
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
SSDLabeler: Realistic semi-synthetic data generation for multi-label artifact classification in EEG
Sony Computer Science Laboratories, Inc., Tokyo, Japan
30秒速读
IN SHORT: This paper addresses the core challenge of training robust multi-label EEG artifact classifiers by overcoming the scarcity and limited diversity of manually labeled training data through a novel semi-synthetic data generation framework.
核心创新
- Methodology Introduces SSDLabeler, a framework that generates realistic semi-synthetic EEG data by simultaneously reinjecting multiple ICA-isolated artifact types into clean data, preserving the co-occurrence structure of real-world contamination.
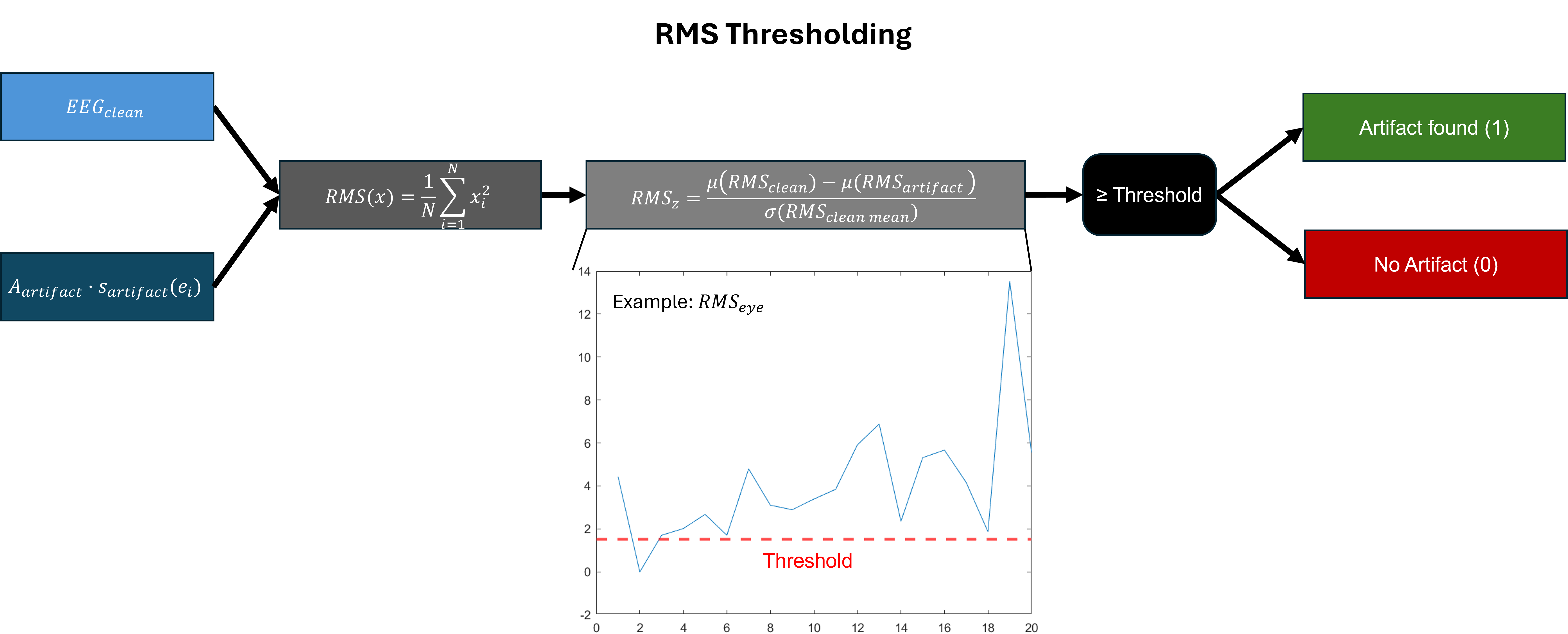
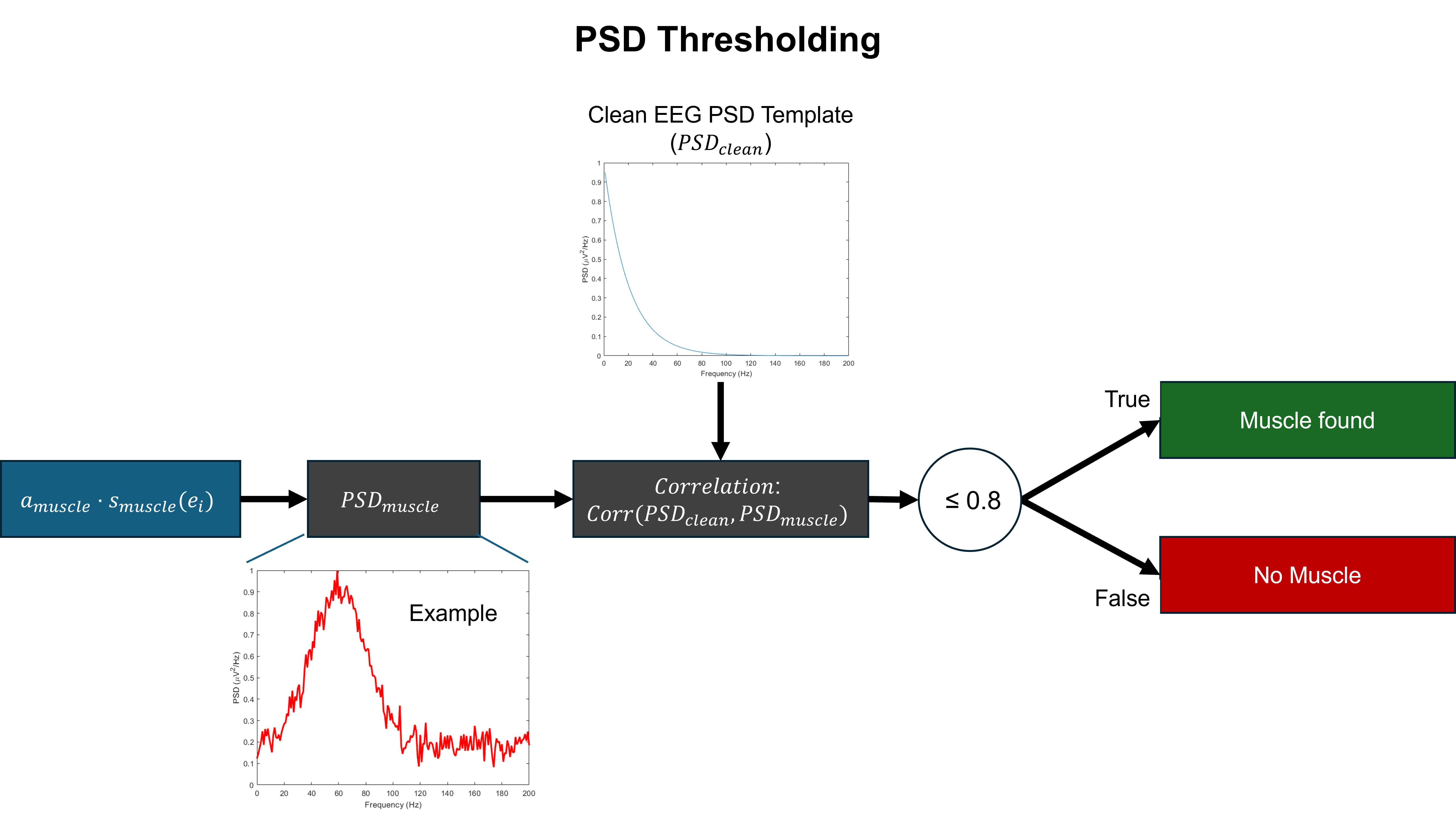
- Methodology Develops a novel artifact verification step using RMS and PSD thresholding criteria at the epoch level to ensure the physiological plausibility of generated contaminations, moving beyond simple ICA component injection.
- Biology Proposes a multi-label artifact classification paradigm that identifies multiple co-occurring artifact types (eye, muscle, heart, line, channel, other) within single EEG epochs, providing transparent contamination information for flexible preprocessing decisions.
