
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
Unlocking hidden biomolecular conformational landscapes in diffusion models at inference time
Stanford University | Yale School of Medicine

30秒速读
IN SHORT: This paper addresses the core challenge of efficiently and accurately sampling the conformational landscape of biomolecules from diffusion-based structure prediction models, which typically output highly concentrated distributions around a single static structure.
核心创新
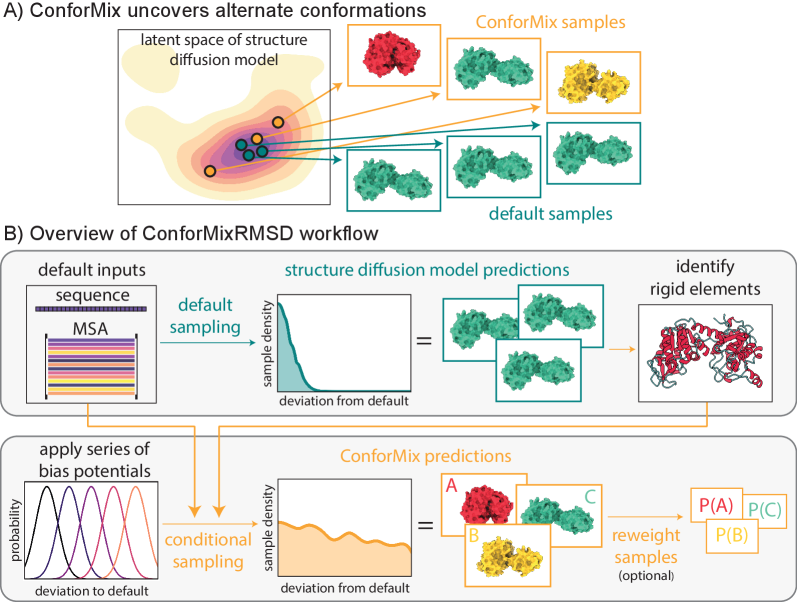
- Methodology Introduces ConforMix, a novel inference-time algorithm combining twisted sequential Monte Carlo (SMC) with automated exploration of the diffusion landscape, enabling asymptotically exact sampling of conditional distributions without additional model training.
- Methodology Presents ConforMixRMSD, an instantiation for automated exploration that biases sampling away from the default prediction using RMSD-based potentials on rigid secondary structure elements, recovering diverse conformations without prior knowledge of degrees of freedom.
- Methodology Applies the multistate Bennett acceptance ratio (MBAR) free energy estimation algorithm to diffusion models for the first time, enabling reconstruction of the unbiased model landscape from conditional samples.
主要结论
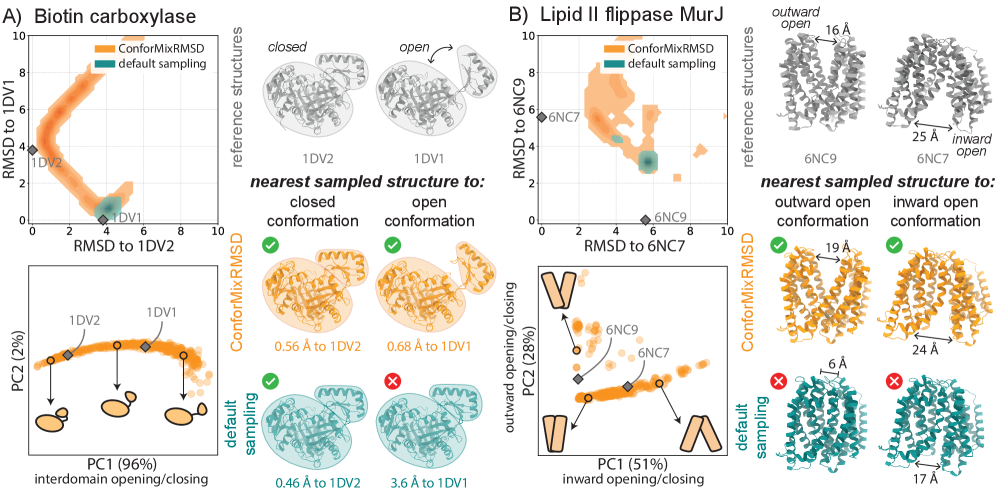
- ConforMixRMSD applied to Boltz-1 (an AlphaFold 3-like model) significantly outperforms MSA-modification baselines (AFCluster, AFSample2, CF-random) in recovering experimentally observed alternative conformations for domain motion (coverage: 0.69 ± 0.15 vs. 0.51 ± 0.17 for best baseline), membrane transporter (0.33 ± 0.23 vs. 0.20 ± 0.20), and cryptic pocket (0.45 ± 0.18 vs. 0.39 ± 0.16) protein sets, as measured by coverage at 50% of reference-to-reference RMSD.
