
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
Pharmacophore-based design by learning on voxel grids
AIDD, Genentech
30秒速读
IN SHORT: This paper addresses the computational bottleneck and limited novelty in conventional pharmacophore-based virtual screening by introducing a voxel captioning method that generates novel molecules directly from 3D pharmacophore-shape profiles.
核心创新
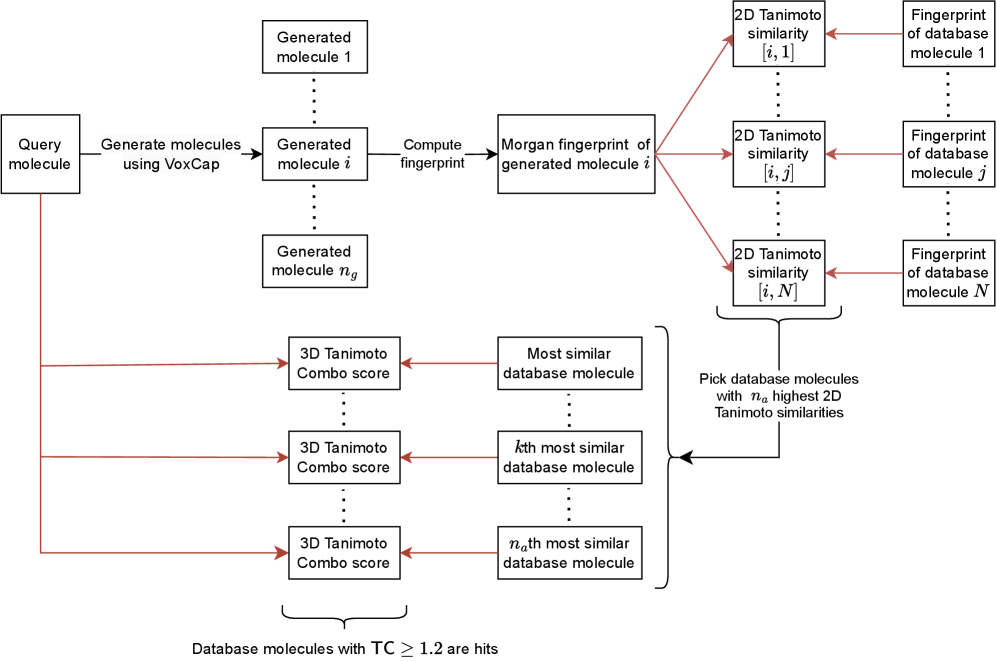
- Methodology Proposes VoxCap, the first voxel captioning method for generating SMILES strings from voxelized 3D pharmacophore-shape profiles, bridging 3D structural information with 1D string generation.
- Methodology Introduces a 'fast search' workflow that reduces computational complexity from O(database size) to O(n_g × n_a), enabling screening of billion-compound libraries previously considered intractable.
- Biology Demonstrates superior performance in generating diverse, novel scaffolds with high pharmacophore-shape similarity (Tanimoto Combo score ≥1.2), addressing both in-distribution and out-of-distribution query molecules.
主要结论
- VoxCap generates significantly more hits than baseline methods, with median hits per query increasing from 0 (baseline) to 116.5 on GEOM-drugs and from 0 to 115 on ChEMBL (p<0.001).
- The model produces diverse scaffolds, with median unique scaffold hits of 55.5 (GEOM-drugs) and 72 (ChEMBL), compared to 0 for baselines and 7-8.5 for PGMG.
- The fast search workflow reduces computational requirements by orders of magnitude while maintaining hit rates, enabling practical screening of billion-compound libraries like Enamine Real (60B compounds).
摘要: Ligand-based drug discovery (LBDD) relies on making use of known binders to a protein target to find structurally diverse molecules similarly likely to bind. This process typically involves a brute force search of the known binder (query) against a molecular library using some metric of molecular similarity. One popular approach overlays the pharmacophore-shape profile of the known binder to 3D conformations enumerated for each of the library molecules, computes overlaps, and picks a set of diverse library molecules with high overlaps. While this virtual screening workflow has had considerable success in hit diversification, scaffold hopping, and patent busting, it scales poorly with library sizes and restricts candidate generation to existing library compounds. Leveraging recent advances in voxel-based generative modelling, we propose a pharmacophore-based generative model and workflows that address the scaling and fecundity issues of conventional pharmacophore-based virtual screening. We introduce VoxCap, a voxel captioning method for generating SMILES strings from voxelised molecular representations.We propose two workflows as practical use cases as well as benchmarks for pharmacophore-based generation: de-novo design, in which we aim to generate new molecules with high pharmacophore-shape similarities to query molecules, and fast search, which aims to combine generative design with a cheap 2D substructure similarity search for efficient hit identification. Our results show that VoxCap significantly outperforms previous methods in generating diverse de-novo hits. When combined with our fast search workflow, VoxCap reduces computational time by orders of magnitude while returning hits for all query molecules, enabling the search of large libraries that are intractable to search by brute force.