
Paper List
-
GOPHER: Optimization-based Phenotype Randomization for Genome-Wide Association Studies with Differential Privacy
This paper addresses the core challenge of balancing rigorous privacy protection with data utility when releasing full GWAS summary statistics, overco...
-
Real-time Cricket Sorting By Sex A low-cost embedded solution using YOLOv8 and Raspberry Pi
This paper addresses the critical bottleneck in industrial insect farming: the lack of automated, real-time sex sorting systems for Acheta domesticus ...
-
Training Dynamics of Learning 3D-Rotational Equivariance
This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with dat...
-
Fast and Accurate Node-Age Estimation Under Fossil Calibration Uncertainty Using the Adjusted Pairwise Likelihood
This paper addresses the dual challenge of computational inefficiency and sensitivity to fossil calibration errors in Bayesian divergence time estimat...
-
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collecti...
-
scCluBench: Comprehensive Benchmarking of Clustering Algorithms for Single-Cell RNA Sequencing
This paper addresses the critical gap of fragmented and non-standardized benchmarking in single-cell RNA-seq clustering, which hinders objective compa...
-
Simulation and inference methods for non-Markovian stochastic biochemical reaction networks
This paper addresses the computational bottleneck of simulating and performing Bayesian inference for non-Markovian biochemical systems with history-d...
-
Assessment of Simulation-based Inference Methods for Stochastic Compartmental Models
This paper addresses the core challenge of performing accurate Bayesian parameter inference for stochastic epidemic models when the likelihood functio...
EnzyCLIP: A Cross-Attention Dual Encoder Framework with Contrastive Learning for Predicting Enzyme Kinetic Constants
Vellore Institute of Technology | BIT (Department of Computer Science) | BIT (Department of Bioengineering and Biotechnology)
30秒速读
