
Paper List
-
GOPHER: Optimization-based Phenotype Randomization for Genome-Wide Association Studies with Differential Privacy
This paper addresses the core challenge of balancing rigorous privacy protection with data utility when releasing full GWAS summary statistics, overco...
-
Real-time Cricket Sorting By Sex A low-cost embedded solution using YOLOv8 and Raspberry Pi
This paper addresses the critical bottleneck in industrial insect farming: the lack of automated, real-time sex sorting systems for Acheta domesticus ...
-
Training Dynamics of Learning 3D-Rotational Equivariance
This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with dat...
-
Fast and Accurate Node-Age Estimation Under Fossil Calibration Uncertainty Using the Adjusted Pairwise Likelihood
This paper addresses the dual challenge of computational inefficiency and sensitivity to fossil calibration errors in Bayesian divergence time estimat...
-
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collecti...
-
scCluBench: Comprehensive Benchmarking of Clustering Algorithms for Single-Cell RNA Sequencing
This paper addresses the critical gap of fragmented and non-standardized benchmarking in single-cell RNA-seq clustering, which hinders objective compa...
-
Simulation and inference methods for non-Markovian stochastic biochemical reaction networks
This paper addresses the computational bottleneck of simulating and performing Bayesian inference for non-Markovian biochemical systems with history-d...
-
Assessment of Simulation-based Inference Methods for Stochastic Compartmental Models
This paper addresses the core challenge of performing accurate Bayesian parameter inference for stochastic epidemic models when the likelihood functio...
Hypothesis-Based Particle Detection for Accurate Nanoparticle Counting and Digital Diagnostics
Institute for Digital Molecular Analytics and Science (IDMxS), Nanyang Technological University, Singapore | School of Electrical and Electronic Engineering, Nanyang Technological University, Singapore
30秒速读
IN SHORT: This paper addresses the core challenge of achieving accurate, interpretable, and training-free nanoparticle counting in digital diagnostic assays, which is critical for detecting low-abundance biomarkers with high sensitivity.
核心创新
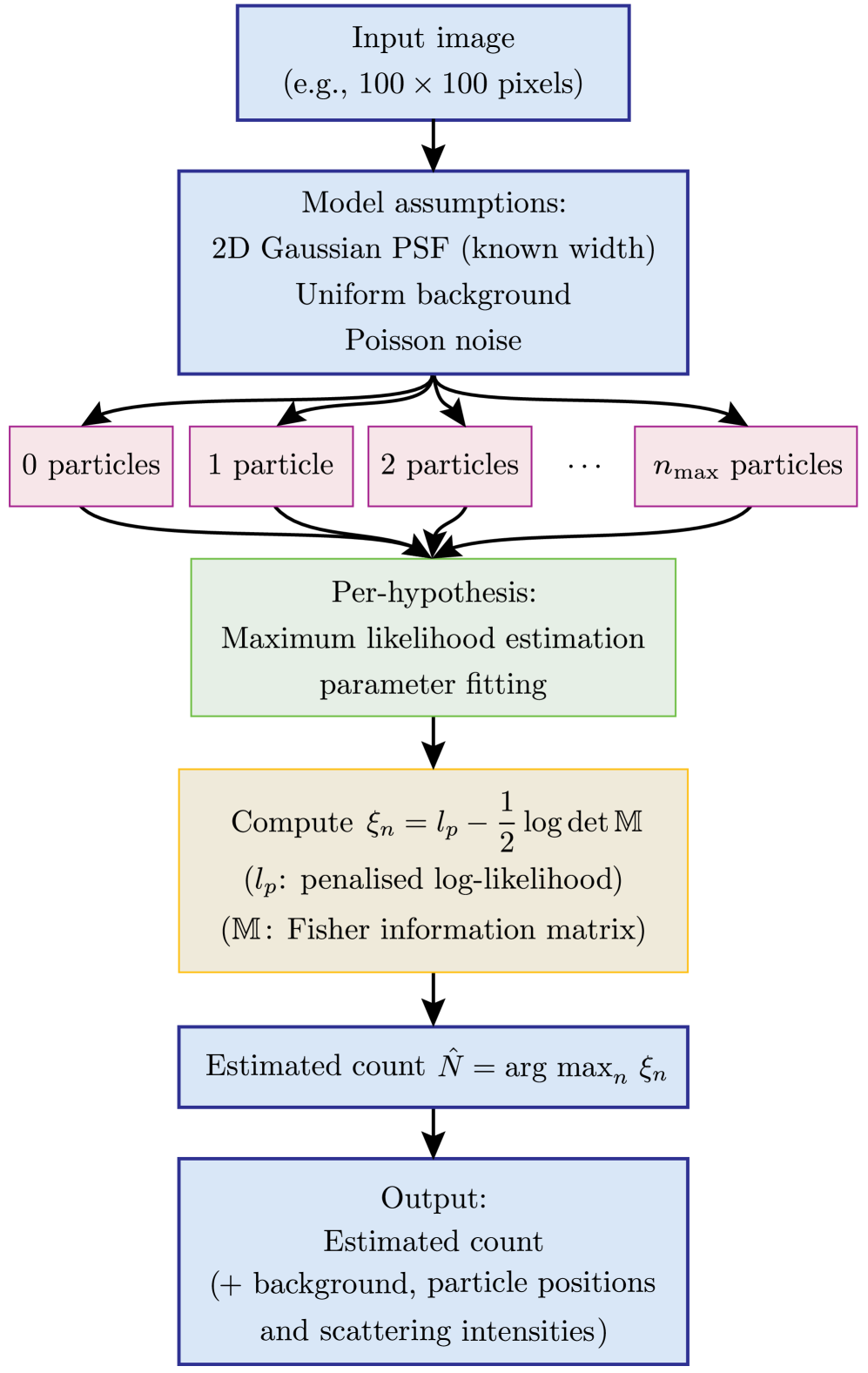
- Methodology Introduces a multiple-hypothesis statistical testing framework for particle counting, eliminating the need for empirical thresholds or training data common in traditional and ML-based methods.