主要结论
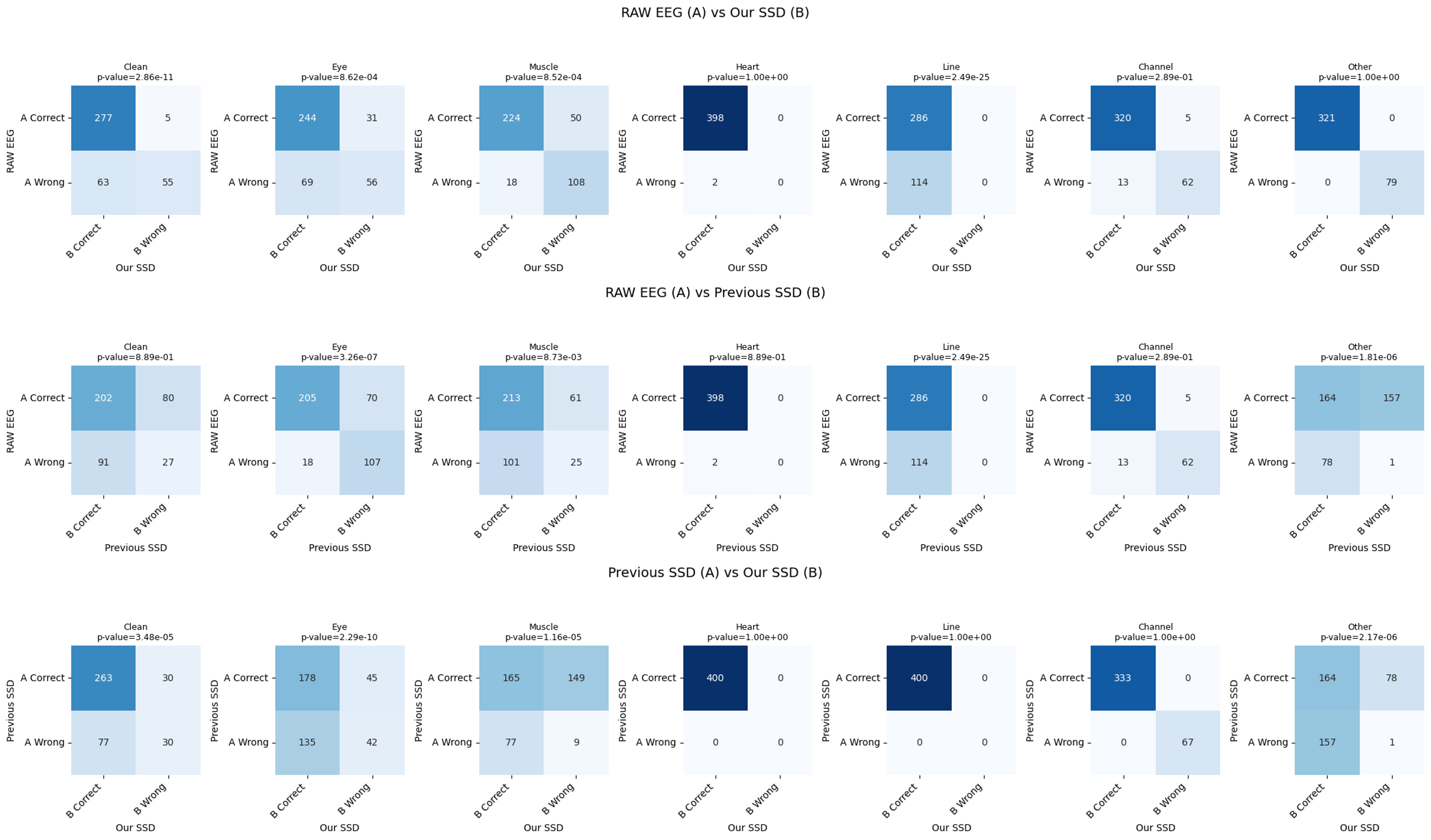
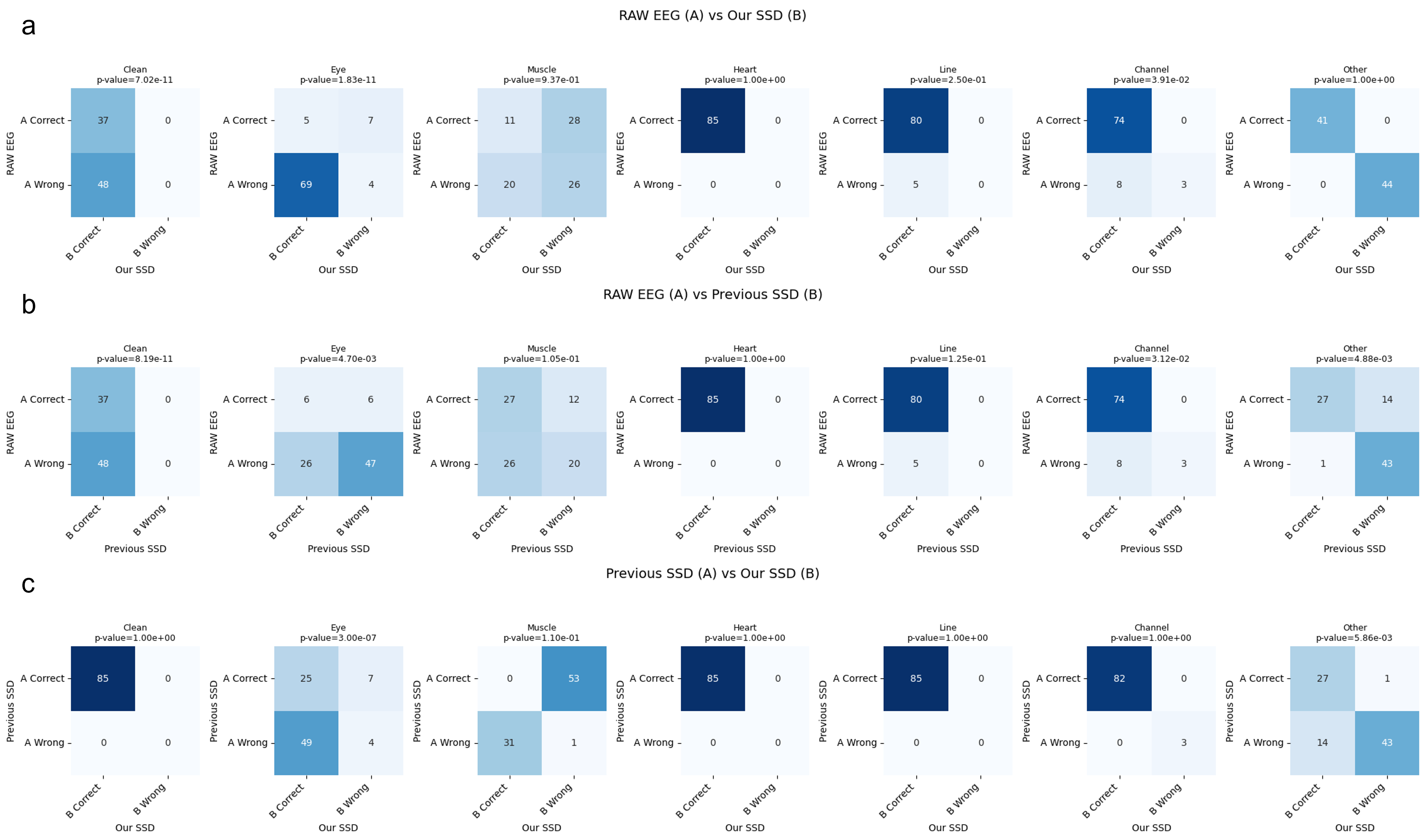
- SSDLabeler-trained classifiers achieved the highest overall accuracy (0.839) on motor execution test data, significantly outperforming raw EEG training (0.772, p<0.05 for Clean, Eye, and Line categories) and prior SSD methods (0.788).
- On instructed-noise session data, the proposed method achieved 0.812 accuracy, demonstrating strong generalization with significant improvements over raw EEG (0.618, p<0.05 for Clean, Eye, and Channel categories) and prior SSD (0.756).
- The framework successfully captures artifact co-occurrence, with the classifier showing balanced performance across most artifact types, though muscle artifact detection remained challenging (accuracy 0.605 vs. 0.785 for prior SSD).
摘要: EEG recordings are inherently contaminated by artifacts such as ocular, muscular, and environmental noise, which obscure neural activity and complicate preprocessing. Artifact classification offers advantages in stability and transparency, providing a viable alternative to ICA-based methods that enable flexible use alongside human inspections and across various applications. However, artifact classification is limited by its training data as it requires extensive manual labeling, which cannot fully cover the diversity of real-world EEG. Semi-synthetic data (SSD) methods have been proposed to address this limitation, but prior approaches typically injected single artifact types using ICA components or required separately recorded artifact signals, reducing both the realism of the generated data and the applicability of the method. To overcome these issues, we introduce SSDLabeler, a framework that generates realistic, annotated SSDs by decomposing real EEG with ICA, epoch-level artifact verification using RMS and PSD criteria, and reinjecting multiple artifact types into clean data. When applied to train a multi-label artifact classifier, it improved accuracy on raw EEG across diverse conditions compared to prior SSD and raw EEG training, establishing a scalable foundation for artifact handling that captures the co-occurrence and complexity of real EEG.