
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
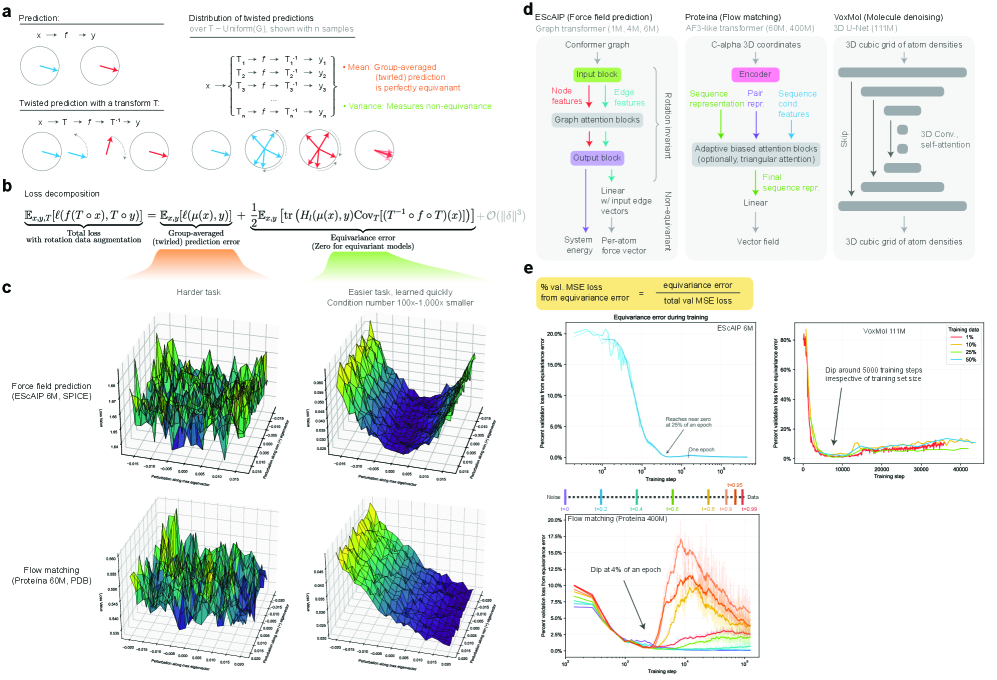
Training Dynamics of Learning 3D-Rotational Equivariance
Genentech Computational Sciences | New York University
30秒速读
IN SHORT: This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with data augmentation, by quantifying the speed and extent to which the latter learn 3D rotational symmetry.
核心创新
- Methodology Introduces a principled, generalizable framework to decompose total loss into a 'twirled prediction error' (ℒ_mean) and an 'equivariance error' (ℒ_equiv), enabling precise measurement of the percent of loss attributable to imperfect symmetry learning.
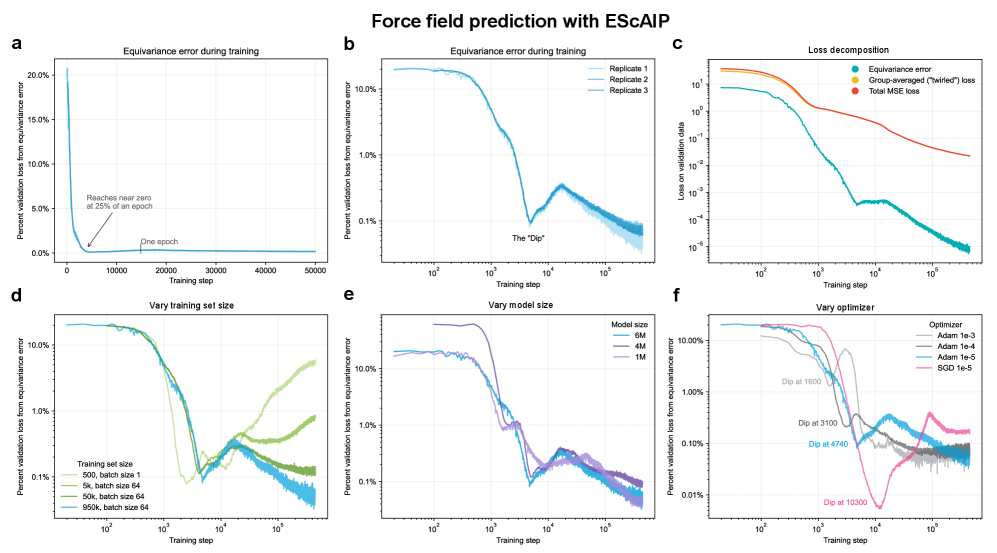
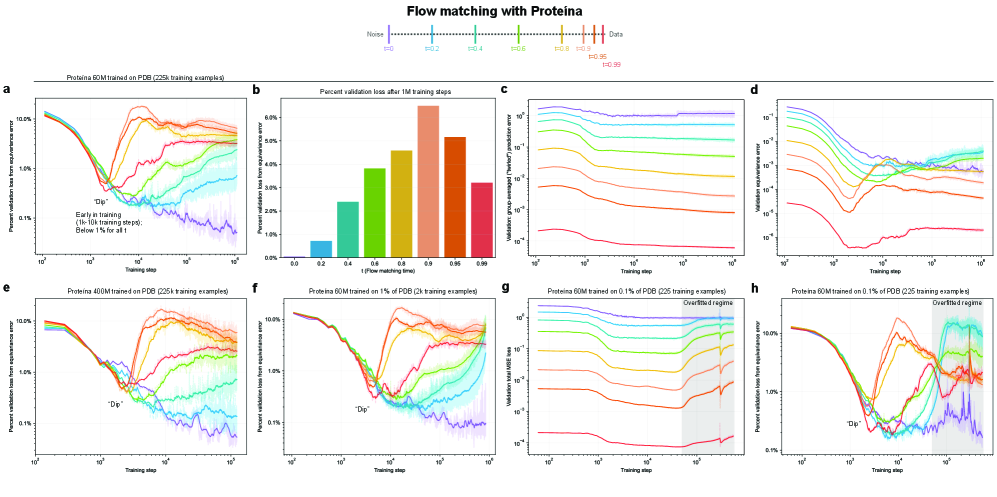
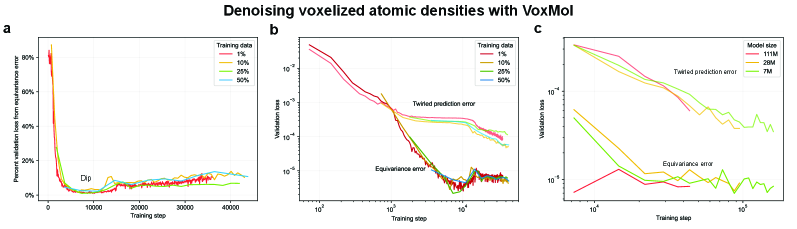
- Methodology Empirically demonstrates that models learning 3D-rotational equivariance via data augmentation achieve very low equivariance error (≤2% of total loss) remarkably quickly, within 1k-10k training steps, across diverse molecular tasks and model scales.
- Theory Provides theoretical and experimental evidence that learning equivariance is an easier task than the main prediction, characterized by a smoother and better-conditioned loss landscape (e.g., 1000x lower condition number for ℒ_equiv vs. ℒ_mean in force field prediction).
主要结论
- Non-equivariant models with data augmentation learn 3D rotational equivariance rapidly and effectively, reducing the equivariance error component to ≤2% of the total validation loss within the first 1k-10k training steps.
