
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
Emergent Bayesian Behaviour and Optimal Cue Combination in LLMs
Huawei Noah’s Ark Lab, London, UK | AI Centre, Department of Computer Science, University College London, London, UK
30秒速读
IN SHORT: This paper addresses the critical gap in understanding whether LLMs spontaneously develop human-like Bayesian strategies for processing uncertain information, revealing that high accuracy does not guarantee robust multimodal integration.
核心创新
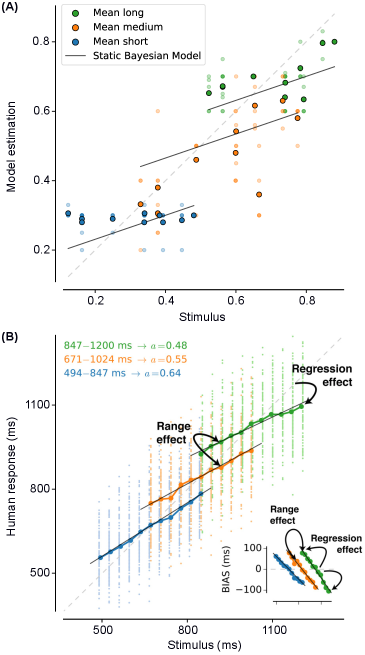
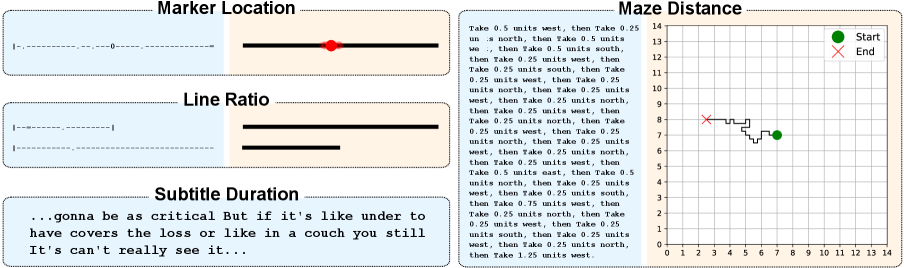
- Methodology Introduces BayesBench, the first psychophysics-inspired behavioral benchmark for LLMs with four magnitude estimation tasks (length, location, distance, duration) across text and image modalities.
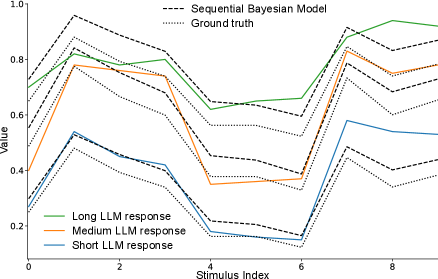
- Methodology Develops Bayesian Consistency Score (BCS) to detect Bayes-consistent behavioral shifts even when accuracy saturates, enabling separation of capability from computational strategy.
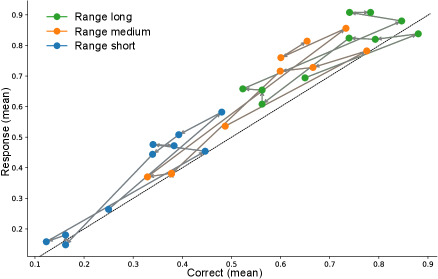
- Biology Demonstrates emergent Bayesian behavior in capable LLMs without explicit training, with Llama-4 Maverick showing cue-combination efficiency exceeding human biological systems (RRE > 1 against Bayesian oracle).
主要结论
- GPT-5 Mini achieves perfect text accuracy (NRMSE ≈ 0) but fails to integrate visual cues efficiently, showing poor cue-combination efficiency (RRE < 1) despite high capability.
- Llama-4 Maverick demonstrates emergent Bayesian behavior with cue-combination efficiency exceeding Bayesian reliability-weighted baselines (RRE > 1), suggesting non-linear integration strategies.
- Bayesian Consistency Score reveals that more accurate models show stronger evidence of Bayesian behavior, with BCS positively correlated with accuracy across nine evaluated LLMs.
摘要: Large language models (LLMs) excel at explicit reasoning, but their implicit computational strategies remain underexplored. Decades of psychophysics research show that humans intuitively process and integrate noisy signals using near-optimal Bayesian strategies in perceptual tasks. We ask whether LLMs exhibit similar behaviour and perform optimal multimodal integration without explicit training or instruction. Adopting the psychophysics paradigm, we infer computational principles of LLMs from systematic behavioural studies. We introduce a behavioural benchmark - BayesBench: four magnitude estimation tasks (length, location, distance, and duration) over text and image, inspired by classic psychophysics, and evaluate a diverse set of nine LLMs alongside human judgments for calibration. Through controlled ablations of noise, context, and instruction prompts, we measure performance, behaviour and efficiency in multimodal cue-combination. Beyond accuracy and efficiency metrics, we introduce a Bayesian Consistency Score that detects Bayes-consistent behavioural shifts even when accuracy saturates. Our results show that while capable models often adapt in Bayes-consistent ways, accuracy does not guarantee robustness. Notably, GPT-5 Mini achieves perfect text accuracy but fails to integrate visual cues efficiently. This reveals a critical dissociation between capability and strategy, suggesting accuracy-centric benchmarks may over-index on performance while missing brittle uncertainty handling. These findings reveal emergent principled handling of uncertainty and highlight the correlation between accuracy and Bayesian tendencies. We release our psychophysics benchmark and consistency metric as evaluation tools and to inform future multimodal architecture designs111Project webpage: https://bayes-bench.github.io.