
Paper List
-
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to ide...
-
Unlocking hidden biomolecular conformational landscapes in diffusion models at inference time
This paper addresses the core challenge of efficiently and accurately sampling the conformational landscape of biomolecules from diffusion-based struc...
-
Personalized optimization of pediatric HD-tDCS for dose consistency and target engagement
This paper addresses the critical limitation of one-size-fits-all HD-tDCS protocols in pediatric populations by developing a personalized optimization...
-
Realistic Transition Paths for Large Biomolecular Systems: A Langevin Bridge Approach
This paper addresses the core challenge of generating physically realistic and computationally efficient transition paths between distinct protein con...
-
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the pe...
-
MoRSAIK: Sequence Motif Reactor Simulation, Analysis and Inference Kit in Python
This work addresses the computational bottleneck in simulating prebiotic RNA reactor dynamics by developing a Python package that tracks sequence moti...
-
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phyl...
-
EcoCast: A Spatio-Temporal Model for Continual Biodiversity and Climate Risk Forecasting
This paper addresses the critical bottleneck in conservation: the lack of timely, high-resolution, near-term forecasts of species distribution shifts ...
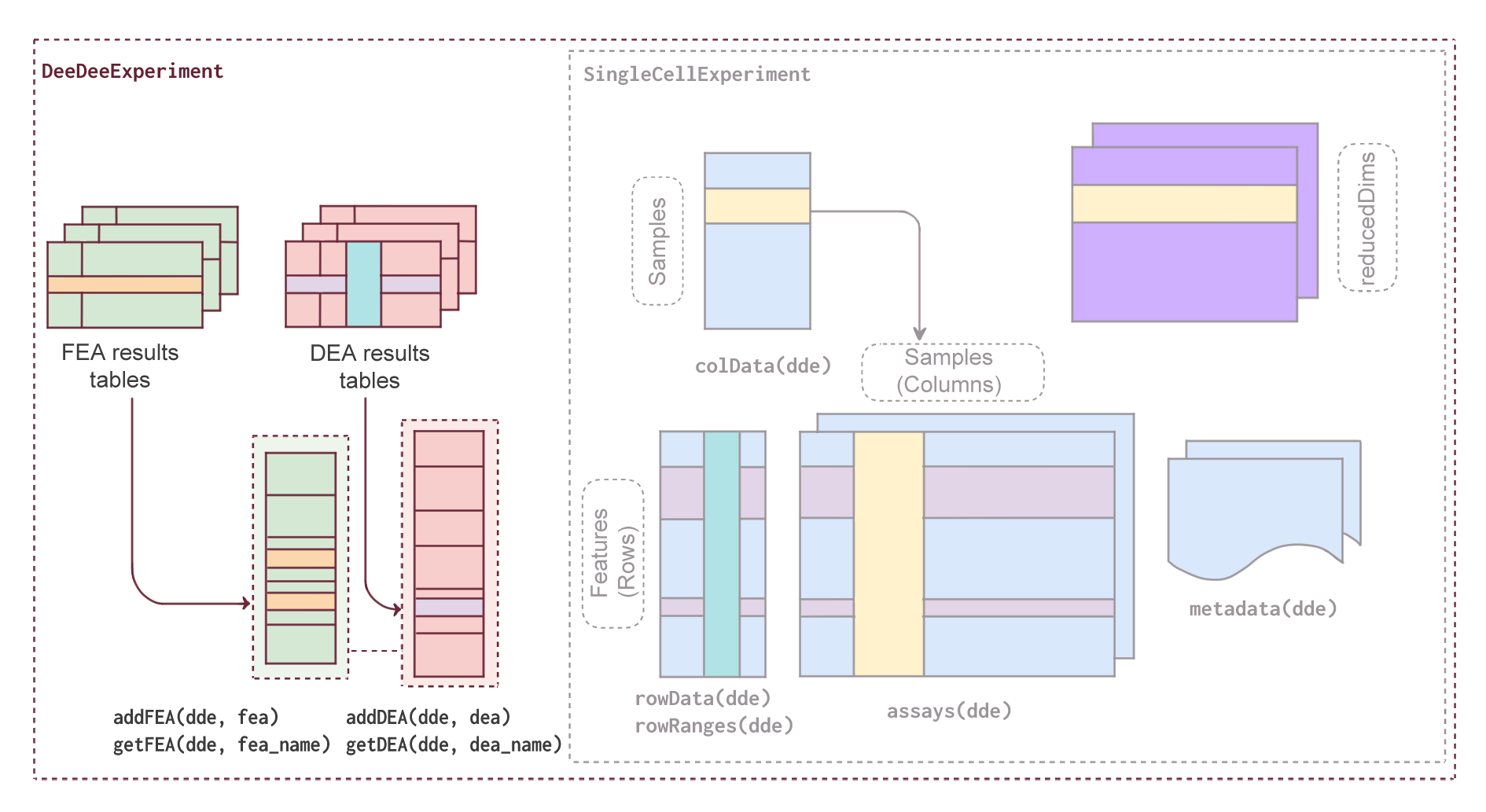
DeeDeeExperiment: Building an infrastructure for integrating and managing omics data analysis results in R/Bioconductor
Institute of Medical Biostatistics, Epidemiology and Informatics (IMBEI), University Medical Center Mainz | Research Center for Immunotherapy (FZI) Mainz | Department of Nephrology, Rheumatology and Kidney Transplantation, University Medical Center Mainz
30秒速读
IN SHORT: This paper addresses the critical bottleneck of managing and organizing the growing volume of differential expression and functional enrichment analysis results from complex omics experiments, which currently lack standardized data structures for storage and contextualization.
核心创新
- Methodology Introduces the first standardized S4 class specifically designed to co-store DEA and FEA results with their metadata in a single, structured container within the Bioconductor ecosystem.
- Methodology Extends the widely adopted SingleCellExperiment class by adding dedicated slots for DEA and FEA results while maintaining full backward compatibility with existing Bioconductor tools.
- Methodology Implements a contrast-centric architecture that organizes results from multiple comparisons (including limma multi-contrast objects and muscat pseudobulk analyses) with efficient storage through pointer-based referencing.
主要结论
- DeeDeeExperiment provides a robust, standardized framework that enables efficient organization and retrieval of DEA/FEA results across multiple contrasts within a single data object.
- The implementation maintains full compatibility with the Bioconductor ecosystem, supporting interoperability with downstream tools like scater for visualization and iSEE for interactive exploration.
- By consolidating analysis results and metadata, the framework supports more nuanced quantitative approaches beyond simple overlap strategies, enabling trustworthy summaries of complex experimental measurements.
摘要: Summary: Modern omics experiments now involve multiple conditions and complex designs, producing an increasingly large set of differential expression and functional enrichment analysis results. However, no standardized data structure exists to store and contextualize these results together with their metadata, leaving researchers with an unmanageable and potentially non-reproducible collection of results that are difficult to navigate and/or share. Here we introduce DeeDeeExperiment, a new S4 class for managing and storing omics data analysis results, implemented within the Bioconductor ecosystem, which promotes interoperability, reproducibility and good documentation. This class extends the widely used SingleCellExperiment object by introducing dedicated slots for Differential Expression (DEA) and Functional Enrichment Analysis (FEA) results, allowing users to organize, store, and retrieve information on multiple contrasts and associated metadata within a single data object, ultimately streamlining the management and interpretation of many omics datasets. Availability and implementation: DeeDeeExperiment is available on Bioconductor under the MIT license (https://bioconductor.org/packages/DeeDeeExperiment), with its development version also available on Github (https://github.com/imbeimainz/DeeDeeExperiment).