- The loss penalty for imperfect equivariance (ℒ_equiv) is small throughout training for 3D rotations, meaning the primary trade-off is the 'efficiency gap' (slower training/inference of equivariant models) rather than a significant accuracy penalty.
- The speed of learning equivariance is robust to model size (1M to 400M parameters), dataset size (500 to 1M samples), and optimizer choice, indicating it is a fundamental property of the learning task landscape.
摘要: While data augmentation is widely used to train symmetry-agnostic models, it remains unclear how quickly and effectively they learn to respect symmetries. We investigate this by deriving a principled measure of equivariance error that, for convex losses, calculates the percent of total loss attributable to imperfections in learned symmetry. We focus our empirical investigation to 3D-rotation equivariance on high-dimensional molecular tasks (flow matching, force field prediction, denoising voxels) and find that models reduce equivariance error quickly to ≤2% held-out loss within 1k-10k training steps, a result robust to model and dataset size. This happens because learning 3D-rotational equivariance is an easier learning task, with a smoother and better-conditioned loss landscape, than the main prediction task. For 3D rotations, the loss penalty for non-equivariant models is small throughout training, so they may achieve lower test loss than equivariant models per GPU-hour unless the equivariant “efficiency gap” is narrowed. We also experimentally and theoretically investigate the relationships between relative equivariance error, learning gradients, and model parameters.