis, using Leaky Integrate-and-Fire (LIF) neurons in a multi-head Spiking Self-Attention mechanism for energy-efficient computation.
- Methodology Novel two-step embedding expansion strategy: repeating cell embeddings along feature channels (default m=300) and temporal dimensions (default T=4) to enhance representation richness and training stability.
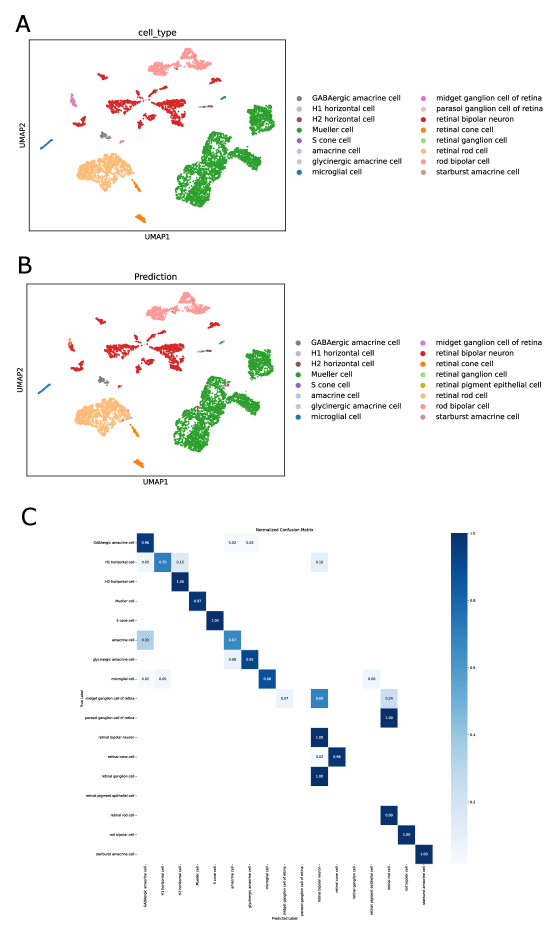
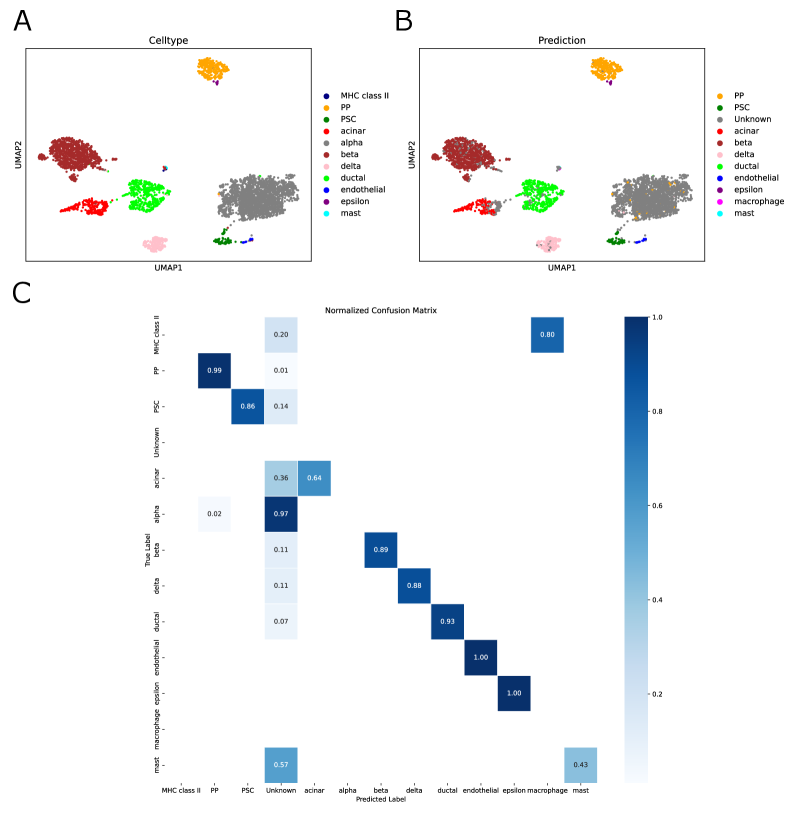
- Biology Confidence-based rejection mechanism that successfully identifies 97% of unseen 'alpha cells' as 'Unknown' in pancreas datasets, enabling robust detection of novel cell types absent from training data.
