
Paper List
-
GOPHER: Optimization-based Phenotype Randomization for Genome-Wide Association Studies with Differential Privacy
This paper addresses the core challenge of balancing rigorous privacy protection with data utility when releasing full GWAS summary statistics, overco...
-
Real-time Cricket Sorting By Sex A low-cost embedded solution using YOLOv8 and Raspberry Pi
This paper addresses the critical bottleneck in industrial insect farming: the lack of automated, real-time sex sorting systems for Acheta domesticus ...
-
Training Dynamics of Learning 3D-Rotational Equivariance
This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with dat...
-
Fast and Accurate Node-Age Estimation Under Fossil Calibration Uncertainty Using the Adjusted Pairwise Likelihood
This paper addresses the dual challenge of computational inefficiency and sensitivity to fossil calibration errors in Bayesian divergence time estimat...
-
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collecti...
-
scCluBench: Comprehensive Benchmarking of Clustering Algorithms for Single-Cell RNA Sequencing
This paper addresses the critical gap of fragmented and non-standardized benchmarking in single-cell RNA-seq clustering, which hinders objective compa...
-
Simulation and inference methods for non-Markovian stochastic biochemical reaction networks
This paper addresses the computational bottleneck of simulating and performing Bayesian inference for non-Markovian biochemical systems with history-d...
-
Assessment of Simulation-based Inference Methods for Stochastic Compartmental Models
This paper addresses the core challenge of performing accurate Bayesian parameter inference for stochastic epidemic models when the likelihood functio...
Incorporating indel channels into average-case analysis of seed-chain-extend
Carnegie Mellon University, Pittsburgh, PA, USA
30秒速读
IN SHORT: This paper addresses the core pain point of bridging the theoretical gap for the widely used seed-chain-extend heuristic by providing the first rigorous average-case analysis that accounts for insertions and deletions (indels), not just substitutions.
核心创新
- Methodology Introduces a generalized definition of 'recoverability' and a 'homologous path' to mathematically model the correct alignment under indel mutation channels, moving beyond the simpler 'homologous diagonal' used for substitutions only.
- Theory Develops new mathematical machinery to handle the dependence structure of neighboring anchors and the existence of 'clipping anchors' (partially correct anchors), which are unique challenges introduced by indels.
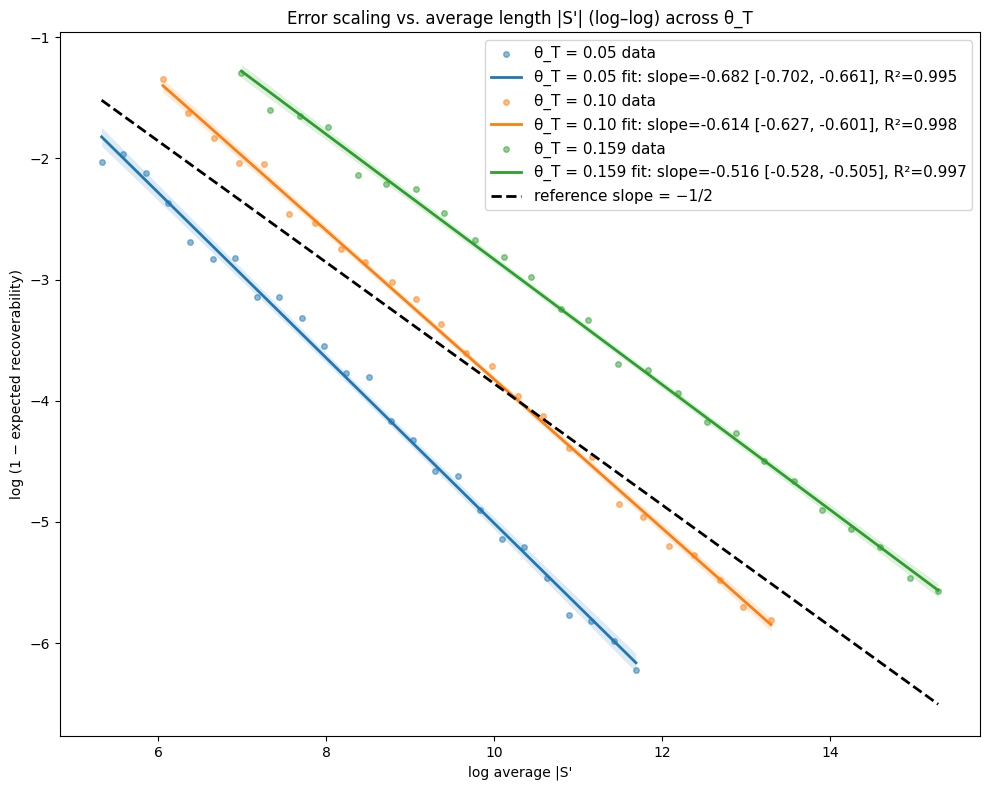
- Theory Proves that under a total mutation rate θ_T < 0.159, optimal linear-gap cost chaining achieves an expected recoverability of ≥ 1 - O(1/√m), generalizing the prior substitution-only result to a biologically realistic model.
主要结论
- The expected recoverability of an optimal chain under linear-gap cost chaining is ≥ 1 - O(1/√m) when the total mutation rate θ_T (sum of substitution, insertion, deletion rates) is less than 0.159.
- The expected runtime of the algorithm is O(m n^(3.15·θ_T) log n). For example, at a θ_T of 0.05 (similar to human-chimp divergence), the exponent is ~1.12, leading to near-linear scaling.
- The analysis successfully bridges theory and practice by extending the proof framework to handle indels, justifying the heuristic's empirical effectiveness on real genomic data which contains indels.
摘要: Given a sequence s1 of n letters drawn i.i.d. from an alphabet of size σ and a mutated substring s2 of length m<n, we often want to recover the mutation history that generated s2 from s1. Modern sequence aligners are widely used for this task, and many employ the seed-chain-extend heuristic with k-mer seeds. Previously, Shaw and Yu showed that optimal linear-gap cost chaining can produce a chain with 1−O(1/m) recoverability, the proportion of the mutation history that is recovered, in O(mn^(2.43θ) log n) expected time, where θ<0.206 is the mutation rate under a substitution-only channel and s1 is assumed to be uniformly random. However, a gap remains between theory and practice, since real genomic data includes insertions and deletions (indels), and yet seed-chain-extend remains effective. In this paper, we generalize those prior results by introducing mathematical machinery to deal with the two new obstacles introduced by indel channels: the dependence of neighboring anchors and the presence of anchors that are only partially correct. We are thus able to prove that the expected recoverability of an optimal chain is ≥1−O(1/√m) and the expected runtime is O(mn^(3.15·θ_T) log n), when the total mutation rate given by the sum of the substitution, insertion, and deletion mutation rates (θ_T = θ_i + θ_d + θ_s) is less than 0.159.