IN SHORT: This paper addresses the core challenge of jointly predicting enzyme kinetic parameters (Kcat and Km) by modeling dynamic enzyme-substrate interactions through a multimodal contrastive learning framework.
核心创新
- Methodology Proposes a CLIP-inspired dual-encoder architecture with bidirectional cross-attention that dynamically models enzyme-substrate interactions, overcoming the limitation of separate processing in existing methods.
- Methodology Integrates contrastive learning (InfoNCE loss) with multi-task regression (Huber loss) to learn aligned multimodal representations while jointly predicting both Kcat and Km parameters.
- Biology Addresses the critical gap in existing literature that typically focuses on single parameter prediction (mainly Kcat) by providing a unified framework for joint prediction of both fundamental kinetic constants.
主要结论
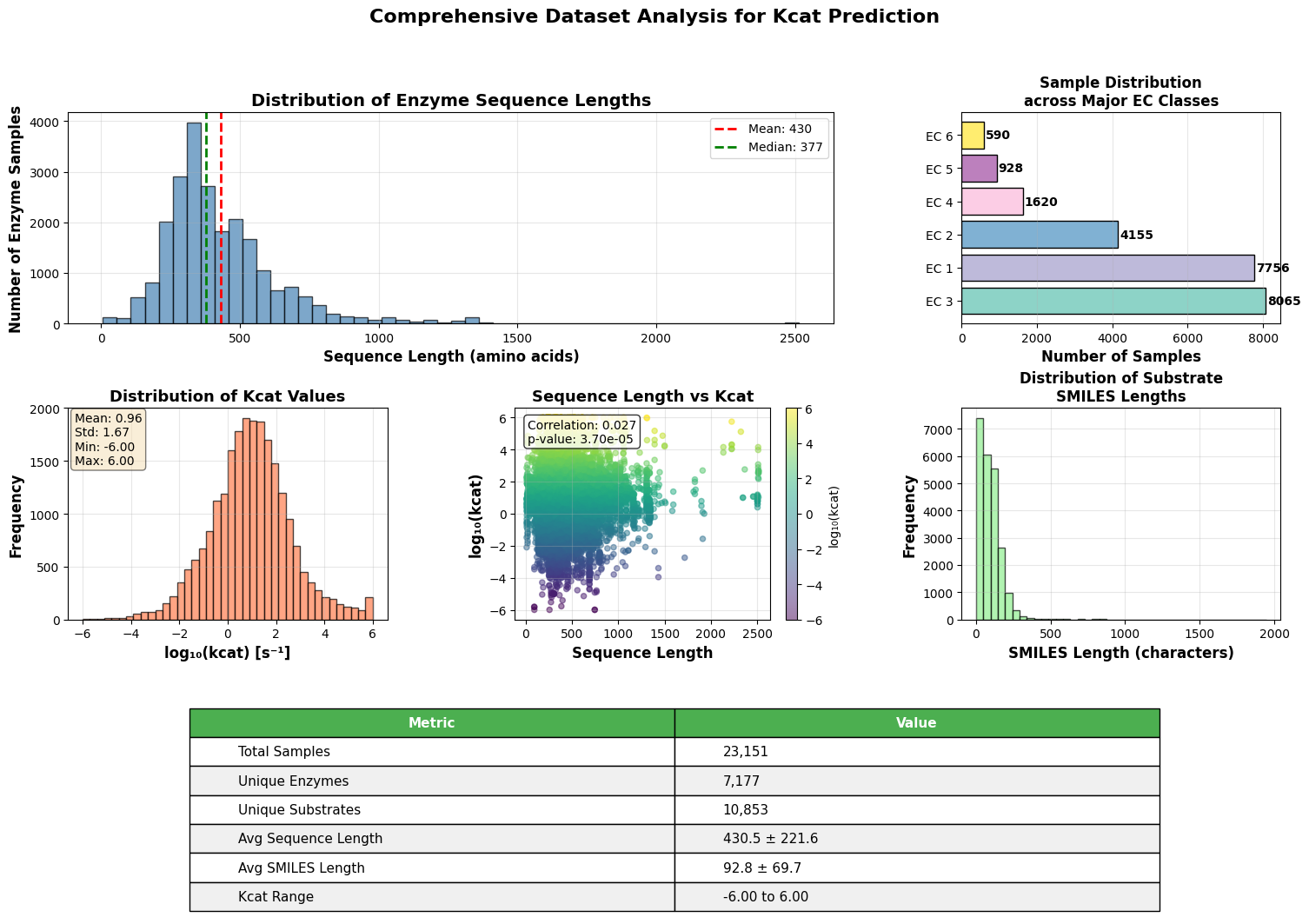
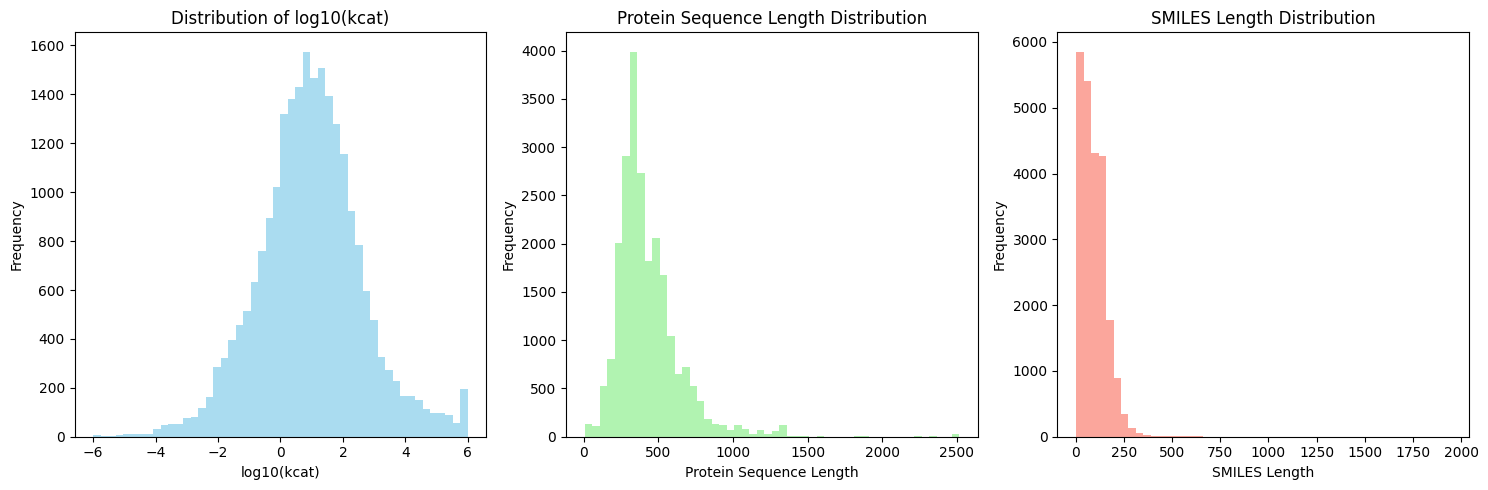
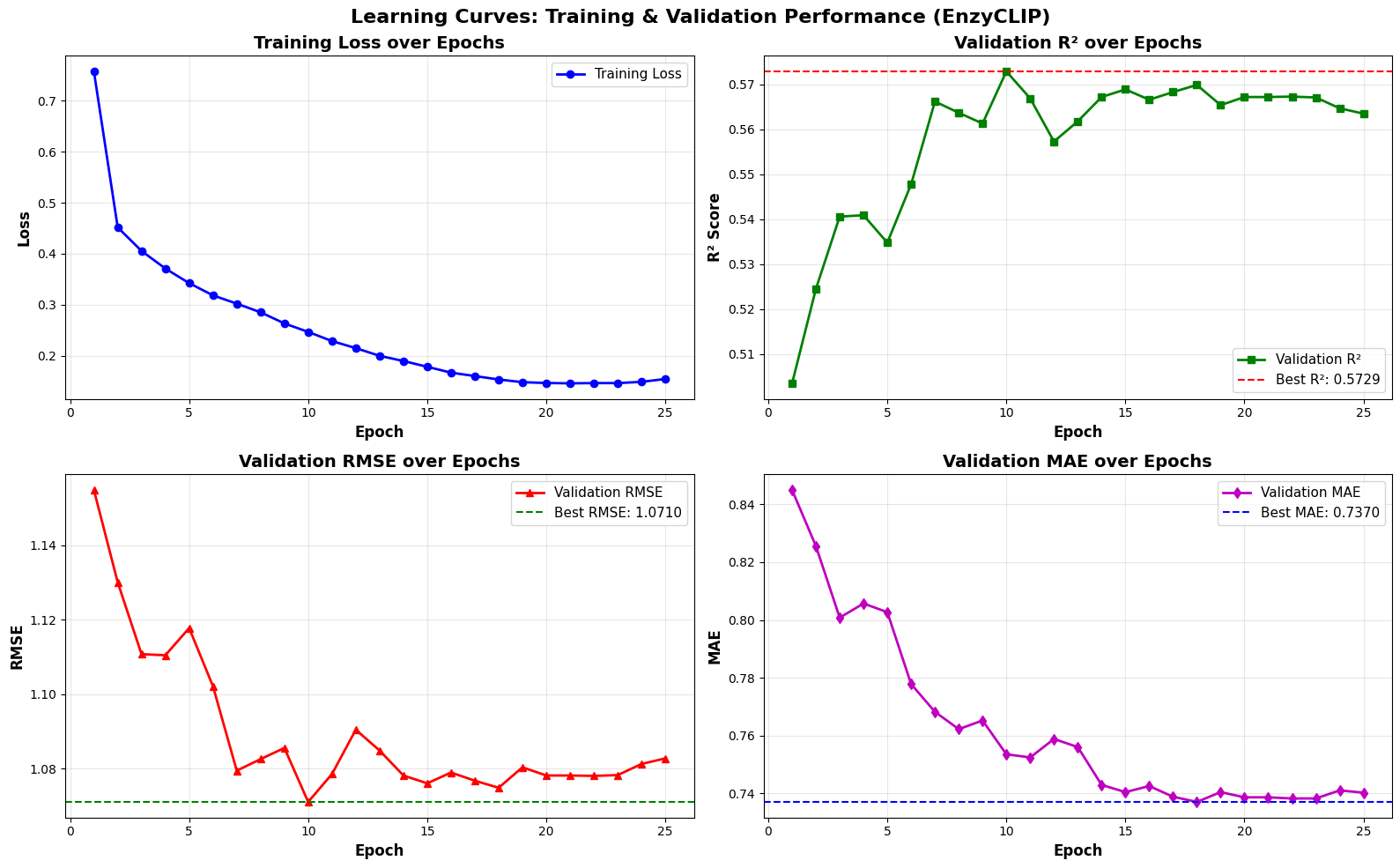
