
Paper List
-
Developing the PsyCogMetrics™ AI Lab to Evaluate Large Language Models and Advance Cognitive Science
This paper addresses the critical gap between sophisticated LLM evaluation needs and the lack of accessible, scientifically rigorous platforms that in...
-
Equivalence of approximation by networks of single- and multi-spike neurons
This paper resolves the fundamental question of whether single-spike spiking neural networks (SNNs) are inherently less expressive than multi-spike SN...
-
The neuroscience of transformers
提出了Transformer架构与皮层柱微环路之间的新颖计算映射,连接了现代AI与神经科学。
-
Framing local structural identifiability and observability in terms of parameter-state symmetries
This paper addresses the core challenge of systematically determining which parameters and states in a mechanistic ODE model can be uniquely inferred ...
-
Leveraging Phytolith Research using Artificial Intelligence
This paper addresses the critical bottleneck in phytolith research by automating the labor-intensive manual microscopy process through a multimodal AI...
-
Neural network-based encoding in free-viewing fMRI with gaze-aware models
This paper addresses the core challenge of building computationally efficient and ecologically valid brain encoding models for naturalistic vision by ...
-
Scalable DNA Ternary Full Adder Enabled by a Competitive Blocking Circuit
This paper addresses the core bottleneck of carry information attenuation and limited computational scale in DNA binary adders by introducing a scalab...
-
ELISA: An Interpretable Hybrid Generative AI Agent for Expression-Grounded Discovery in Single-Cell Genomics
This paper addresses the critical bottleneck of translating high-dimensional single-cell transcriptomic data into interpretable biological hypotheses ...
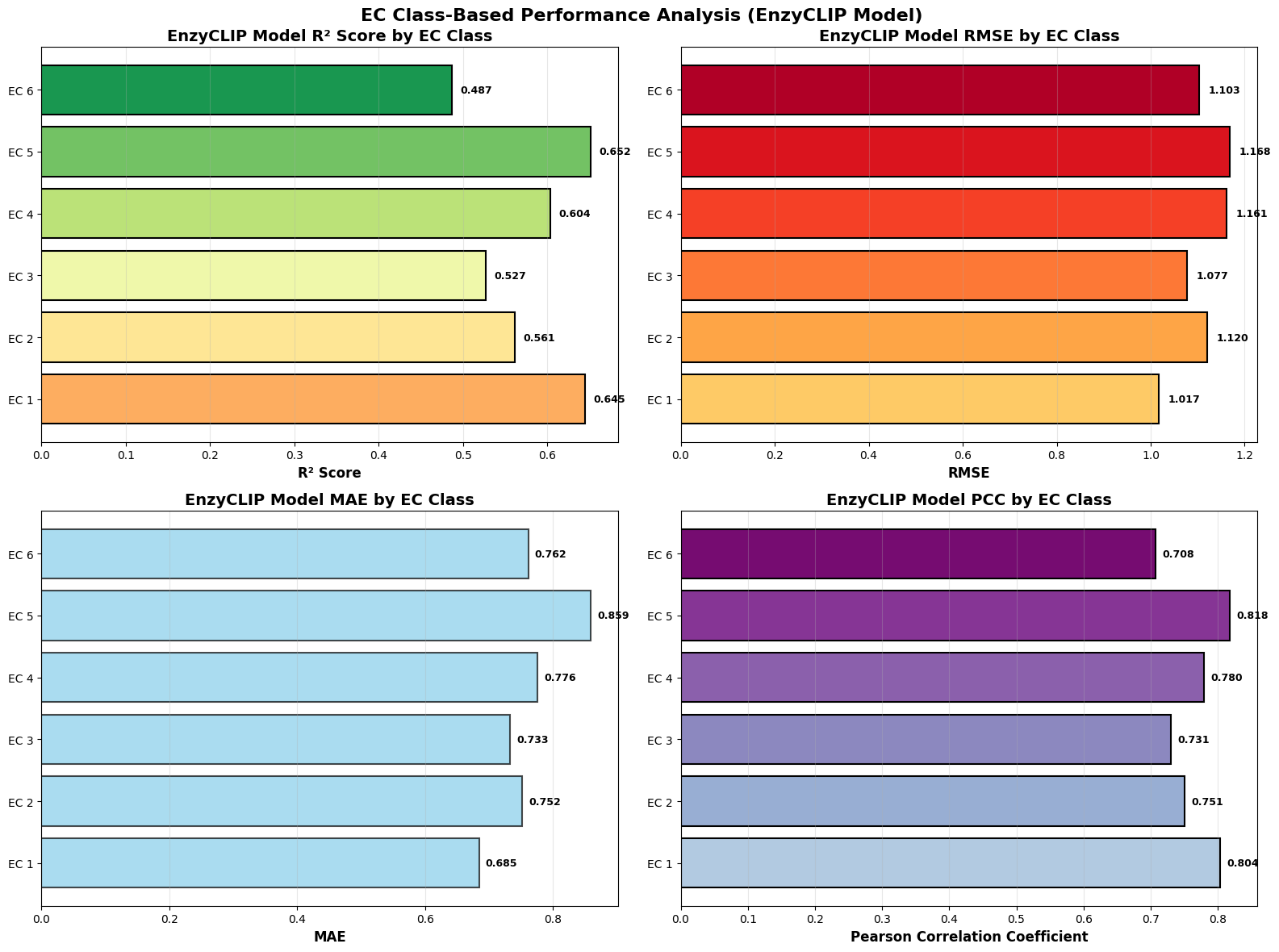
EnzyCLIP: A Cross-Attention Dual Encoder Framework with Contrastive Learning for Predicting Enzyme Kinetic Constants
