
Paper List
-
STAR-GO: Improving Protein Function Prediction by Learning to Hierarchically Integrate Ontology-Informed Semantic Embeddings
This paper addresses the core challenge of generalizing protein function prediction to unseen or newly introduced Gene Ontology (GO) terms by overcomi...
-
Incorporating indel channels into average-case analysis of seed-chain-extend
This paper addresses the core pain point of bridging the theoretical gap for the widely used seed-chain-extend heuristic by providing the first rigoro...
-
Competition, stability, and functionality in excitatory-inhibitory neural circuits
This paper addresses the core challenge of extending interpretable energy-based frameworks to biologically realistic asymmetric neural networks, where...
-
Enhancing Clinical Note Generation with ICD-10, Clinical Ontology Knowledge Graphs, and Chain-of-Thought Prompting Using GPT-4
This paper addresses the core challenge of generating accurate and clinically relevant patient notes from sparse inputs (ICD codes and basic demograph...
-
Learning From Limited Data and Feedback for Cell Culture Process Monitoring: A Comparative Study
This paper addresses the core challenge of developing accurate real-time bioprocess monitoring soft sensors under severe data constraints: limited his...
-
Cell-cell communication inference and analysis: biological mechanisms, computational approaches, and future opportunities
This review addresses the critical need for a systematic framework to navigate the rapidly expanding landscape of computational methods for inferring ...
-
Generating a Contact Matrix for Aged Care Settings in Australia: an agent-based model study
This study addresses the critical gap in understanding heterogeneous contact patterns within aged care facilities, where existing population-level con...
-
Emergent Spatiotemporal Dynamics in Large-Scale Brain Networks with Next Generation Neural Mass Models
This work addresses the core challenge of understanding how complex, brain-wide spatiotemporal patterns emerge from the interaction of biophysically d...
Training Dynamics of Learning 3D-Rotational Equivariance
Genentech Computational Sciences | New York University
30秒速读
IN SHORT: This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with data augmentation, by quantifying the speed and extent to which the latter learn 3D rotational symmetry.
核心创新
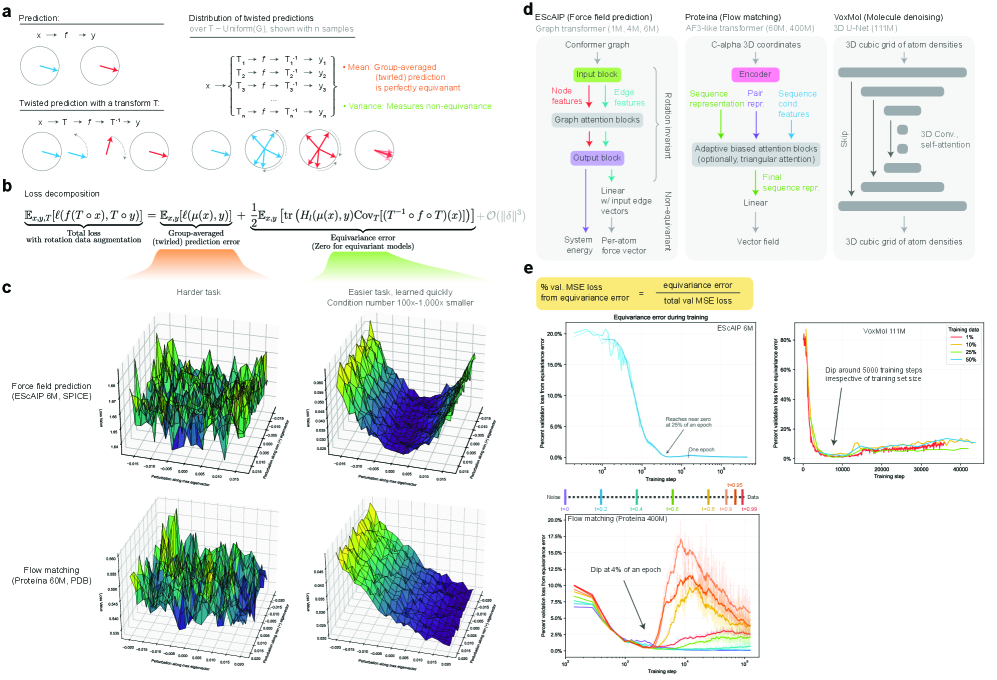
- Methodology Introduces a principled, generalizable framework to decompose total loss into a 'twirled prediction error' (ℒ_mean) and an 'equivariance error' (ℒ_equiv), enabling precise measurement of the percent of loss attributable to imperfect symmetry learning.