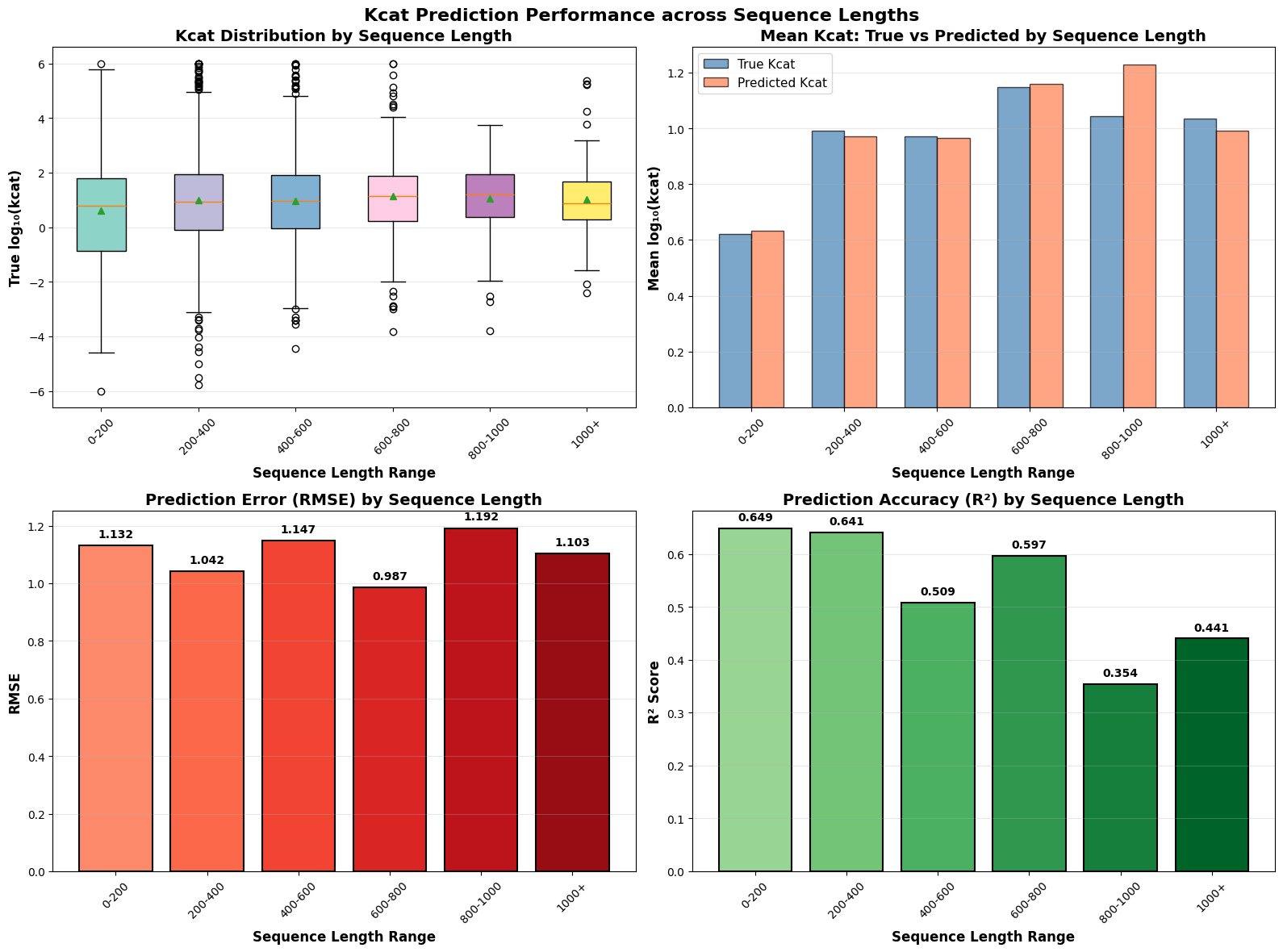
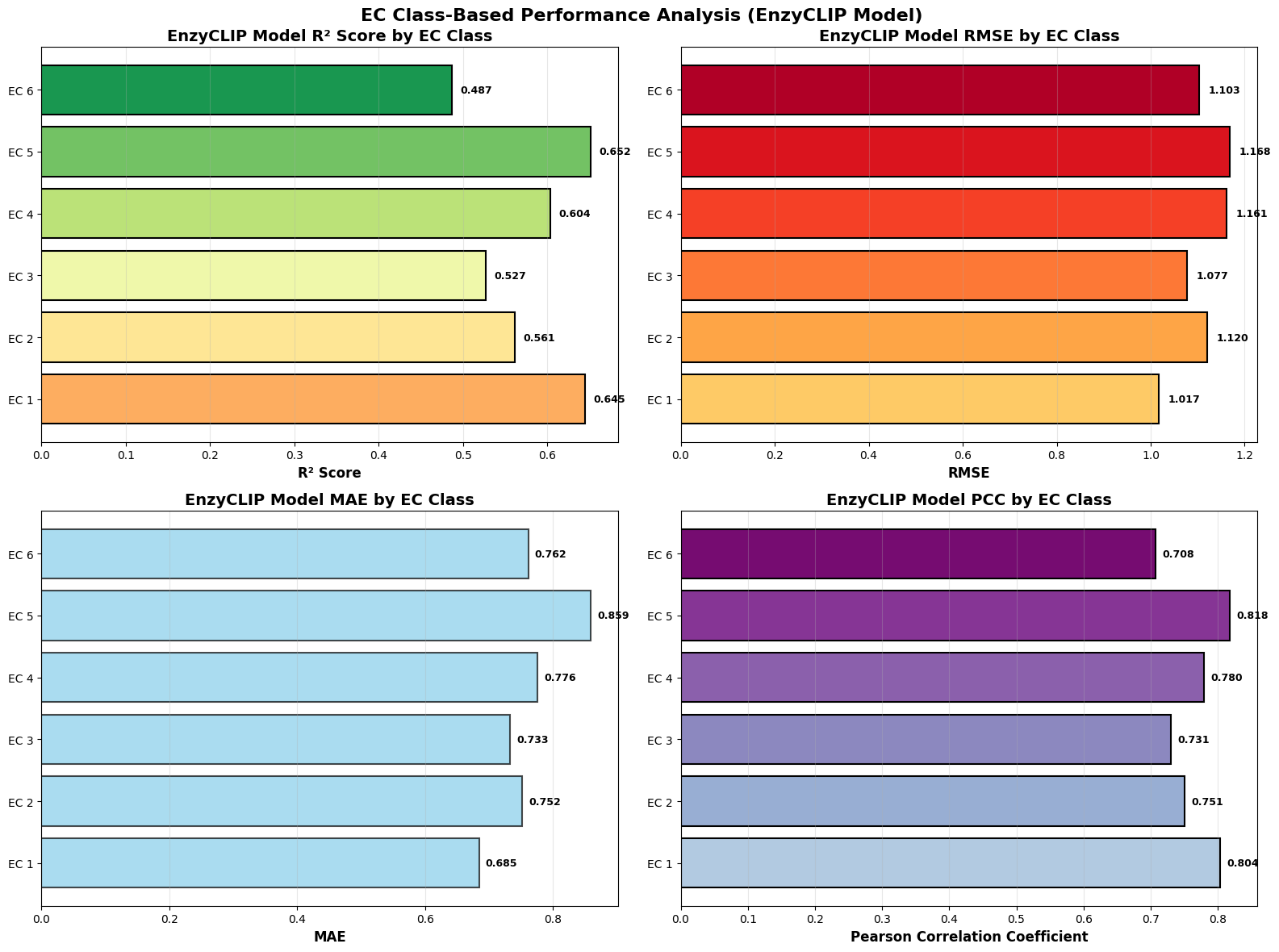
- EnzyCLIP achieves competitive baseline performance with R² scores of 0.593 for Kcat and 0.607 for Km prediction on the CatPred-DB dataset containing 23,151 Kcat and 41,174 Km measurements.
- The integration of contrastive learning with cross-attention mechanisms enables the model to capture biochemical relationships and substrate preferences even for unseen enzyme-substrate pairs.
- XGBoost ensemble methods applied to learned embeddings further improved Km prediction performance to R² = 0.61 while maintaining robust Kcat prediction capabilities.
摘要: Accurate prediction of enzyme kinetic parameters is crucial for drug discovery, metabolic engineering, and synthetic biology applications. Current computational approaches face limitations in capturing complex enzyme–substrate interactions and often focus on single parameters while neglecting the joint prediction of catalytic turnover numbers (Kcat) and Michaelis–Menten constants (Km). We present EnzyCLIP, a novel dual-encoder framework that leverages contrastive learning and cross-attention mechanisms to predict enzyme kinetic parameters from protein sequences and substrate molecular structures. Our approach integrates ESM-2 protein language model embeddings with ChemBERTa chemical representations through a CLIP-inspired architecture enhanced with bidirectional cross-attention for dynamic enzyme–substrate interaction modeling. EnzyCLIP combines InfoNCE contrastive loss with Huber regression loss to learn aligned multimodal representations while predicting log10-transformed kinetic parameters. EnzyCLIP is trained on the CatPred-DB database containing 23,151 Kcat and 41,174 Km experimentally validated measurements, and achieved competitive baseline performance with R2 scores of 0.593 for Kcat and 0.607 for Km prediction. XGBoost ensemble methods on learned embeddings further improved Km prediction (R2 = 0.61) while maintaining robust Kcat performance.