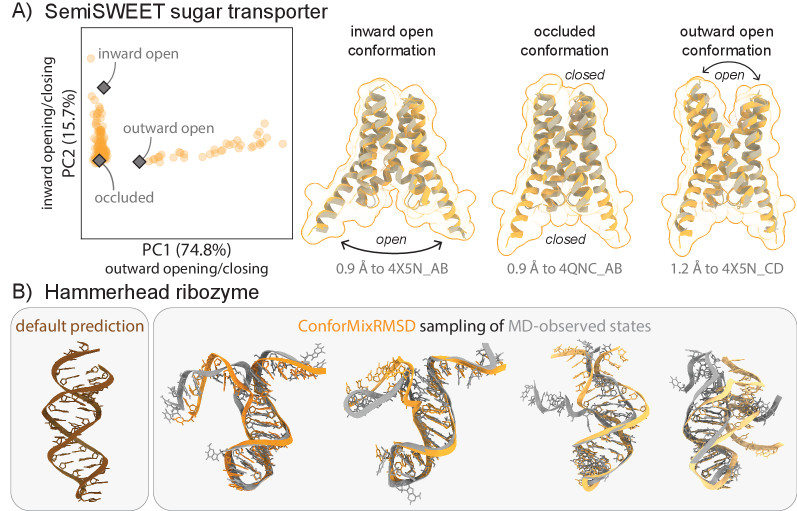
- The method captures biologically relevant conformational transitions (domain motion, transporter cycling, cryptic pocket flexibility) while avoiding unphysical states through filtering based on pLDDT values and clash detection, demonstrating its utility for exploring continuous transitions.
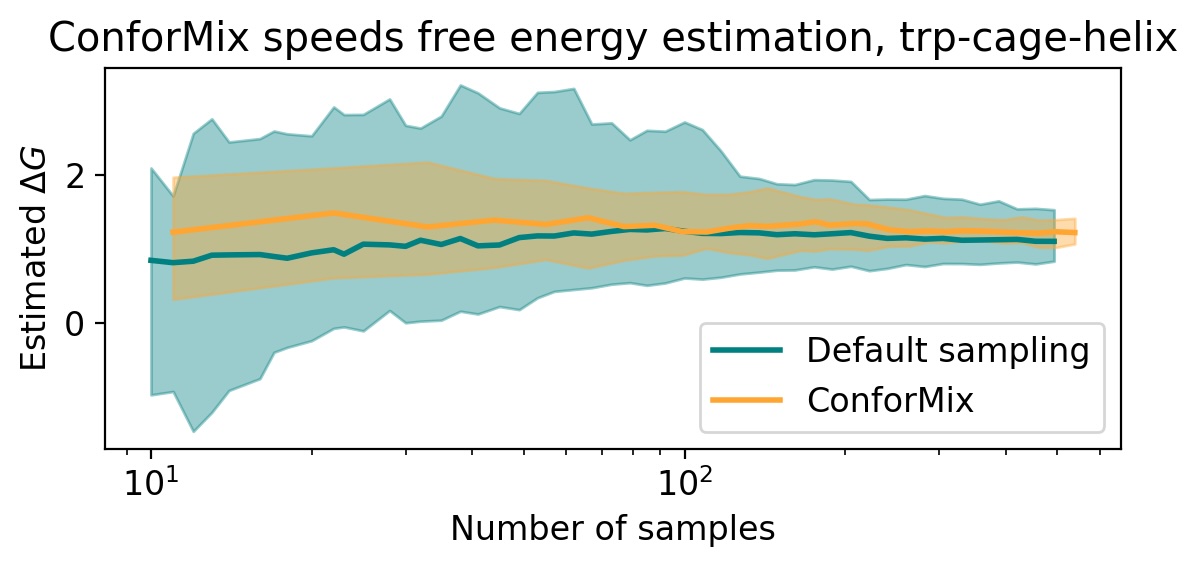
- ConforMix enables efficient free energy estimation when applied to models like BioEmu, boosting the speed of such calculations, and its framework is orthogonal to model pretraining improvements, meaning it would benefit even a hypothetical model that perfectly reproduces the Boltzmann distribution.
摘要: The function of biomolecules such as proteins depends on their ability to interconvert between a wide range of structures or “conformations.” Researchers have endeavored for decades to develop computational methods to predict the distribution of conformations, which is far harder to determine experimentally than a static folded structure. We present ConforMix, an inference-time algorithm that enhances sampling of conformational distributions using a combination of classifier guidance, filtering, and free energy estimation. Our approach upgrades diffusion models—whether trained for static structure prediction or conformational generation—to enable more efficient discovery of conformational variability without requiring prior knowledge of major degrees of freedom. ConforMix is orthogonal to improvements in model pretraining and would benefit even a hypothetical model that perfectly reproduced the Boltzmann distribution. Remarkably, when applied to a diffusion model trained for static structure prediction, ConforMix captures structural changes including domain motion, cryptic pocket flexibility, and transporter cycling, while avoiding unphysical states. Case studies of biologically critical proteins demonstrate the scalability, accuracy, and utility of this method.