
Paper List
-
Ill-Conditioning in Dictionary-Based Dynamic-Equation Learning: A Systems Biology Case Study
This paper addresses the critical challenge of numerical ill-conditioning and multicollinearity in library-based sparse regression methods (e.g., SIND...
-
Hybrid eTFCE–GRF: Exact Cluster-Size Retrieval with Analytical pp-Values for Voxel-Based Morphometry
This paper addresses the computational bottleneck in voxel-based neuroimaging analysis by providing a method that delivers exact cluster-size retrieva...
-
abx_amr_simulator: A simulation environment for antibiotic prescribing policy optimization under antimicrobial resistance
This paper addresses the critical challenge of quantitatively evaluating antibiotic prescribing policies under realistic uncertainty and partial obser...
-
PesTwin: a biology-informed Digital Twin for enabling precision farming
This paper addresses the critical bottleneck in precision agriculture: the inability to accurately forecast pest outbreaks in real-time, leading to su...
-
Equivariant Asynchronous Diffusion: An Adaptive Denoising Schedule for Accelerated Molecular Conformation Generation
This paper addresses the core challenge of generating physically plausible 3D molecular structures by bridging the gap between autoregressive methods ...
-
Omics Data Discovery Agents
This paper addresses the core challenge of making published omics data computationally reusable by automating the extraction, quantification, and inte...
-
Single-cell directional sensing at ultra-low chemoattractant concentrations from extreme first-passage events
This work addresses the core challenge of how a cell can rapidly and accurately determine the direction of a chemoattractant source when the signal is...
-
SDSR: A Spectral Divide-and-Conquer Approach for Species Tree Reconstruction
This paper addresses the computational bottleneck in reconstructing species trees from thousands of species and multiple genes by introducing a scalab...
PanFoMa: A Lightweight Foundation Model and Benchmark for Pan-Cancer
Extracted from affiliations in the content snippet (specific institutions not fully listed in provided text)

30秒速读
IN SHORT: This paper addresses the dual challenge of achieving computational efficiency without sacrificing accuracy in whole-transcriptome single-cell representation learning for pan-cancer analysis, moving beyond the limitations of pure Transformer or Mamba architectures.
核心创新
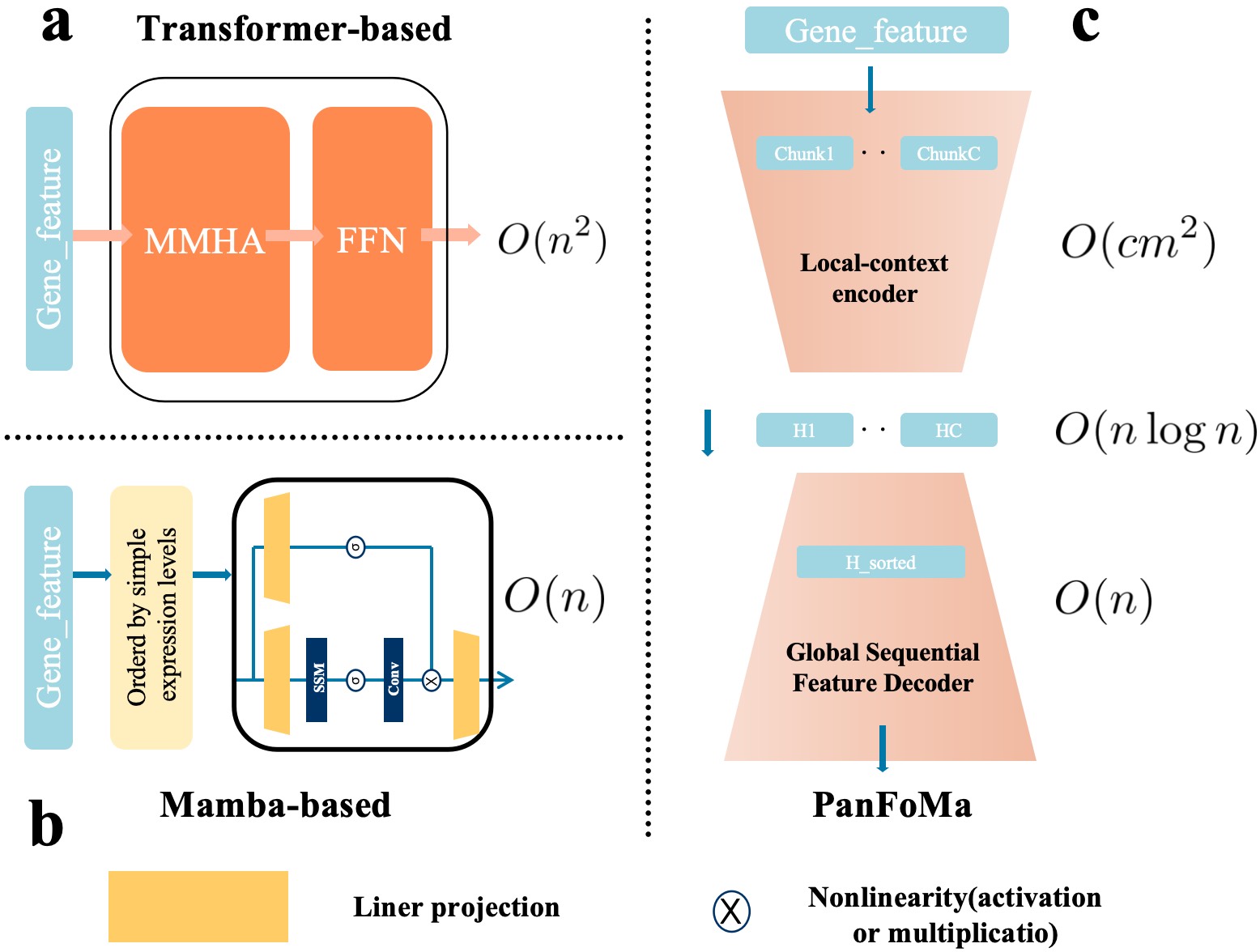
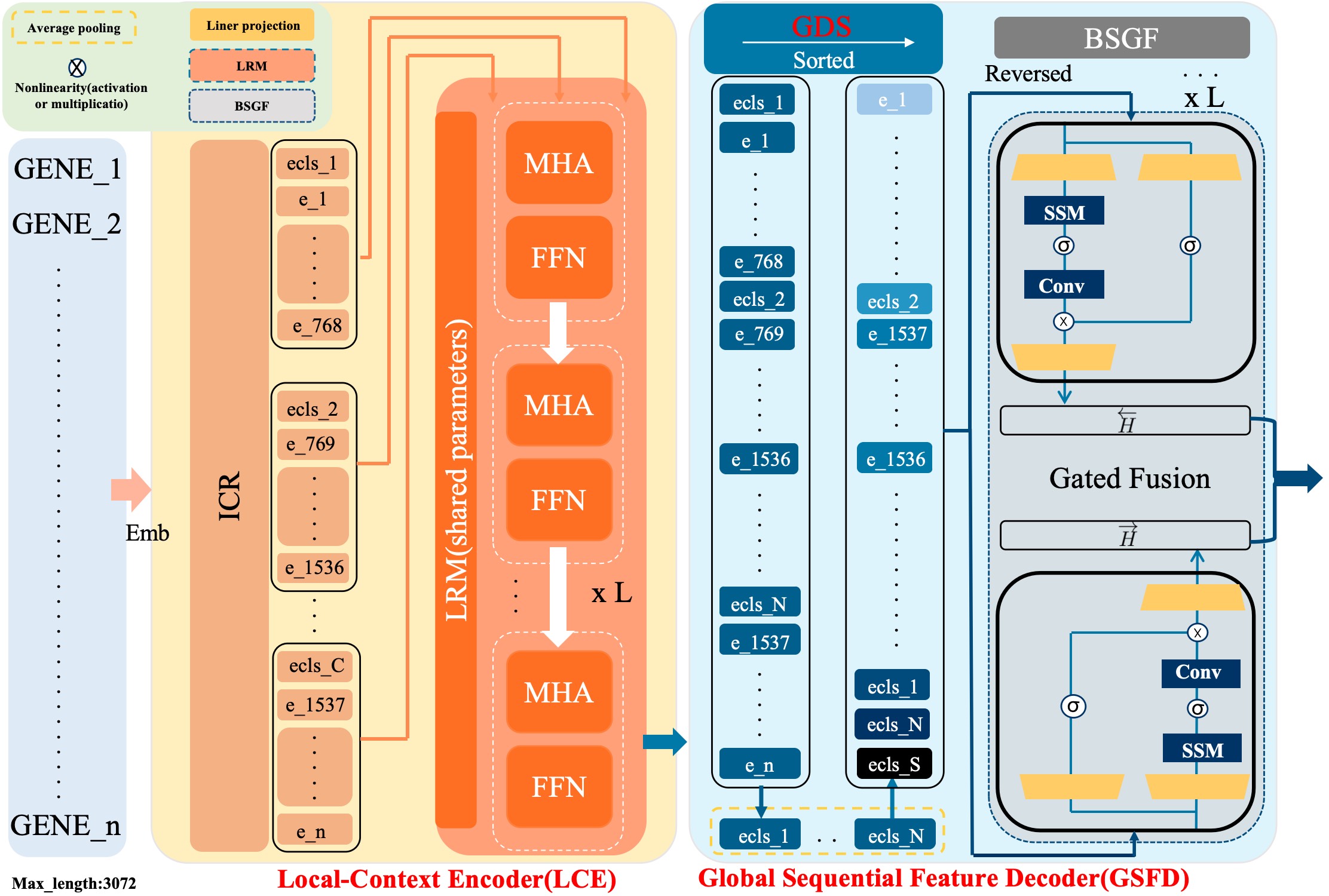
- Methodology Proposes a novel hybrid architecture (PanFoMa) that decouples local gene interaction modeling (via a lightweight, chunked Transformer encoder) from global context integration (via a bidirectional Mamba decoder), achieving O(C·M² + N log N) complexity.
