
Paper List
-
Macroscopic Dominance from Microscopic Extremes: Symmetry Breaking in Spatial Competition
This paper addresses the fundamental question of how microscopic stochastic advantages in spatial exploration translate into macroscopic resource domi...
-
Linear Readout of Neural Manifolds with Continuous Variables
This paper addresses the core challenge of quantifying how the geometric structure of high-dimensional neural population activity (neural manifolds) d...
-
Theory of Cell Body Lensing and Phototaxis Sign Reversal in “Eyeless” Mutants of Chlamydomonas
This paper solves the core puzzle of how eyeless mutants of Chlamydomonas exhibit reversed phototaxis by quantitatively modeling the competition betwe...
-
Cross-Species Transfer Learning for Electrophysiology-to-Transcriptomics Mapping in Cortical GABAergic Interneurons
This paper addresses the challenge of predicting transcriptomic identity from electrophysiological recordings in human cortical interneurons, where li...
-
Uncovering statistical structure in large-scale neural activity with Restricted Boltzmann Machines
This paper addresses the core challenge of modeling large-scale neural population activity (1500-2000 neurons) with interpretable higher-order interac...
-
Realizing Common Random Numbers: Event-Keyed Hashing for Causally Valid Stochastic Models
This paper addresses the critical problem that standard stateful PRNG implementations in agent-based models violate causal validity by making random d...
-
A Standardized Framework for Evaluating Gene Expression Generative Models
This paper addresses the critical lack of standardized evaluation protocols for single-cell gene expression generative models, where inconsistent metr...
-
Single Molecule Localization Microscopy Challenge: A Biologically Inspired Benchmark for Long-Sequence Modeling
This paper addresses the core challenge of evaluating state-space models on biologically realistic, sparse, and stochastic temporal processes, which a...
Contrastive Deep Learning for Variant Detection in Wastewater Genomic Sequencing
Georgia State University, Atlanta, Georgia, USA
30秒速读
IN SHORT: This paper addresses the core challenge of detecting viral variants in wastewater sequencing data without reference genomes or labeled annotations, overcoming issues of high noise, low coverage, and fragmented reads.
核心创新
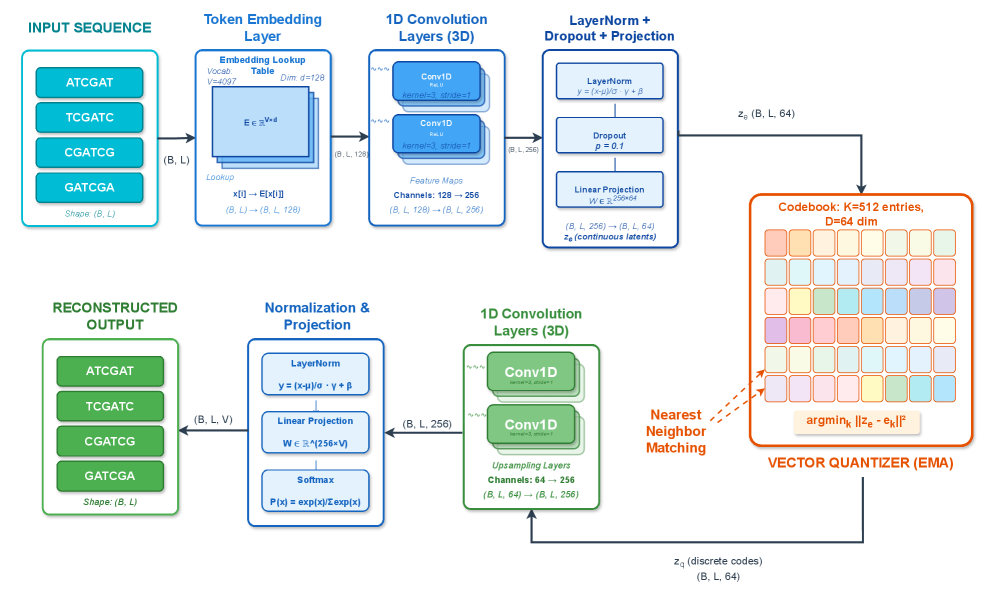
- Methodology First comprehensive application of VQ-VAE with EMA quantization to wastewater genomic surveillance, achieving 99.52% token-level reconstruction accuracy with 19.73% codebook utilization.