Vellore Institute of Technology | BIT (Department of Computer Science) | BIT (Department of Bioengineering and Biotechnology)
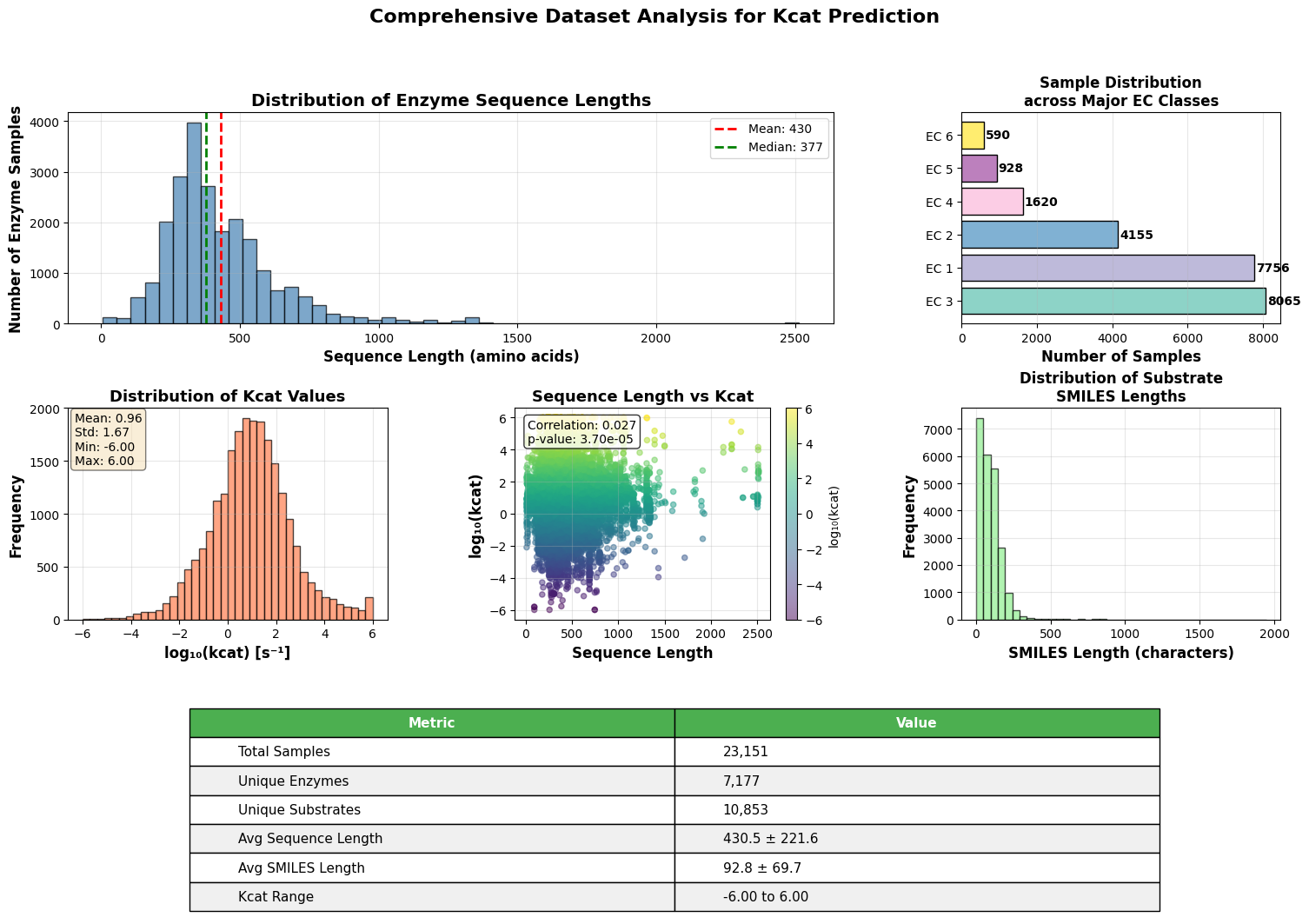
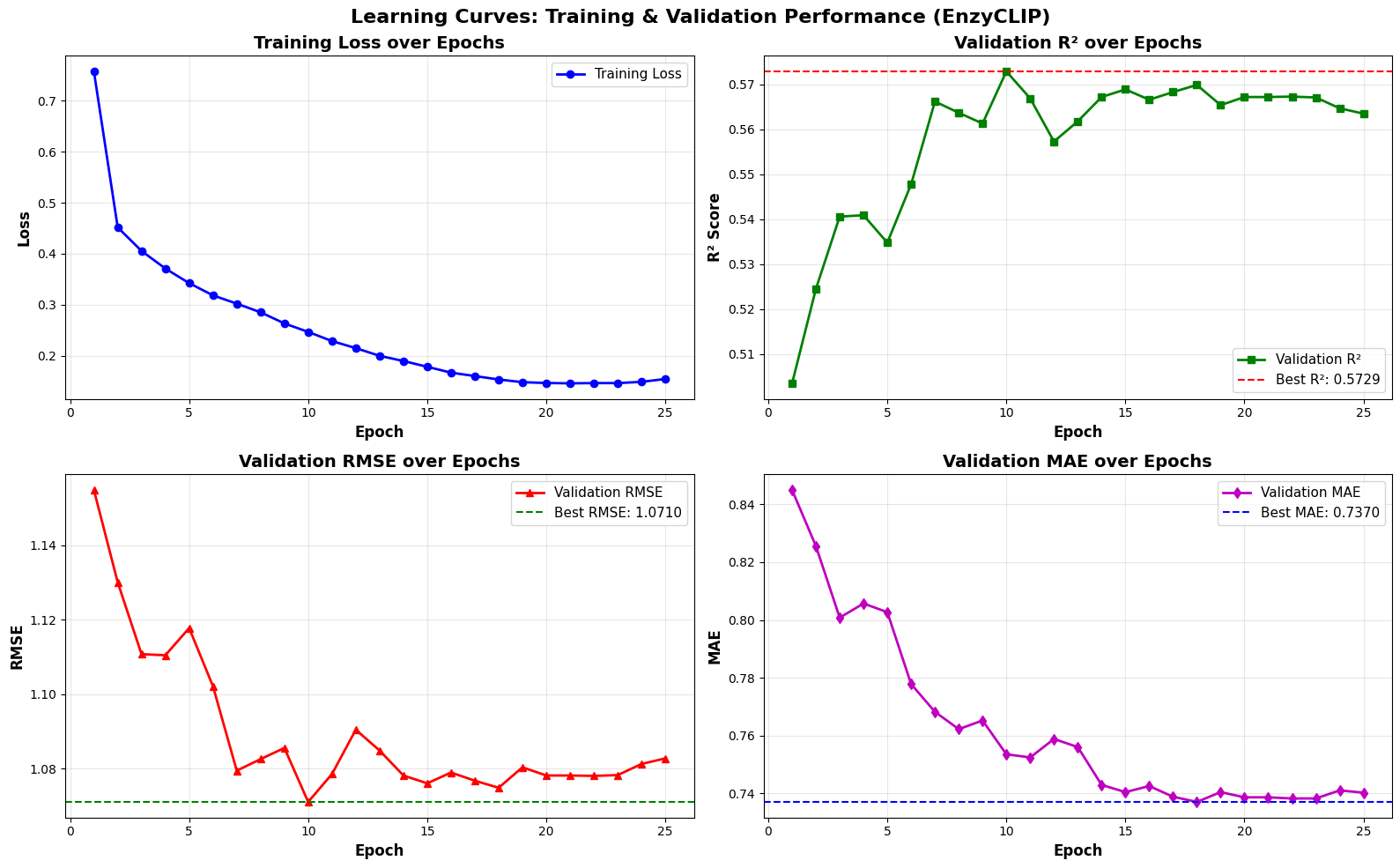
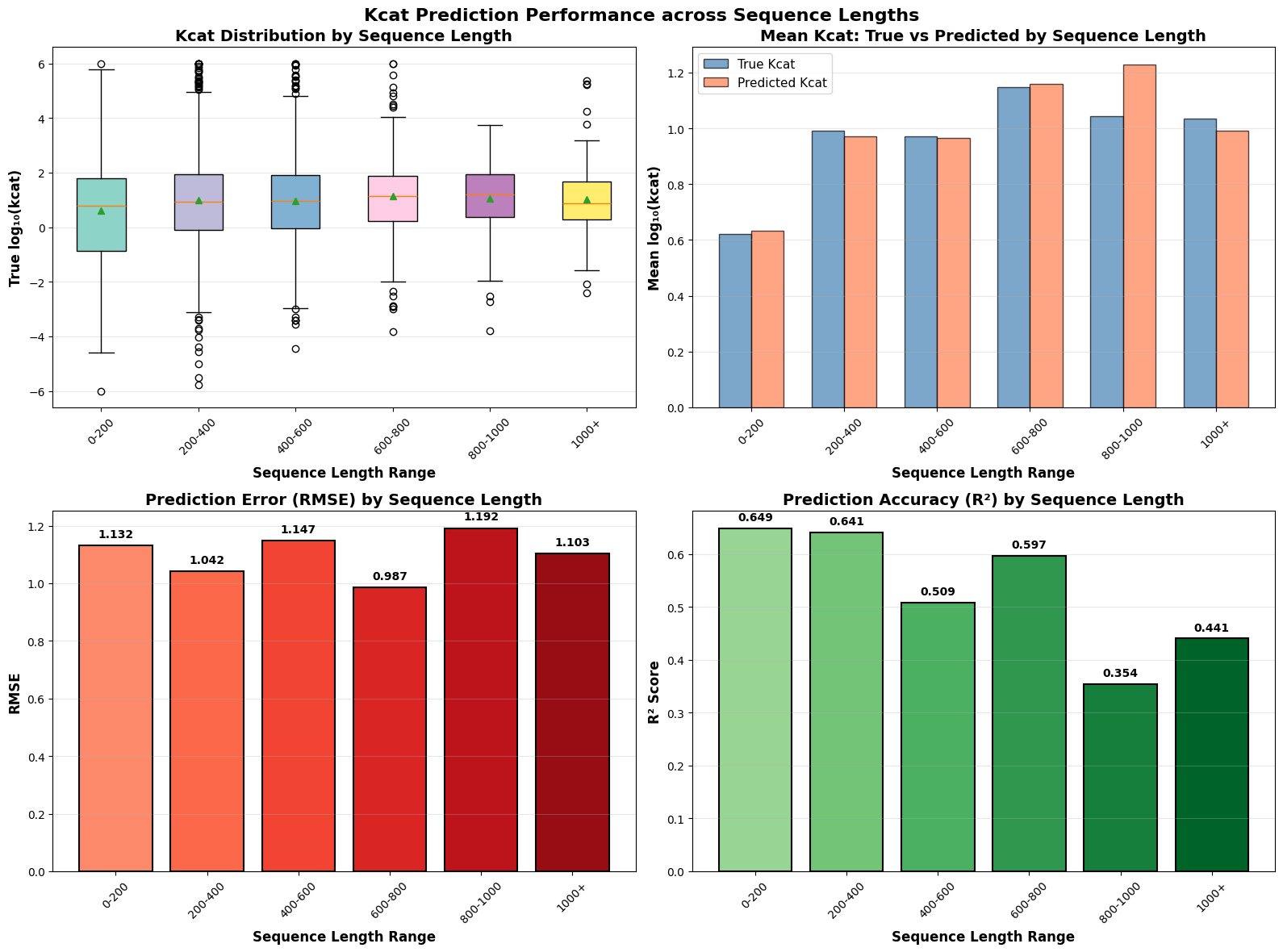
30秒速读
IN SHORT: This paper addresses the core challenge of jointly predicting enzyme kinetic parameters (Kcat and Km) by modeling dynamic enzyme-substrate interactions through a multimodal contrastive learning framework.
核心创新
- Methodology Proposes a CLIP-inspired dual-encoder architecture with bidirectional cross-attention that dynamically models enzyme-substrate interactions, overcoming the limitation of separate processing in existing methods.
- Methodology Integrates contrastive learning (InfoNCE loss) with multi-task regression (Huber loss) to learn aligned multimodal representations while jointly predicting both Kcat and Km parameters.
- Biology Addresses the critical gap in existing literature that typically focuses on single parameter prediction (mainly Kcat) by providing a unified framework for joint prediction of both fundamental kinetic constants.