- Methodology Formulates the detection problem under an explicit image-formation model (Poisson noise, Gaussian PSF) and uses a penalized likelihood rule with an information-criterion complexity penalty for robust hypothesis selection.
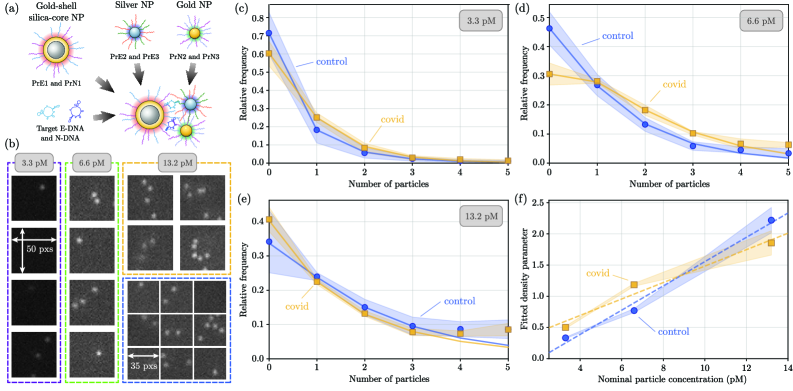
- Biology/Application Validates the method on experimental dark-field images of a nanoparticle-based assay for SARS-CoV-2 DNA biomarkers, demonstrating statistically significant differentiation between control and positive samples and providing insights into particle aggregation.
主要结论
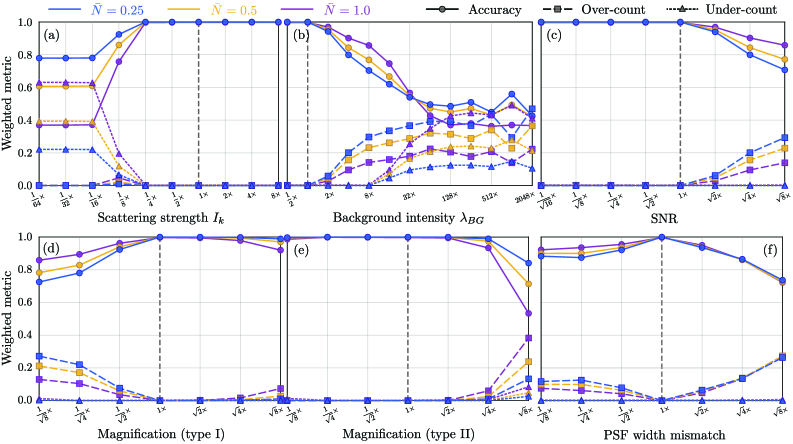
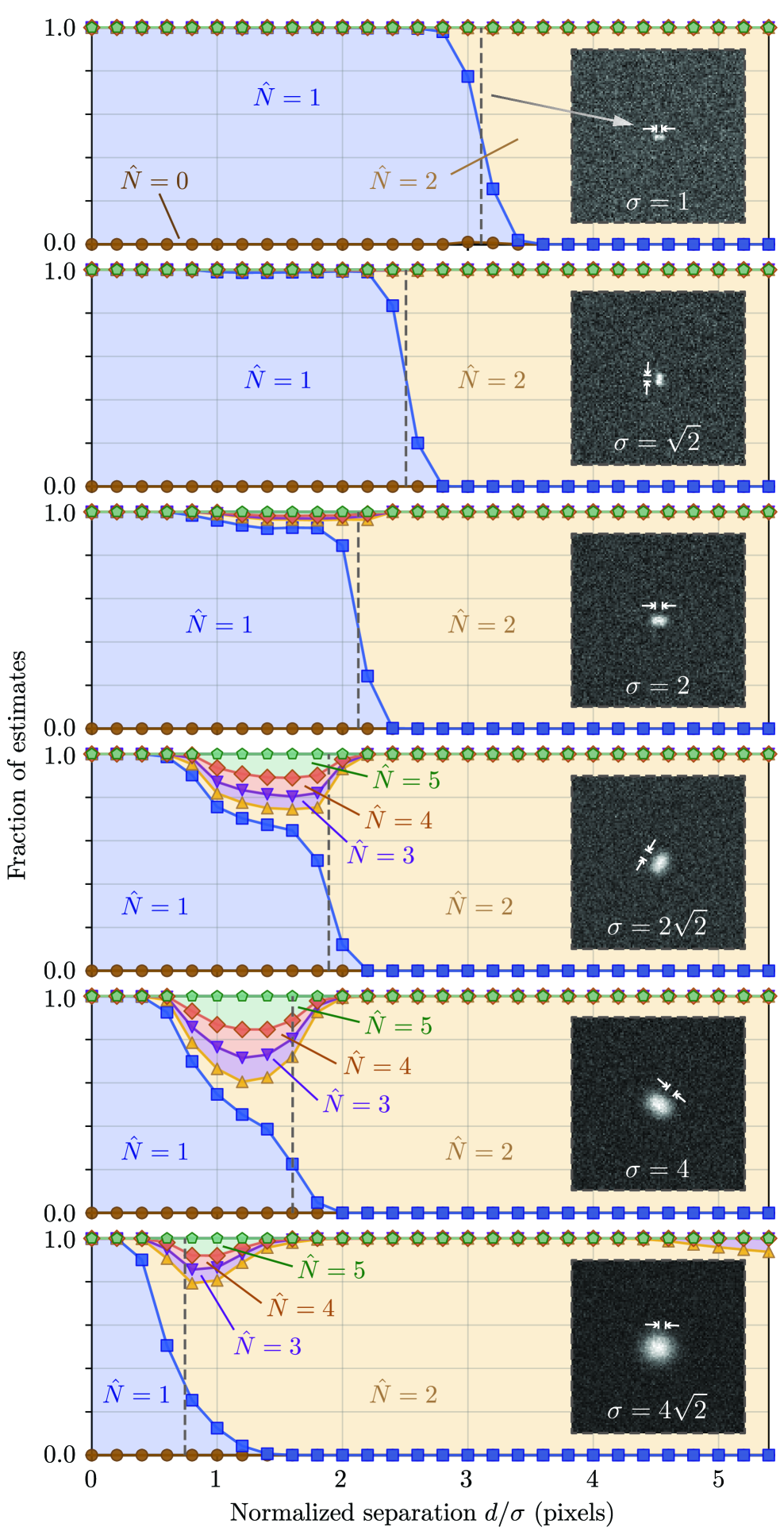
- The algorithm demonstrates robust count accuracy in simulations across challenging conditions: weak signals (low SBR), variable backgrounds, magnification changes, and moderate PSF mismatch.
- Applied to experimental SARS-CoV-2 biomarker detection, the method revealed statistically significant differences in particle count distributions between control and positive samples, confirming practical utility.
- Full count statistics from the experimental assay exhibited consistent over-dispersion, providing quantitative insight into non-specific and target-induced nanoparticle aggregation phenomena.
摘要: Digital assays represent a shift from traditional diagnostics and enable the precise detection of low-abundance analytes, critical for early disease diagnosis and personalized medicine, through discrete counting of biomolecular reporters. Within this paradigm, we present a particle counting algorithm for nanoparticle based imaging assays, formulated as a multiple-hypothesis statistical test under an explicit image-formation model and evaluated using a penalized likelihood rule. In contrast to thresholding or machine learning methods, this approach requires no training data or empirical parameter tuning, and its outputs remain interpretable through direct links to imaging physics and statistical decision theory. Through numerical simulations we demonstrate robust count accuracy across weak signals, variable backgrounds, magnification changes and moderate PSF mismatch. Particle resolvability tests further reveal characteristic error modes, including under-counting at very small separations and localized over-counting near the resolution limit. Practically, we also confirm the algorithm’s utility, through application to experimental dark-field images comprising a nanoparticle-based assay for detection of DNA biomarkers derived from SARS-CoV-2. Statistically significant differences in particle count distributions are observed between control and positive samples. Full count statistics obtained further exhibit consistent over-dispersion, and provide insight into non-specific and target-induced particle aggregation. These results establish our method as a reliable framework for nanoparticle-based detection assays in digital molecular diagnostics.