
Paper List
-
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to ide...
-
Unlocking hidden biomolecular conformational landscapes in diffusion models at inference time
This paper addresses the core challenge of efficiently and accurately sampling the conformational landscape of biomolecules from diffusion-based struc...
-
Personalized optimization of pediatric HD-tDCS for dose consistency and target engagement
This paper addresses the critical limitation of one-size-fits-all HD-tDCS protocols in pediatric populations by developing a personalized optimization...
-
Realistic Transition Paths for Large Biomolecular Systems: A Langevin Bridge Approach
This paper addresses the core challenge of generating physically realistic and computationally efficient transition paths between distinct protein con...
-
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the pe...
-
MoRSAIK: Sequence Motif Reactor Simulation, Analysis and Inference Kit in Python
This work addresses the computational bottleneck in simulating prebiotic RNA reactor dynamics by developing a Python package that tracks sequence moti...
-
On the Approximation of Phylogenetic Distance Functions by Artificial Neural Networks
This paper addresses the core challenge of developing computationally efficient and scalable neural network architectures that can learn accurate phyl...
-
EcoCast: A Spatio-Temporal Model for Continual Biodiversity and Climate Risk Forecasting
This paper addresses the critical bottleneck in conservation: the lack of timely, high-resolution, near-term forecasts of species distribution shifts ...
Hypothesis-Based Particle Detection for Accurate Nanoparticle Counting and Digital Diagnostics
Institute for Digital Molecular Analytics and Science (IDMxS), Nanyang Technological University, Singapore | School of Electrical and Electronic Engineering, Nanyang Technological University, Singapore
30秒速读
IN SHORT: This paper addresses the core challenge of achieving accurate, interpretable, and training-free nanoparticle counting in digital diagnostic assays, which is critical for detecting low-abundance biomarkers with high sensitivity.
核心创新
- Methodology Introduces a multiple-hypothesis statistical testing framework for particle counting, eliminating the need for empirical thresholds or training data common in traditional and ML-based methods.
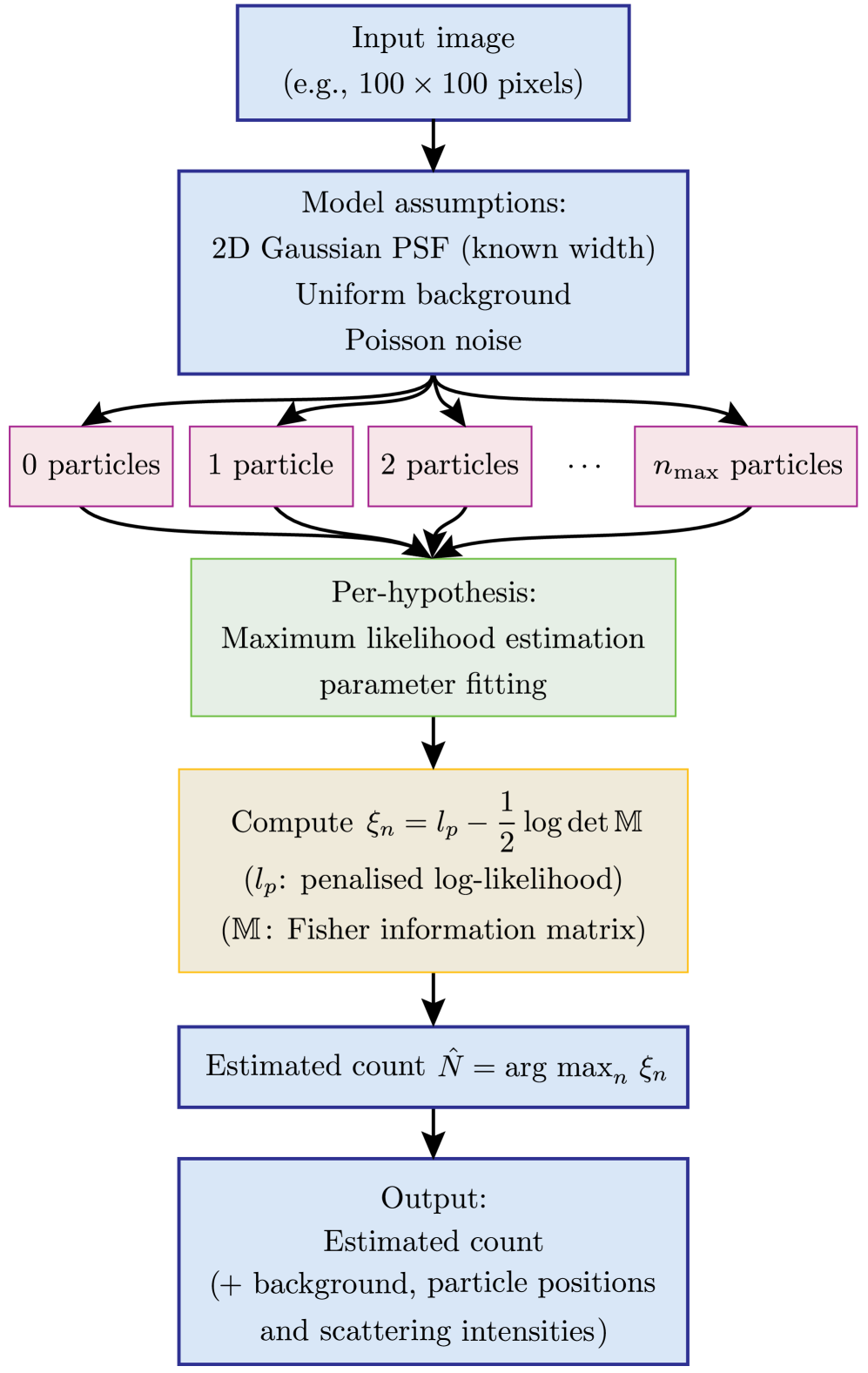
- Methodology Formulates the detection problem under an explicit image-formation model (Poisson noise, Gaussian PSF) and uses a penalized likelihood rule with an information-criterion complexity penalty for robust hypothesis selection.
