
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
DeepFRI Demystified: Interpretability vs. Accuracy in AI Protein Function Prediction
Yale University | Microsoft
30秒速读
IN SHORT: This study addresses the critical gap between high predictive accuracy and biological interpretability in DeepFRI, revealing that the model often prioritizes structural motifs over functional residues, complicating reliable identification of drug targets.
核心创新
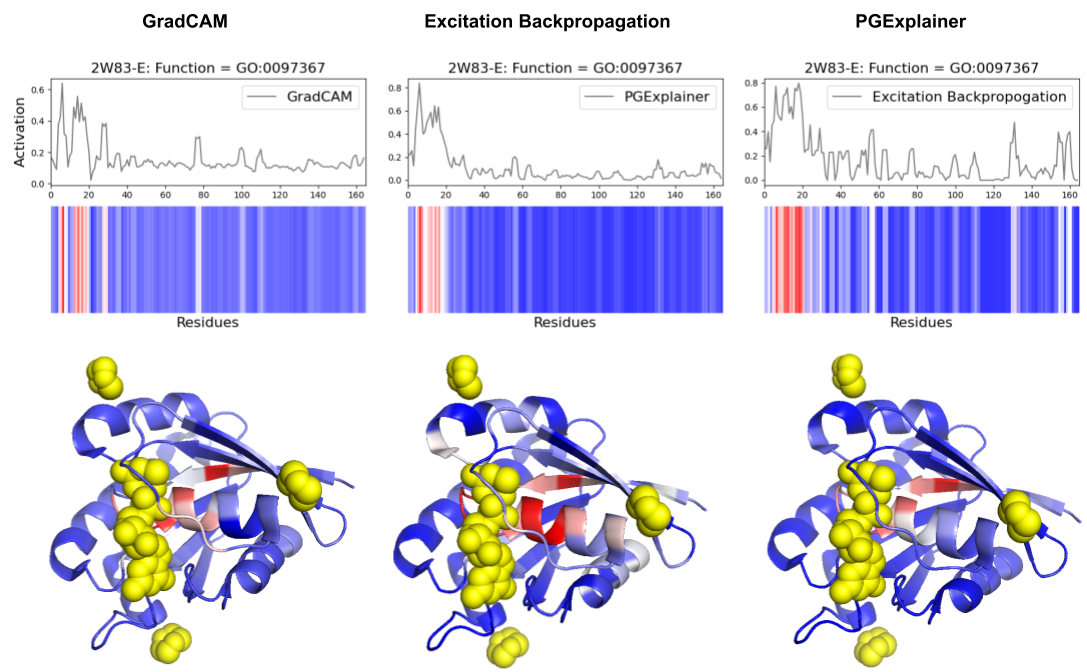
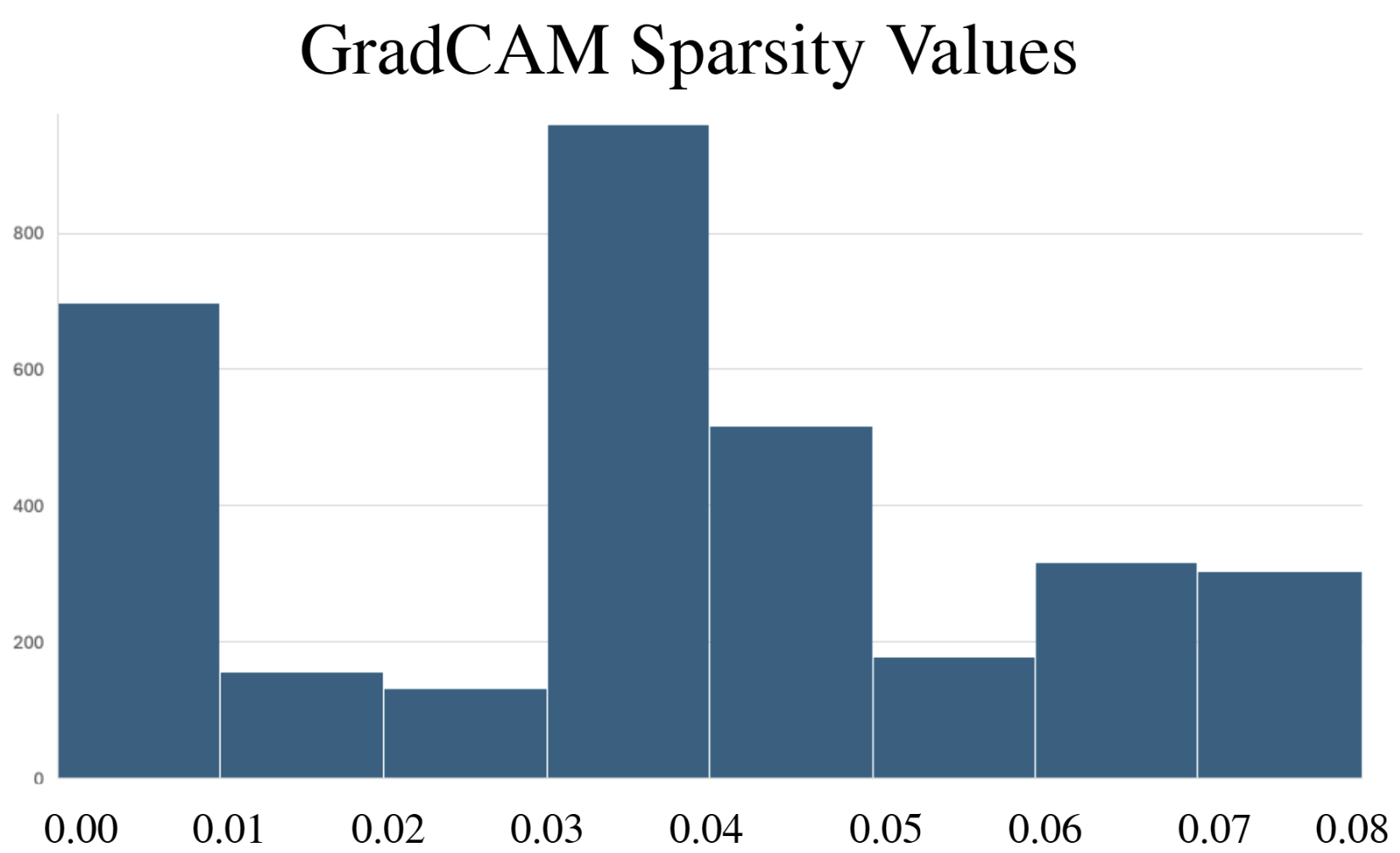
- Methodology Comprehensive benchmarking of three post-hoc explainability methods (GradCAM, Excitation Backpropagation, PGExplainer) on DeepFRI with quantitative sparsity analysis.