- Methodology Introduces a Global-informed Dynamic Sorting (GDS) mechanism that adaptively orders genes for the Mamba decoder based on a learned global cell state vector, moving beyond static, heuristic gene ordering (e.g., by mean expression).
- Biology Constructs and releases PanFoMaBench, a large-scale, rigorously curated pan-cancer single-cell benchmark comprising over 3.5 million high-quality cells across 33 cancer subtypes from 23 tissues, addressing the lack of comprehensive evaluation resources.
主要结论
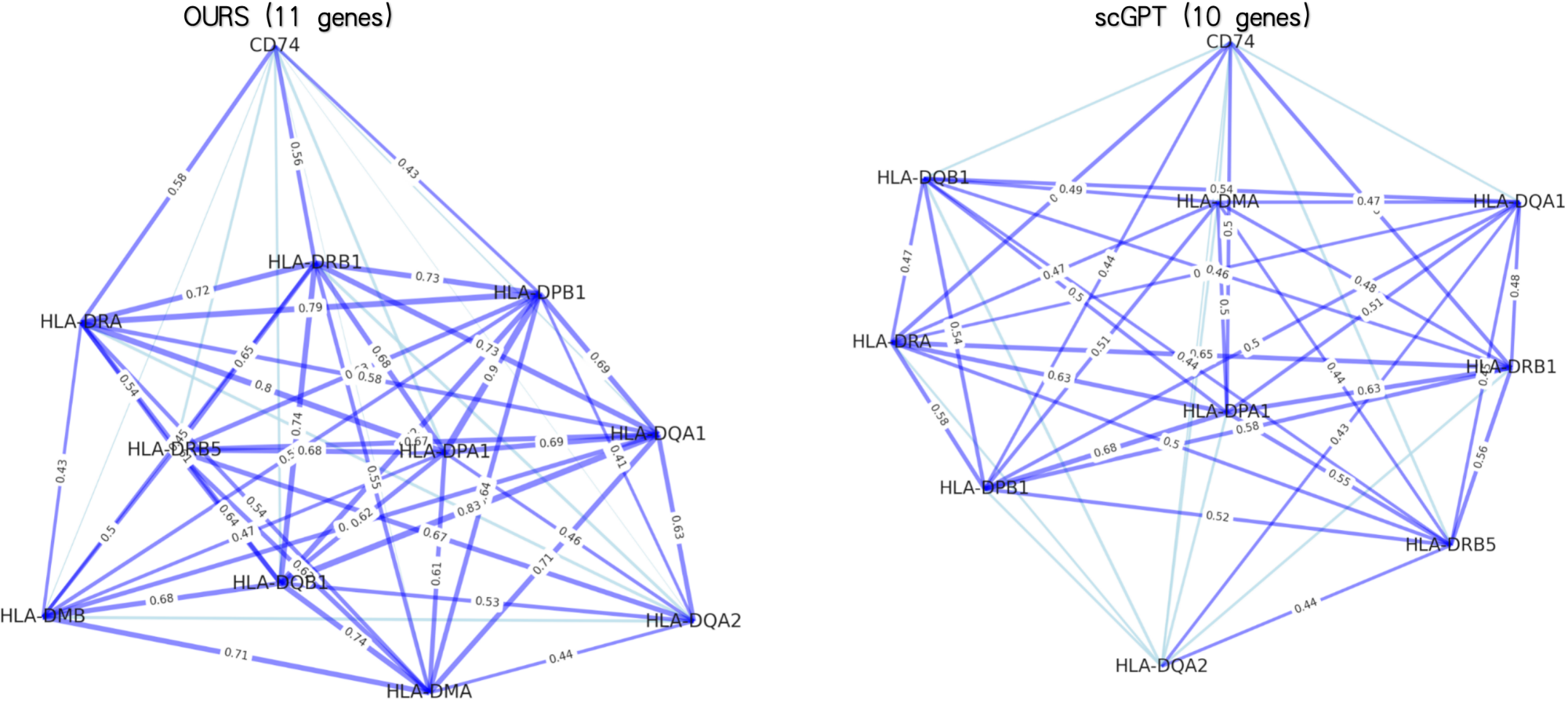
- PanFoMa achieves state-of-the-art pan-cancer classification accuracy of 94.74% (ACC) and 92.5% (Macro-F1) on PanFoMaBench, outperforming GeneFormer by +3.5% ACC and +4.0% F1.
- The model demonstrates superior generalizability across foundational tasks, showing improvements of +7.4% in cell type annotation, +4.0% in batch integration, and +3.1% in multi-omics integration over baselines.
- The hybrid local-global design and dynamic sorting are validated as effective, enabling efficient processing of full transcriptome-scale data (~3000 genes) while capturing both fine-grained local interactions and broad global regulatory patterns.
摘要: Single-cell RNA sequencing (scRNA-seq) is essential for decoding tumor heterogeneity. However, pan-cancer research still faces two key challenges: learning discriminative and efficient single-cell representations, and establishing a comprehensive evaluation benchmark. In this paper, we introduce PanFoMa, a lightweight hybrid neural network that combines the strengths of Transformers and state-space models to achieve a balance between performance and efficiency. PanFoMa consists of a front-end local-context encoder with shared self-attention layers to capture complex, order-independent gene interactions; and a back-end global sequential feature decoder that efficiently integrates global context using a linear-time state-space model. This modular design preserves the expressive power of Transformers while leveraging the scalability of Mamba to enable transcriptome modeling, effectively capturing both local and global regulatory signals. To enable robust evaluation, we also construct a large-scale pan-cancer single-cell benchmark, PanFoMaBench, containing over 3.5 million high-quality cells across 33 cancer subtypes, curated through a rigorous preprocessing pipeline. Experimental results show that PanFoMa outperforms state-of-the-art models on our pan-cancer benchmark (+4.0%) and across multiple public tasks, including cell type annotation (+7.4%), batch integration (+4.0%) and multi-omics integration (+3.1%). The code is available at https://github.com/Xiaoshui-Huang/PanFoMa.