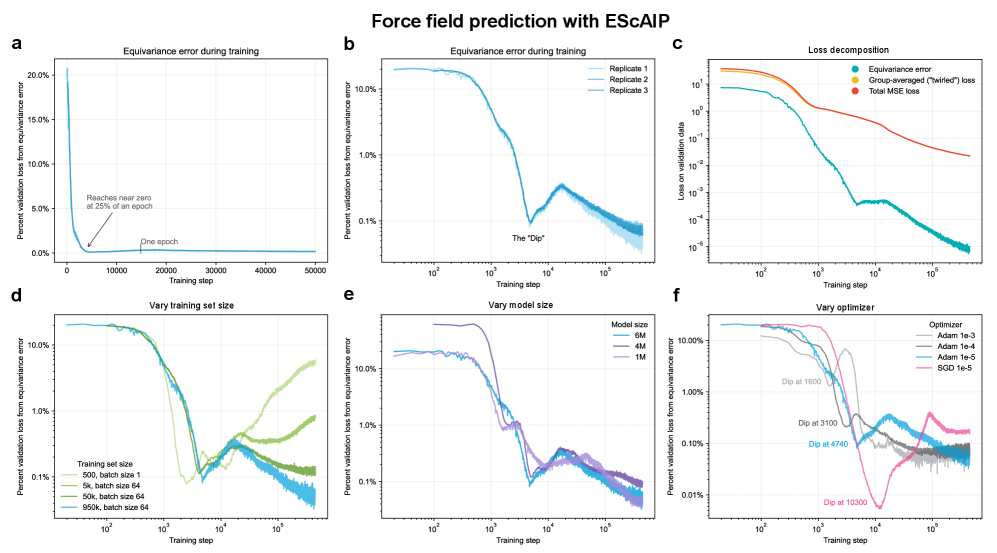
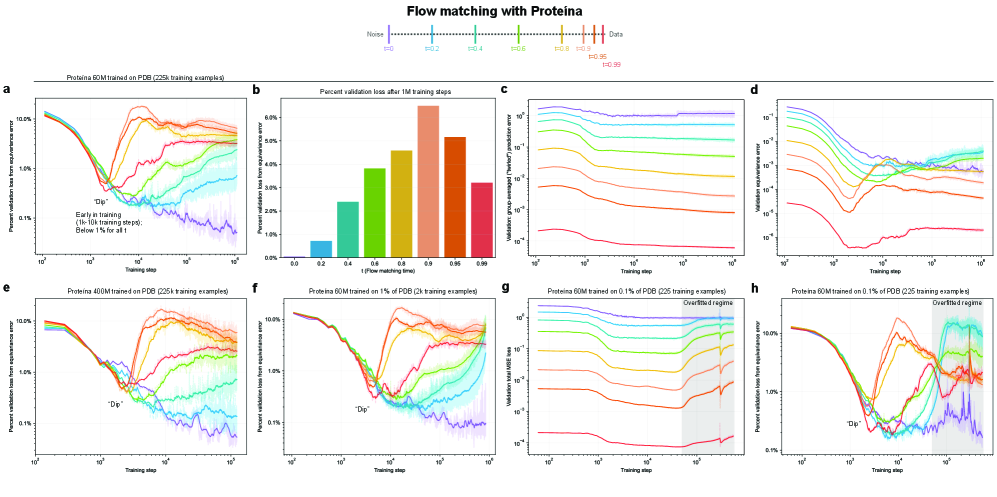
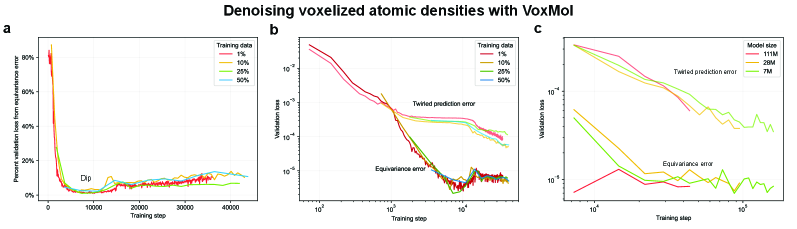
- Methodology Empirically demonstrates that models learning 3D-rotational equivariance via data augmentation achieve very low equivariance error (≤2% of total loss) remarkably quickly, within 1k-10k training steps, across diverse molecular tasks and model scales.
- Theory Provides theoretical and experimental evidence that learning equivariance is an easier task than the main prediction, characterized by a smoother and better-conditioned loss landscape (e.g., 1000x lower condition number for ℒ_equiv vs. ℒ_mean in force field prediction).
主要结论
- Non-equivariant models with data augmentation learn 3D rotational equivariance rapidly and effectively, reducing the equivariance error component to ≤2% of the total validation loss within the first 1k-10k training steps.
- The loss penalty for imperfect equivariance (ℒ_equiv) is small throughout training for 3D rotations, meaning the primary trade-off is the 'efficiency gap' (slower training/inference of equivariant models) rather than a significant accuracy penalty.
- The speed of learning equivariance is robust to model size (1M to 400M parameters), dataset size (500 to 1M samples), and optimizer choice, indicating it is a fundamental property of the learning task landscape.
摘要: While data augmentation is widely used to train symmetry-agnostic models, it remains unclear how quickly and effectively they learn to respect symmetries. We investigate this by deriving a principled measure of equivariance error that, for convex losses, calculates the percent of total loss attributable to imperfections in learned symmetry. We focus our empirical investigation to 3D-rotation equivariance on high-dimensional molecular tasks (flow matching, force field prediction, denoising voxels) and find that models reduce equivariance error quickly to ≤2% held-out loss within 1k-10k training steps, a result robust to model and dataset size. This happens because learning 3D-rotational equivariance is an easier learning task, with a smoother and better-conditioned loss landscape, than the main prediction task. For 3D rotations, the loss penalty for non-equivariant models is small throughout training, so they may achieve lower test loss than equivariant models per GPU-hour unless the equivariant “efficiency gap” is narrowed. We also experimentally and theoretically investigate the relationships between relative equivariance error, learning gradients, and model parameters.