
Paper List
-
Macroscopic Dominance from Microscopic Extremes: Symmetry Breaking in Spatial Competition
This paper addresses the fundamental question of how microscopic stochastic advantages in spatial exploration translate into macroscopic resource domi...
-
Linear Readout of Neural Manifolds with Continuous Variables
This paper addresses the core challenge of quantifying how the geometric structure of high-dimensional neural population activity (neural manifolds) d...
-
Theory of Cell Body Lensing and Phototaxis Sign Reversal in “Eyeless” Mutants of Chlamydomonas
This paper solves the core puzzle of how eyeless mutants of Chlamydomonas exhibit reversed phototaxis by quantitatively modeling the competition betwe...
-
Cross-Species Transfer Learning for Electrophysiology-to-Transcriptomics Mapping in Cortical GABAergic Interneurons
This paper addresses the challenge of predicting transcriptomic identity from electrophysiological recordings in human cortical interneurons, where li...
-
Uncovering statistical structure in large-scale neural activity with Restricted Boltzmann Machines
This paper addresses the core challenge of modeling large-scale neural population activity (1500-2000 neurons) with interpretable higher-order interac...
-
Realizing Common Random Numbers: Event-Keyed Hashing for Causally Valid Stochastic Models
This paper addresses the critical problem that standard stateful PRNG implementations in agent-based models violate causal validity by making random d...
-
A Standardized Framework for Evaluating Gene Expression Generative Models
This paper addresses the critical lack of standardized evaluation protocols for single-cell gene expression generative models, where inconsistent metr...
-
Single Molecule Localization Microscopy Challenge: A Biologically Inspired Benchmark for Long-Sequence Modeling
This paper addresses the core challenge of evaluating state-space models on biologically realistic, sparse, and stochastic temporal processes, which a...
DeepFRI Demystified: Interpretability vs. Accuracy in AI Protein Function Prediction
Yale University | Microsoft
30秒速读
IN SHORT: This study addresses the critical gap between high predictive accuracy and biological interpretability in DeepFRI, revealing that the model often prioritizes structural motifs over functional residues, complicating reliable identification of drug targets.