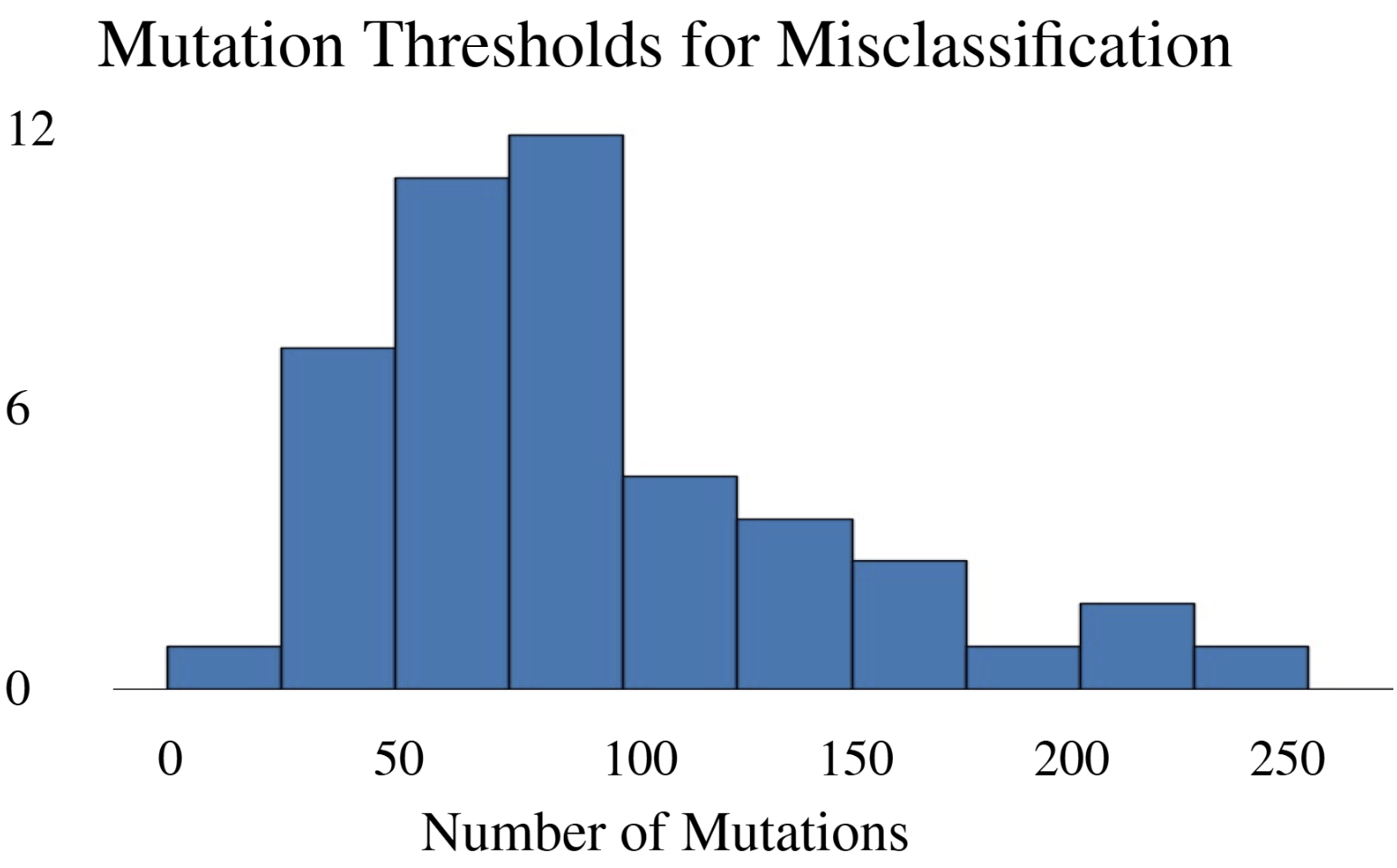
- Methodology Development of a modified DeepFool adversarial testing framework for protein sequences, measuring mutation thresholds required for misclassification.
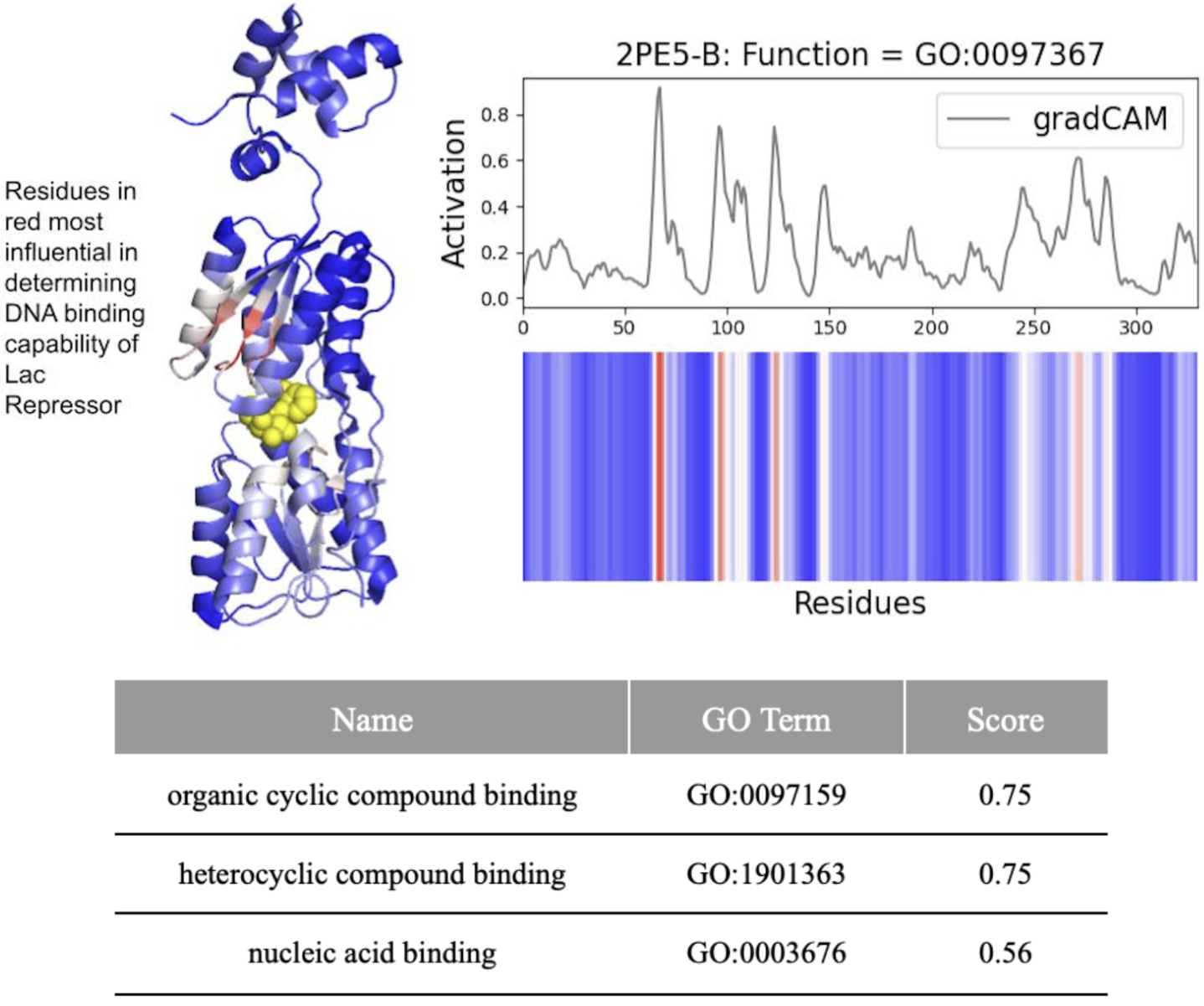
- Biology Revealed that DeepFRI prioritizes amino acids controlling protein structure over function in >50% of tested proteins, highlighting a fundamental accuracy-interpretability trade-off.
主要结论
- DeepFRI required 206 mutations (62.4% of 330 residues) in the lac repressor for misclassification, demonstrating extreme robustness but potentially missing subtle functional alterations.
- Explainability methods showed significant granularity differences: PGExplainer was 3× sparser than GradCAM and 17× sparser than Excitation Backpropagation across 124 binding proteins.
- All three methods converged on biochemically critical P-loop residues (0-20) in ARF6 GTPase, validating DeepFRI's focus on conserved functional motifs in straightforward domains.
摘要: Machine learning technologies for protein function prediction are black box models. Despite their potential to identify key drug targets with high accuracy and accelerate therapy development, the adoption of these methods depends on verifying their findings. This study evaluates DeepFRI, a leading Graph Convolutional Network (GCN)-based tool, using advanced explainability techniques—GradCAM, Excitation Backpropagation, and PGExplainer—and adversarial robustness tests. Our findings reveal that the model’s predictions often prioritize conserved motifs over truly deterministic residues, complicating the identification of functional sites. Quantitative analyses show that explainability methods differ significantly in granularity, with GradCAM providing broad relevance and PGExplainer pinpointing specific active sites. These results highlight trade-offs between accuracy and interpretability, suggesting areas for improvement in DeepFRI’s architecture to enhance its trustworthiness in drug discovery and regulatory settings.