
Paper List
-
Developing the PsyCogMetrics™ AI Lab to Evaluate Large Language Models and Advance Cognitive Science
This paper addresses the critical gap between sophisticated LLM evaluation needs and the lack of accessible, scientifically rigorous platforms that in...
-
Equivalence of approximation by networks of single- and multi-spike neurons
This paper resolves the fundamental question of whether single-spike spiking neural networks (SNNs) are inherently less expressive than multi-spike SN...
-
The neuroscience of transformers
提出了Transformer架构与皮层柱微环路之间的新颖计算映射,连接了现代AI与神经科学。
-
Framing local structural identifiability and observability in terms of parameter-state symmetries
This paper addresses the core challenge of systematically determining which parameters and states in a mechanistic ODE model can be uniquely inferred ...
-
Leveraging Phytolith Research using Artificial Intelligence
This paper addresses the critical bottleneck in phytolith research by automating the labor-intensive manual microscopy process through a multimodal AI...
-
Neural network-based encoding in free-viewing fMRI with gaze-aware models
This paper addresses the core challenge of building computationally efficient and ecologically valid brain encoding models for naturalistic vision by ...
-
Scalable DNA Ternary Full Adder Enabled by a Competitive Blocking Circuit
This paper addresses the core bottleneck of carry information attenuation and limited computational scale in DNA binary adders by introducing a scalab...
-
ELISA: An Interpretable Hybrid Generative AI Agent for Expression-Grounded Discovery in Single-Cell Genomics
This paper addresses the critical bottleneck of translating high-dimensional single-cell transcriptomic data into interpretable biological hypotheses ...
Contrastive Deep Learning for Variant Detection in Wastewater Genomic Sequencing
Georgia State University, Atlanta, Georgia, USA
30秒速读
IN SHORT: This paper addresses the core challenge of detecting viral variants in wastewater sequencing data without reference genomes or labeled annotations, overcoming issues of high noise, low coverage, and fragmented reads.
核心创新
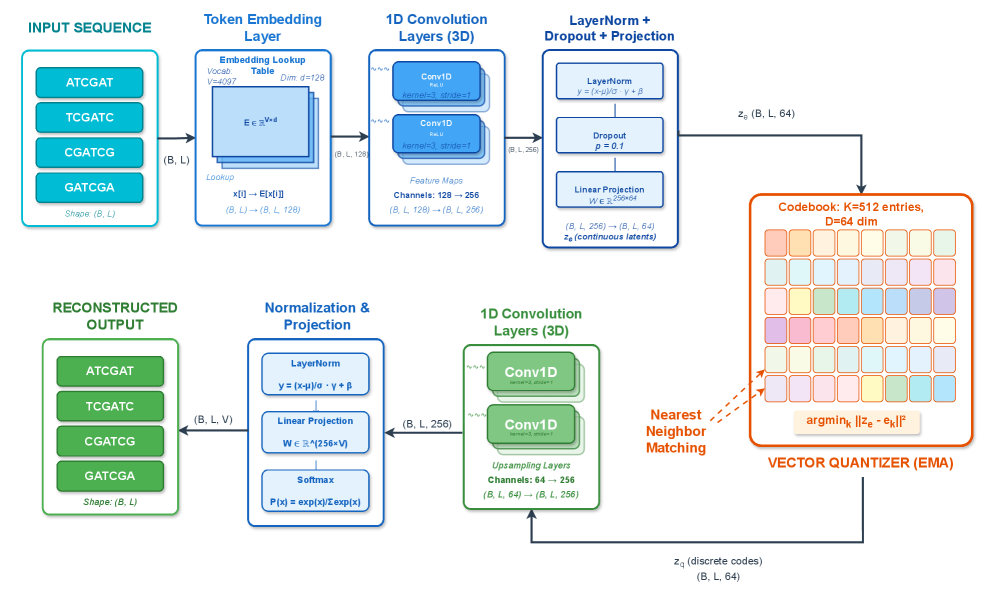
- Methodology First comprehensive application of VQ-VAE with EMA quantization to wastewater genomic surveillance, achieving 99.52% token-level reconstruction accuracy with 19.73% codebook utilization.