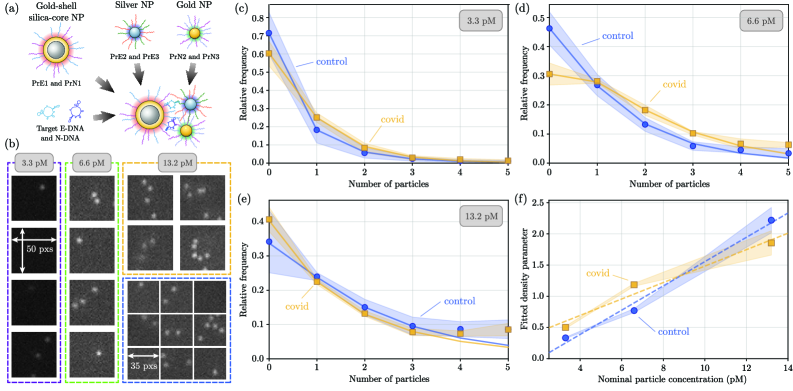
- Biology/Application Validates the method on experimental dark-field images of a nanoparticle-based assay for SARS-CoV-2 DNA biomarkers, demonstrating statistically significant differentiation between control and positive samples and providing insights into particle aggregation.
主要结论
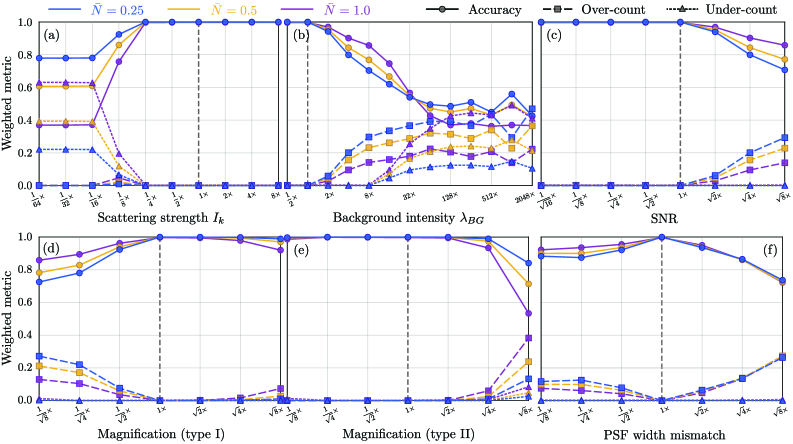
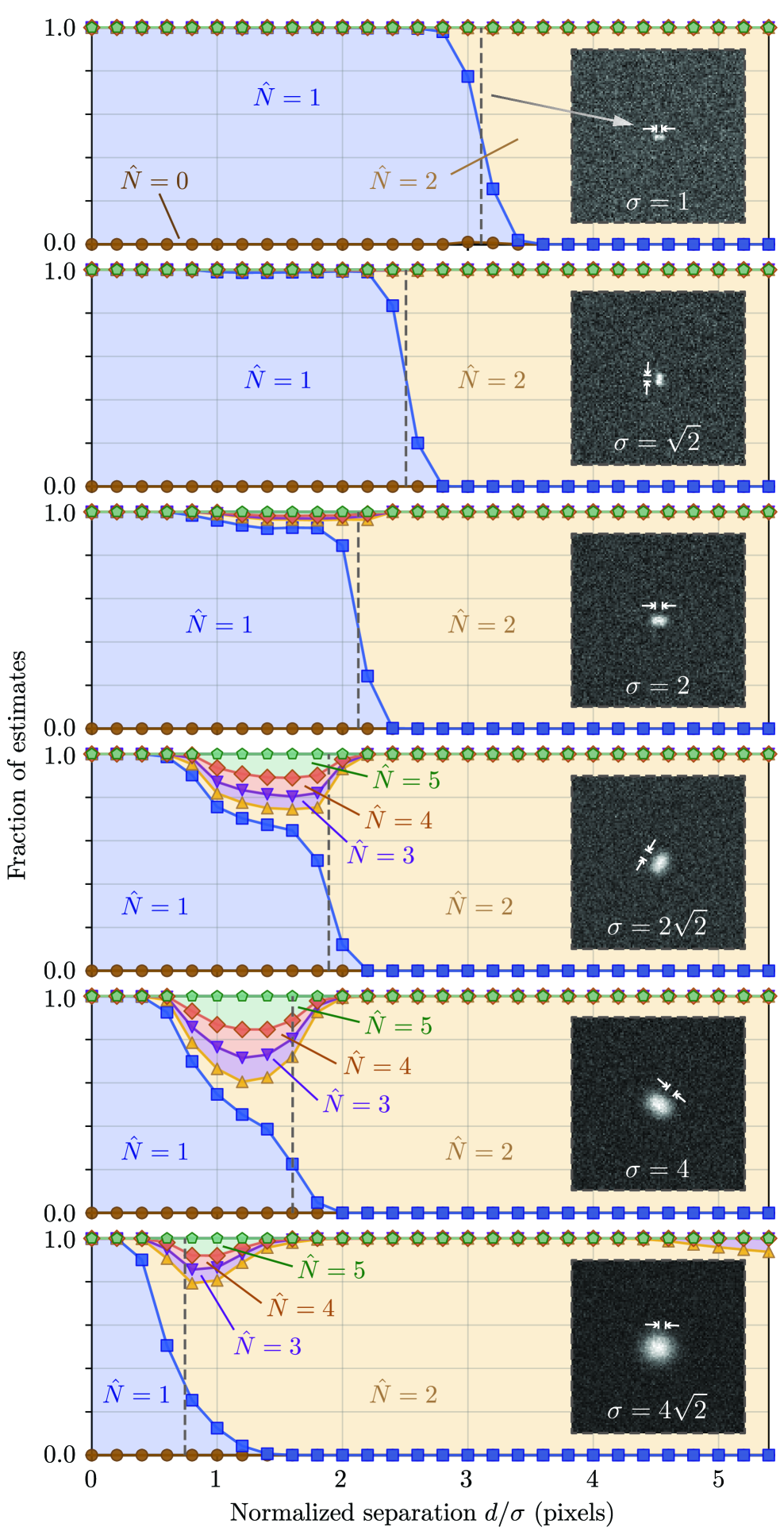
- The algorithm demonstrates robust count accuracy in simulations across challenging conditions: weak signals (low SBR), variable backgrounds, magnification changes, and moderate PSF mismatch.
- Applied to experimental SARS-CoV-2 biomarker detection, the method revealed statistically significant differences in particle count distributions between control and positive samples, confirming practical utility.
- Full count statistics from the experimental assay exhibited consistent over-dispersion, providing quantitative insight into non-specific and target-induced nanoparticle aggregation phenomena.
摘要: Digital assays represent a shift from traditional diagnostics and enable the precise detection of low-abundance analytes, critical for early disease diagnosis and personalized medicine, through discrete counting of biomolecular reporters. Within this paradigm, we present a particle counting algorithm for nanoparticle based imaging assays, formulated as a multiple-hypothesis statistical test under an explicit image-formation model and evaluated using a penalized likelihood rule. In contrast to thresholding or machine learning methods, this approach requires no training data or empirical parameter tuning, and its outputs remain interpretable through direct links to imaging physics and statistical decision theory. Through numerical simulations we demonstrate robust count accuracy across weak signals, variable backgrounds, magnification changes and moderate PSF mismatch. Particle resolvability tests further reveal characteristic error modes, including under-counting at very small separations and localized over-counting near the resolution limit. Practically, we also confirm the algorithm’s utility, through application to experimental dark-field images comprising a nanoparticle-based assay for detection of DNA biomarkers derived from SARS-CoV-2. Statistically significant differences in particle count distributions are observed between control and positive samples. Full count statistics obtained further exhibit consistent over-dispersion, and provide insight into non-specific and target-induced particle aggregation. These results establish our method as a reliable framework for nanoparticle-based detection assays in digital molecular diagnostics.