核心创新
- Methodology Comprehensive benchmarking of three post-hoc explainability methods (GradCAM, Excitation Backpropagation, PGExplainer) on DeepFRI with quantitative sparsity analysis.
- Methodology Development of a modified DeepFool adversarial testing framework for protein sequences, measuring mutation thresholds required for misclassification.
- Biology Revealed that DeepFRI prioritizes amino acids controlling protein structure over function in >50% of tested proteins, highlighting a fundamental accuracy-interpretability trade-off.
主要结论
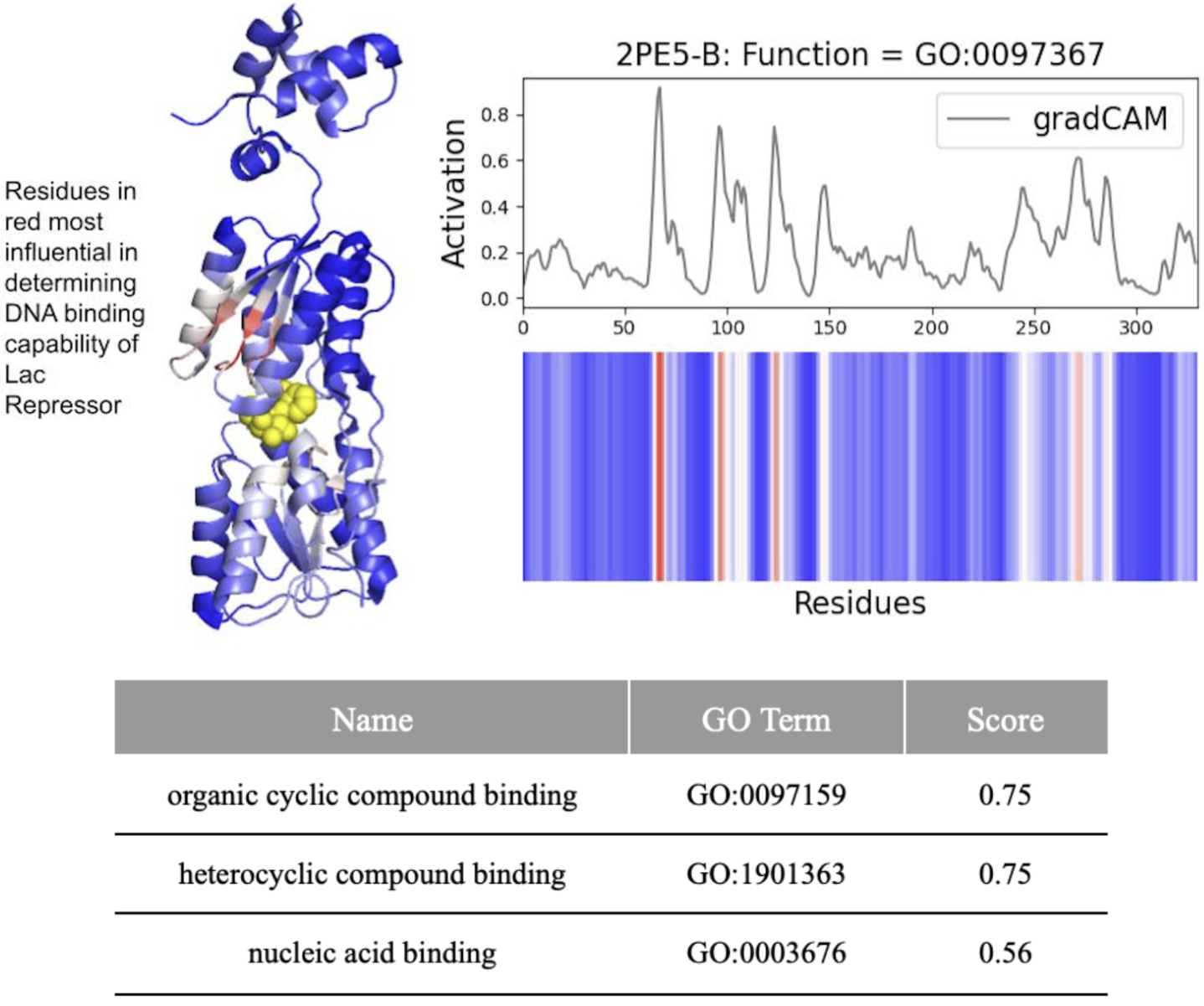
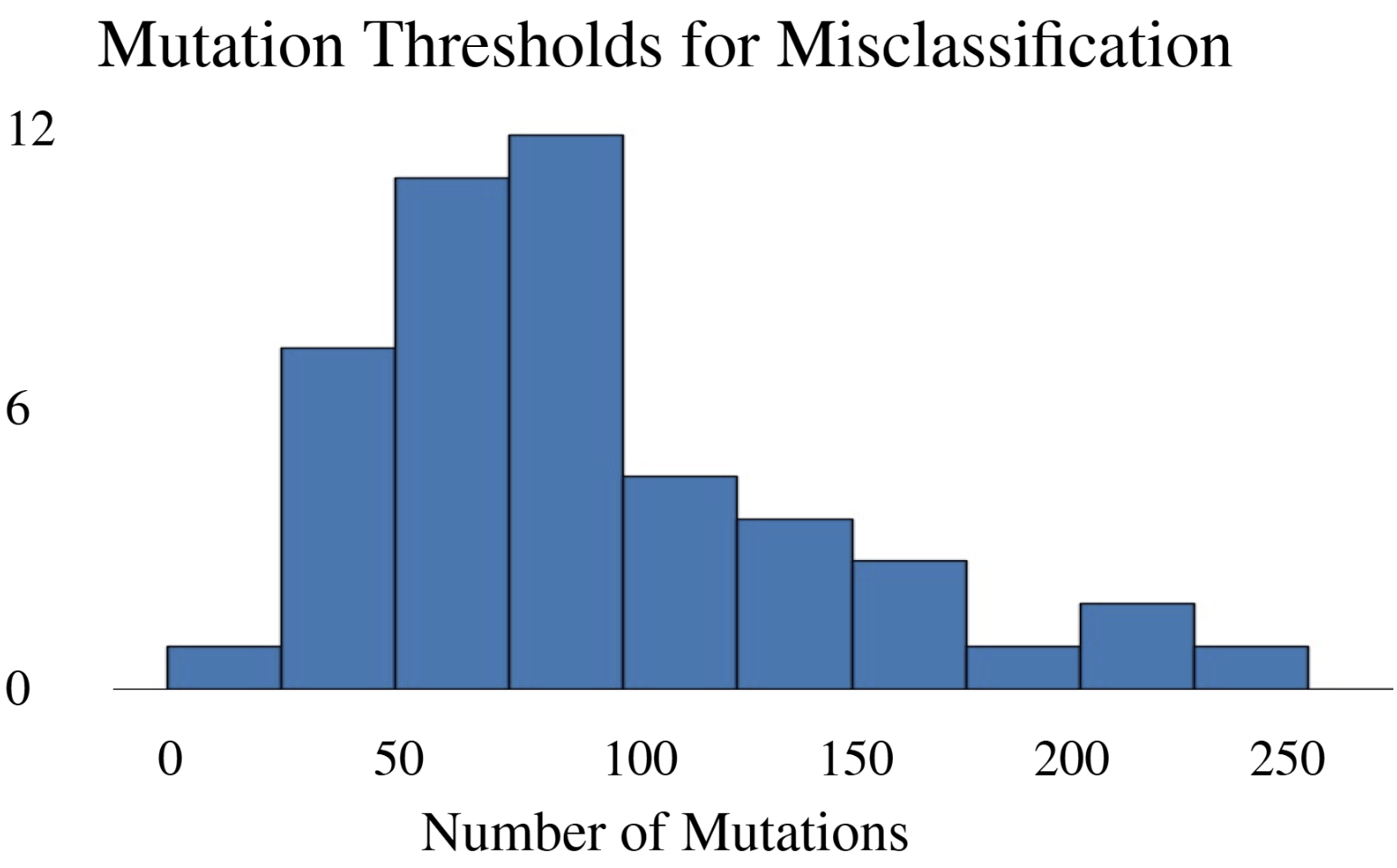
- DeepFRI required 206 mutations (62.4% of 330 residues) in the lac repressor for misclassification, demonstrating extreme robustness but potentially missing subtle functional alterations.
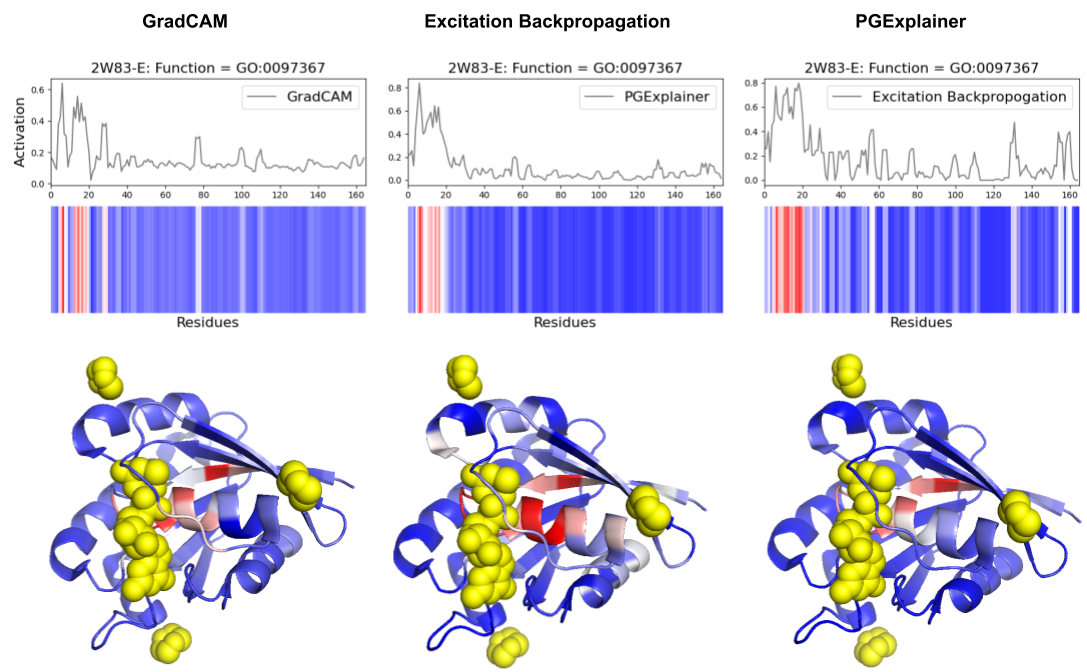
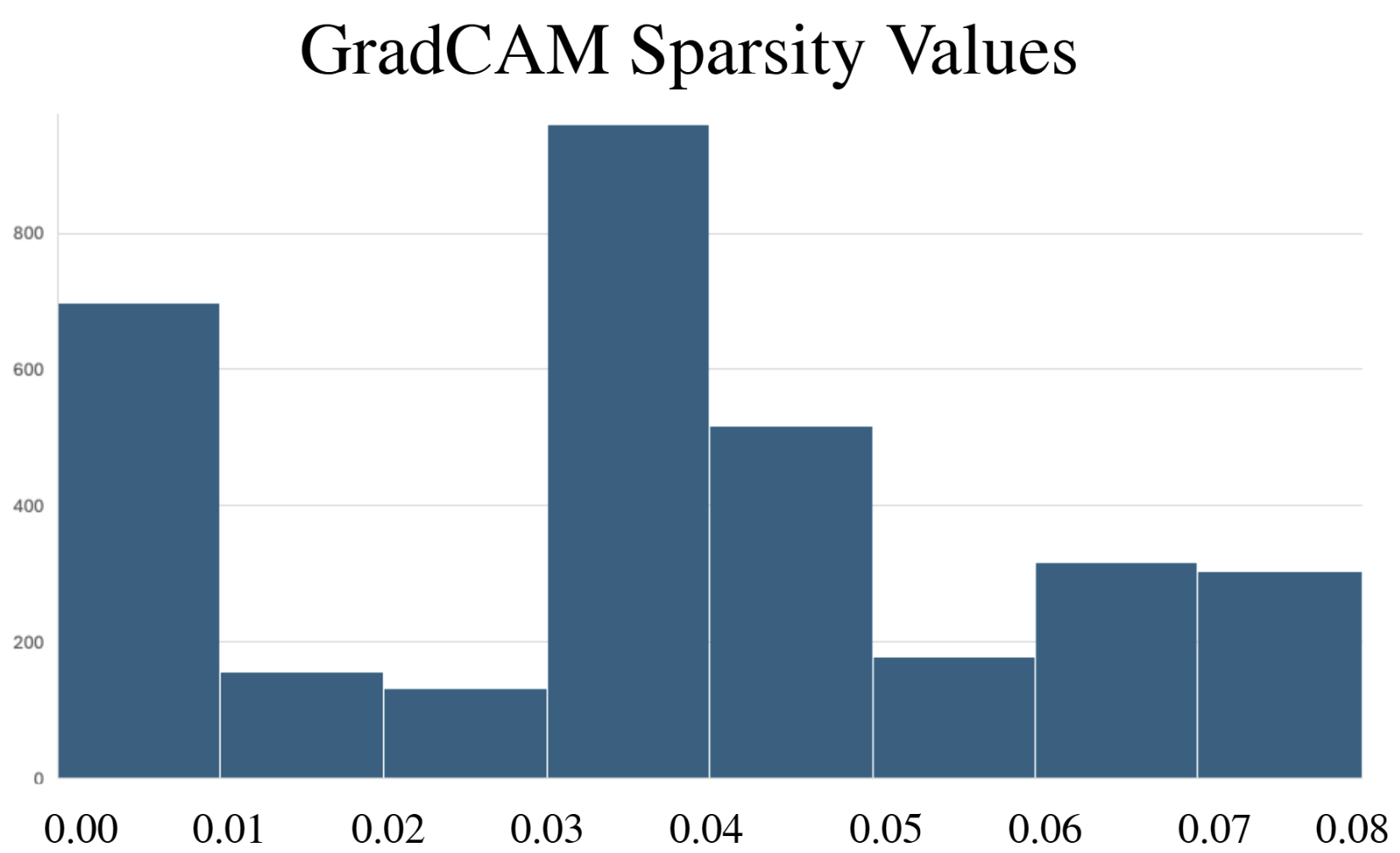
- Explainability methods showed significant granularity differences: PGExplainer was 3× sparser than GradCAM and 17× sparser than Excitation Backpropagation across 124 binding proteins.
- All three methods converged on biochemically critical P-loop residues (0-20) in ARF6 GTPase, validating DeepFRI's focus on conserved functional motifs in straightforward domains.
摘要: Machine learning technologies for protein function prediction are black box models. Despite their potential to identify key drug targets with high accuracy and accelerate therapy development, the adoption of these methods depends on verifying their findings. This study evaluates DeepFRI, a leading Graph Convolutional Network (GCN)-based tool, using advanced explainability techniques—GradCAM, Excitation Backpropagation, and PGExplainer—and adversarial robustness tests. Our findings reveal that the model’s predictions often prioritize conserved motifs over truly deterministic residues, complicating the identification of functional sites. Quantitative analyses show that explainability methods differ significantly in granularity, with GradCAM providing broad relevance and PGExplainer pinpointing specific active sites. These results highlight trade-offs between accuracy and interpretability, suggesting areas for improvement in DeepFRI’s architecture to enhance its trustworthiness in drug discovery and regulatory settings.