主要结论
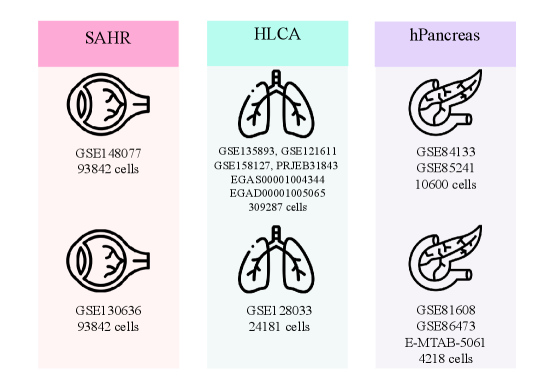
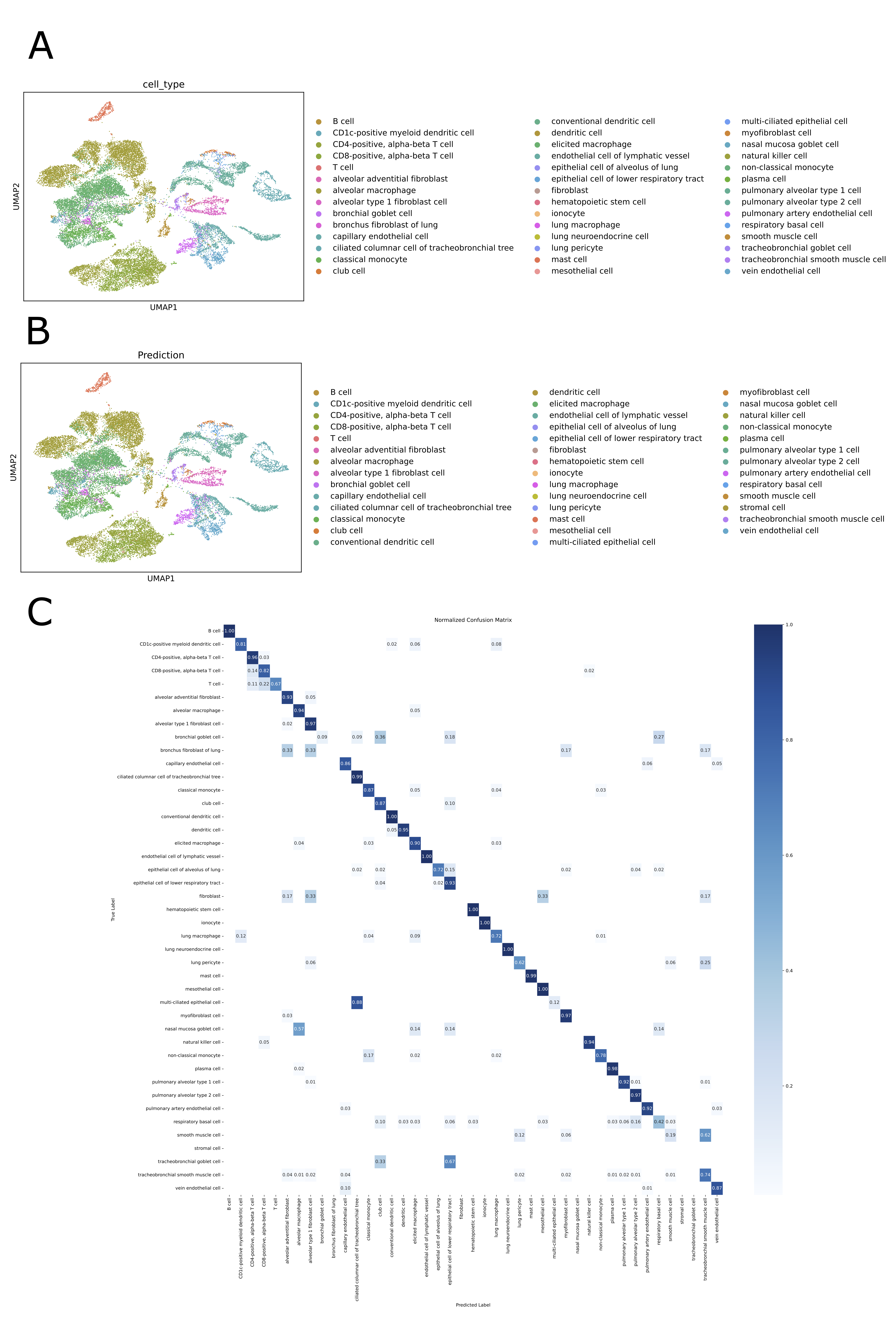
- SpikGPT achieves accuracy of 0.991 on SAHR dataset and 0.920 on HLCA dataset, outperforming or matching 8 benchmark methods including scGPT, CCA, and scPred.
- The model demonstrates superior robustness to batch effects, maintaining macro F1-score of 0.711 on heterogeneous HLCA data where traditional methods like SingleR drop to 0.207 F1-score.
- SpikGPT successfully identifies 97% of unseen 'alpha cells' as 'Unknown' using confidence thresholding (p<0.05), enabling reliable detection of novel cell populations.
摘要: Accurate and scalable cell type annotation remains a challenge in single-cell transcriptomics, especially when datasets exhibit strong batch effects or contain previously unseen cell populations. Here we introduce SpikGPT, a hybrid deep learning framework that integrates scGPT-derived cell embeddings with a spiking Transformer architecture to achieve efficient and robust annotation. scGPT provides biologically informed dense representations of each cell, which are further processed by a multi-head Spiking Self-Attention mechanism, energy-efficient feature extraction. Across multiple benchmark datasets, SpikGPT consistently matches or exceeds the performance of leading annotation tools. Notably, SpikGPT uniquely identifies unseen cell types by assigning low-confidence predictions to an 'Unknown' category, allowing accurate rejection of cell states absent from the training reference. Together, these results demonstrate that SpikGPT is a versatile and reliable annotation tool capable of generalizing across datasets, resolving complex cellular heterogeneity, and facilitating discovery of novel or disease-associated cell populations.