主要结论
- EnzyCLIP achieves competitive baseline performance with R² scores of 0.593 for Kcat and 0.607 for Km prediction on the CatPred-DB dataset containing 23,151 Kcat and 41,174 Km measurements.
- The integration of contrastive learning with cross-attention mechanisms enables the model to capture biochemical relationships and substrate preferences even for unseen enzyme-substrate pairs.
- XGBoost ensemble methods applied to learned embeddings further improved Km prediction performance to R² = 0.61 while maintaining robust Kcat prediction capabilities.
摘要: Accurate prediction of enzyme kinetic parameters is crucial for drug discovery, metabolic engineering, and synthetic biology applications. Current computational approaches face limitations in capturing complex enzyme–substrate interactions and often focus on single parameters while neglecting the joint prediction of catalytic turnover numbers (Kcat) and Michaelis–Menten constants (Km). We present EnzyCLIP, a novel dual-encoder framework that leverages contrastive learning and cross-attention mechanisms to predict enzyme kinetic parameters from protein sequences and substrate molecular structures. Our approach integrates ESM-2 protein language model embeddings with ChemBERTa chemical representations through a CLIP-inspired architecture enhanced with bidirectional cross-attention for dynamic enzyme–substrate interaction modeling. EnzyCLIP combines InfoNCE contrastive loss with Huber regression loss to learn aligned multimodal representations while predicting log10-transformed kinetic parameters. EnzyCLIP is trained on the CatPred-DB database containing 23,151 Kcat and 41,174 Km experimentally validated measurements, and achieved competitive baseline performance with R2 scores of 0.593 for Kcat and 0.607 for Km prediction. XGBoost ensemble methods on learned embeddings further improved Km prediction (R2 = 0.61) while maintaining robust Kcat performance.