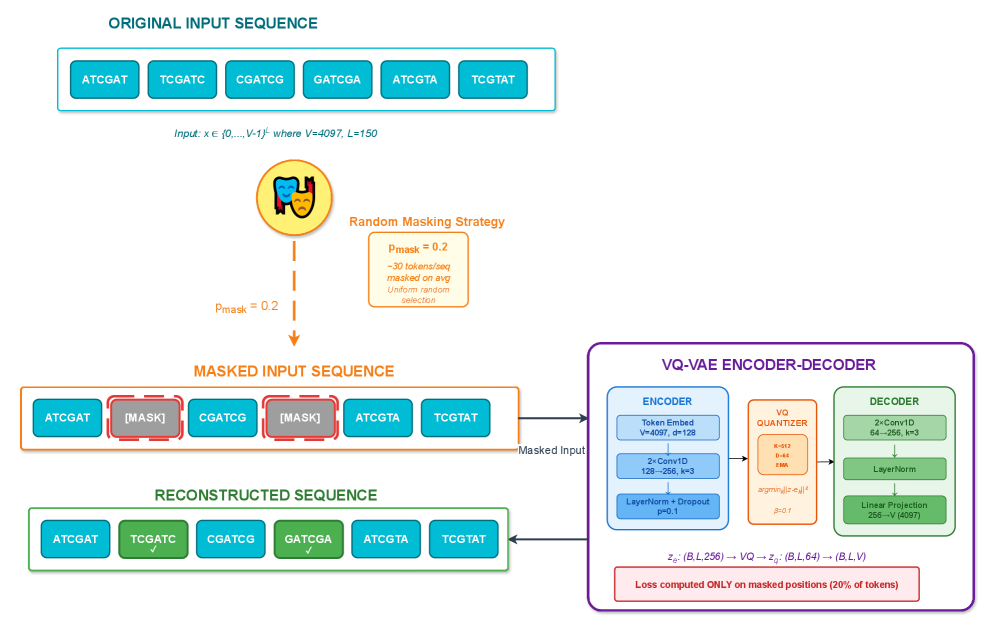
- Methodology Integration of masked reconstruction pretraining (BERT-style) maintaining ~95% accuracy under 20% token corruption, enabling robust inference with missing/low-quality data.
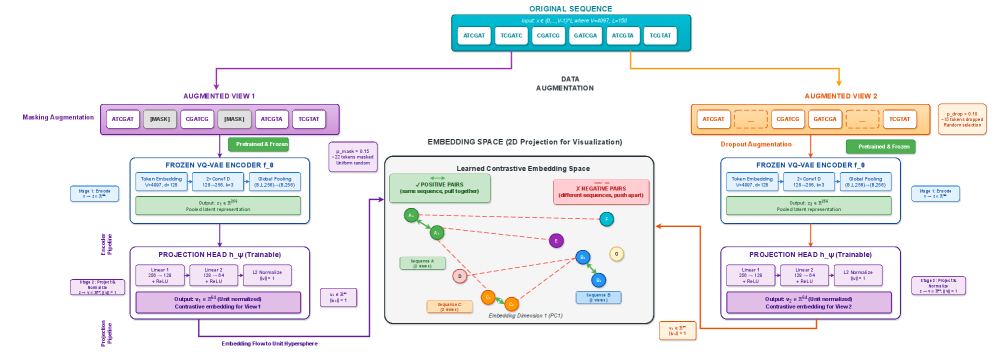
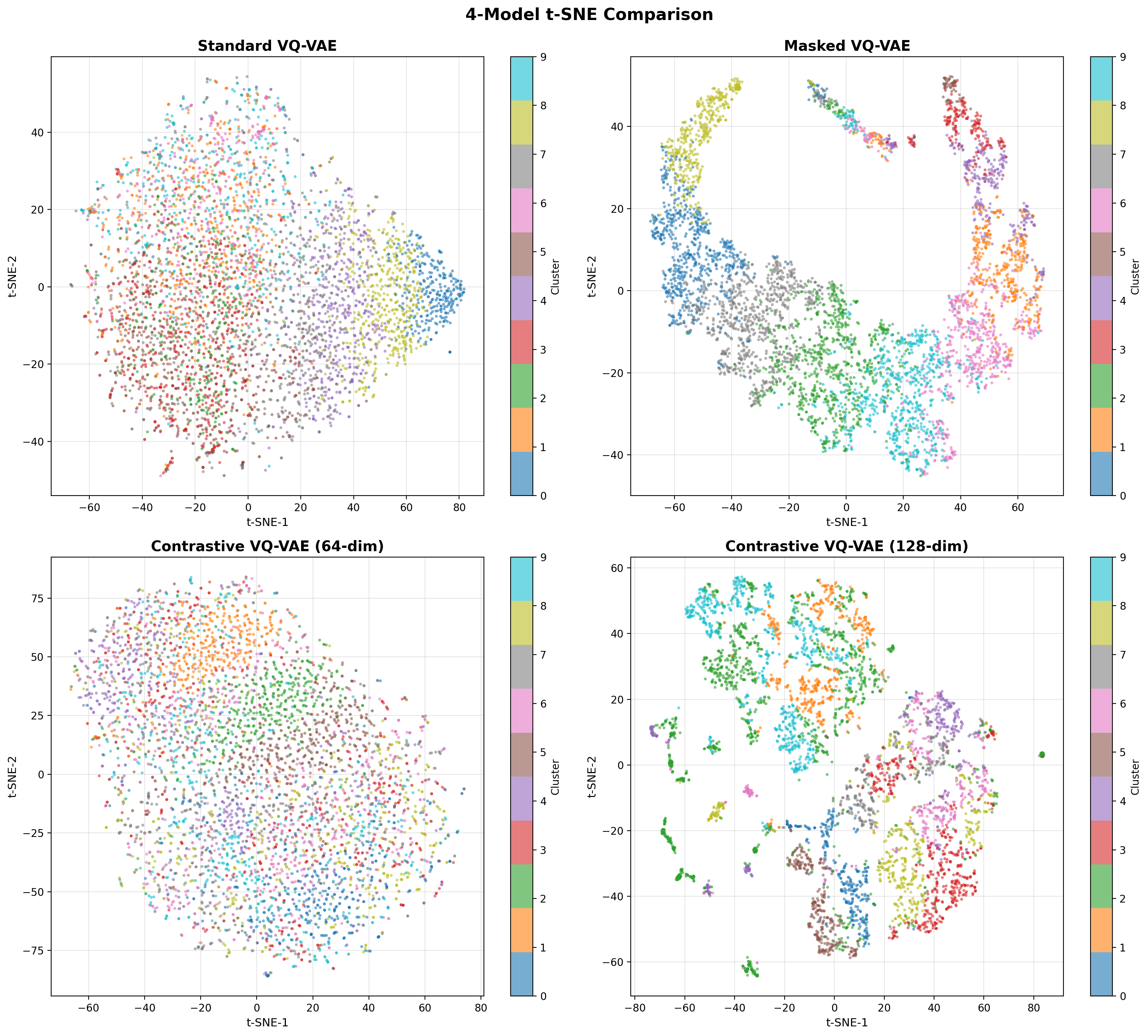
- Methodology Contrastive fine-tuning with varying embedding dimensions showing +35% (64-dim) and +42% (128-dim) Silhouette score improvements, establishing representation capacity impact on variant discrimination.
主要结论
- VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate on SARS-CoV-2 wastewater data with 100,000 reads.
- Contrastive fine-tuning improves clustering performance by +35% (0.31→0.42) with 64-dim embeddings and +42% (0.31→0.44) with 128-dim embeddings.
- The framework maintains efficient codebook utilization (19.73%, 101 of 512 codes active) while providing robust performance under data corruption.
摘要: Wastewater-based genomic surveillance has emerged as a powerful tool for population-level viral monitoring, offering comprehensive insights into circulating viral variants across entire communities. However, this approach faces significant computational challenges stemming from high sequencing noise, low viral coverage, fragmented reads, and the complete absence of labeled variant annotations. Traditional reference-based variant calling pipelines struggle with novel mutations and require extensive computational resources. We present a comprehensive framework for unsupervised viral variant detection using Vector-Quantized Variational Autoencoders (VQ-VAE) that learns discrete codebooks of genomic patterns from k-mer tokenized sequences without requiring reference genomes or variant labels. Our approach extends the base VQ-VAE architecture with masked reconstruction pretraining for robustness to missing data and contrastive learning for highly discriminative embeddings. Evaluated on SARS-CoV-2 wastewater sequencing data comprising approximately 100,000 reads, our VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate while maintaining 19.73% codebook utilization (101 of 512 codes active), demonstrating efficient discrete representation learning. Contrastive fine-tuning with different projection dimensions yields substantial clustering improvements: 64-dimensional embeddings achieve +35% Silhouette score improvement (0.31→0.42), while 128-dimensional embeddings achieve +42% improvement (0.31→0.44), clearly demonstrating the impact of embedding dimensionality on variant discrimination capability. Our reference-free framework provides a scalable, interpretable approach to genomic surveillance with direct applications to public health monitoring.