
Paper List
-
Macroscopic Dominance from Microscopic Extremes: Symmetry Breaking in Spatial Competition
This paper addresses the fundamental question of how microscopic stochastic advantages in spatial exploration translate into macroscopic resource domi...
-
Linear Readout of Neural Manifolds with Continuous Variables
This paper addresses the core challenge of quantifying how the geometric structure of high-dimensional neural population activity (neural manifolds) d...
-
Theory of Cell Body Lensing and Phototaxis Sign Reversal in “Eyeless” Mutants of Chlamydomonas
This paper solves the core puzzle of how eyeless mutants of Chlamydomonas exhibit reversed phototaxis by quantitatively modeling the competition betwe...
-
Cross-Species Transfer Learning for Electrophysiology-to-Transcriptomics Mapping in Cortical GABAergic Interneurons
This paper addresses the challenge of predicting transcriptomic identity from electrophysiological recordings in human cortical interneurons, where li...
-
Uncovering statistical structure in large-scale neural activity with Restricted Boltzmann Machines
This paper addresses the core challenge of modeling large-scale neural population activity (1500-2000 neurons) with interpretable higher-order interac...
-
Realizing Common Random Numbers: Event-Keyed Hashing for Causally Valid Stochastic Models
This paper addresses the critical problem that standard stateful PRNG implementations in agent-based models violate causal validity by making random d...
-
A Standardized Framework for Evaluating Gene Expression Generative Models
This paper addresses the critical lack of standardized evaluation protocols for single-cell gene expression generative models, where inconsistent metr...
-
Single Molecule Localization Microscopy Challenge: A Biologically Inspired Benchmark for Long-Sequence Modeling
This paper addresses the core challenge of evaluating state-space models on biologically realistic, sparse, and stochastic temporal processes, which a...
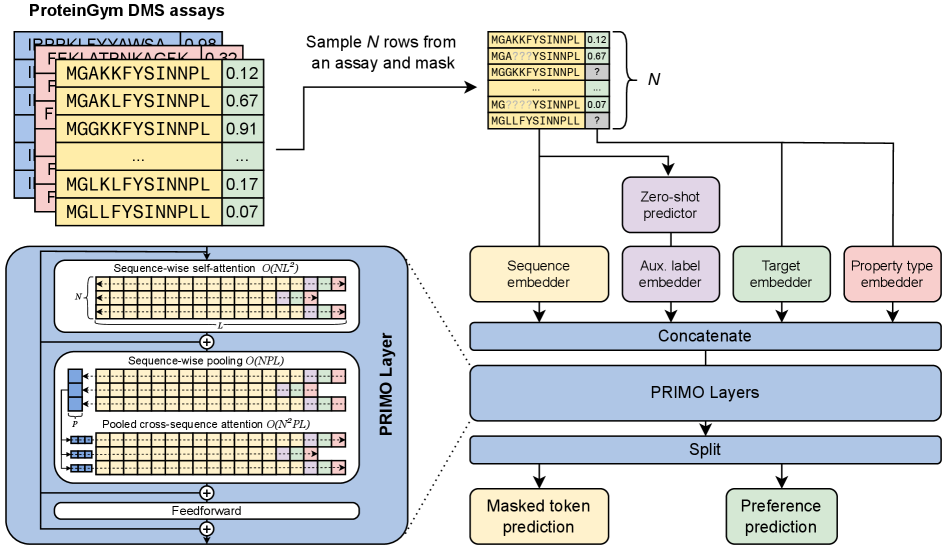
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.