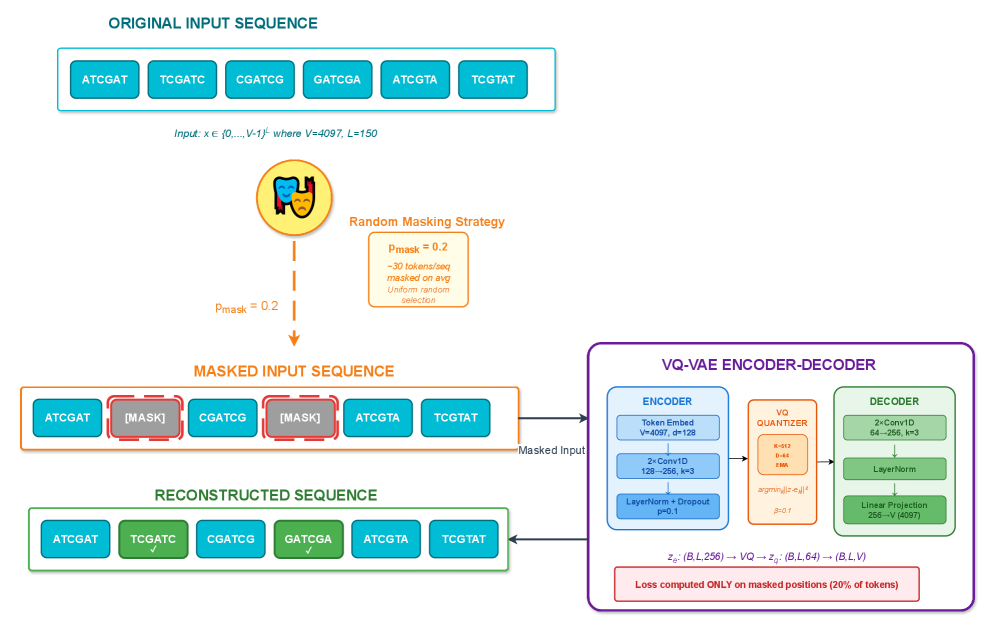
- Methodology Integration of masked reconstruction pretraining (BERT-style) maintaining ~95% accuracy under 20% token corruption, enabling robust inference with missing/low-quality data.
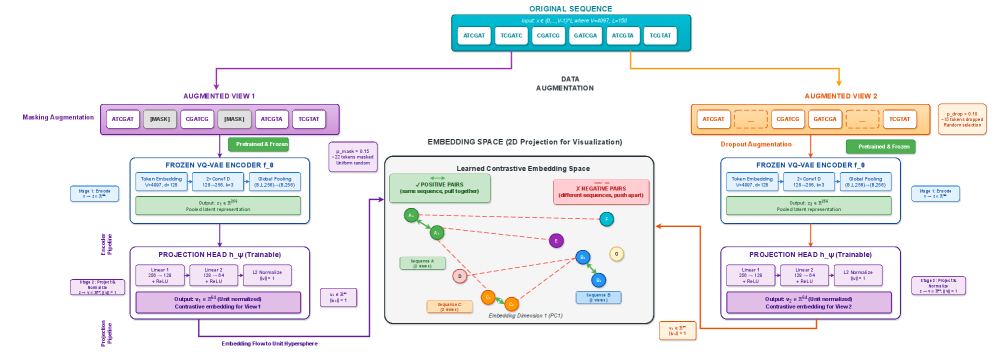
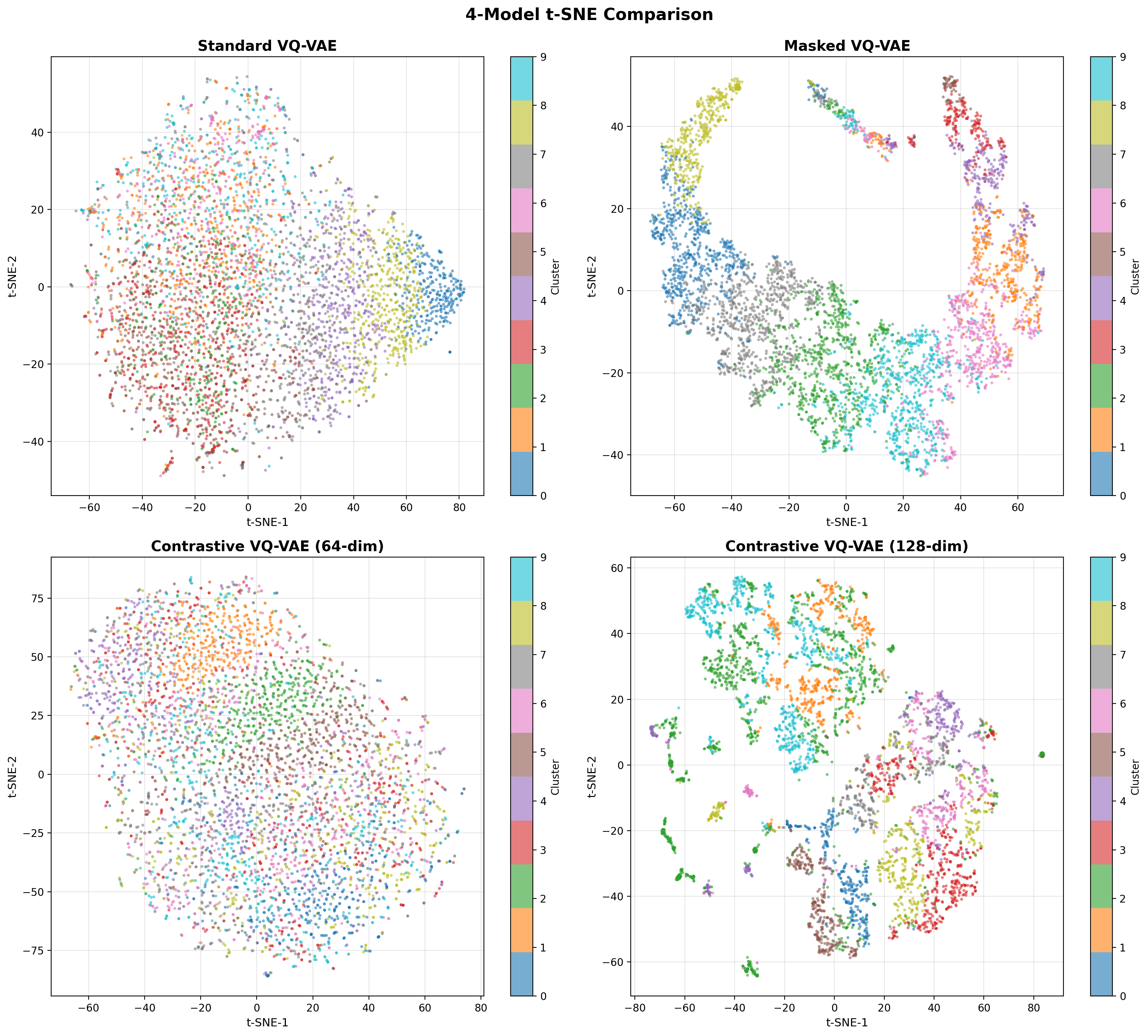
- Methodology Contrastive fine-tuning with varying embedding dimensions showing +35% (64-dim) and +42% (128-dim) Silhouette score improvements, establishing representation capacity impact on variant discrimination.
主要结论
- VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate on SARS-CoV-2 wastewater data with 100,000 reads.
- Contrastive fine-tuning improves clustering performance by +35% (0.31→0.42) with 64-dim embeddings and +42% (0.31→0.44) with 128-dim embeddings.
- The framework maintains efficient codebook utilization (19.73%, 101 of 512 codes active) while providing robust performance under data corruption.
摘要: Wastewater-based genomic surveillance has emerged as a powerful tool for population-level viral monitoring, offering comprehensive insights into circulating viral variants across entire communities. However, this approach faces significant computational challenges stemming from high sequencing noise, low viral coverage, fragmented reads, and the complete absence of labeled variant annotations. Traditional reference-based variant calling pipelines struggle with novel mutations and require extensive computational resources. We present a comprehensive framework for unsupervised viral variant detection using Vector-Quantized Variational Autoencoders (VQ-VAE) that learns discrete codebooks of genomic patterns from k-mer tokenized sequences without requiring reference genomes or variant labels. Our approach extends the base VQ-VAE architecture with masked reconstruction pretraining for robustness to missing data and contrastive learning for highly discriminative embeddings. Evaluated on SARS-CoV-2 wastewater sequencing data comprising approximately 100,000 reads, our VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate while maintaining 19.73% codebook utilization (101 of 512 codes active), demonstrating efficient discrete representation learning. Contrastive fine-tuning with different projection dimensions yields substantial clustering improvements: 64-dimensional embeddings achieve +35% Silhouette score improvement (0.31→0.42), while 128-dimensional embeddings achieve +42% improvement (0.31→0.44), clearly demonstrating the impact of embedding dimensionality on variant discrimination capability. Our reference-free framework provides a scalable, interpretable approach to genomic surveillance with direct applications to public health monitoring.