
Paper List
-
A Theoretical Framework for the Formation of Large Animal Groups: Topological Coordination, Subgroup Merging, and Velocity Inheritance
This paper addresses the core problem of how large, coordinated animal groups form in nature, challenging the classical view of gradual aggregation by...
-
CONFIDE: Hallucination Assessment for Reliable Biomolecular Structure Prediction and Design
This paper addresses the critical limitation of current protein structure prediction models (like AlphaFold3) where high-confidence scores (pLDDT) can...
-
Generative design and validation of therapeutic peptides for glioblastoma based on a potential target ATP5A
This paper addresses the critical bottleneck in therapeutic peptide design: how to efficiently optimize lead peptides with geometric constraints while...
-
Pharmacophore-based design by learning on voxel grids
This paper addresses the computational bottleneck and limited novelty in conventional pharmacophore-based virtual screening by introducing a voxel cap...
-
Human-Centred Evaluation of Text-to-Image Generation Models for Self-expression of Mental Distress: A Dataset Based on GPT-4o
This paper addresses the critical gap in evaluating how AI-generated images can effectively support cross-cultural mental distress communication, part...
-
ANNE Apnea Paper
This paper addresses the core challenge of achieving accurate, event-level sleep apnea detection and characterization using a non-intrusive, multimoda...
-
DeeDeeExperiment: Building an infrastructure for integrating and managing omics data analysis results in R/Bioconductor
This paper addresses the critical bottleneck of managing and organizing the growing volume of differential expression and functional enrichment analys...
-
Cross-Species Antimicrobial Resistance Prediction from Genomic Foundation Models
This paper addresses the core challenge of predicting antimicrobial resistance across phylogenetically distinct bacterial species, where traditional m...
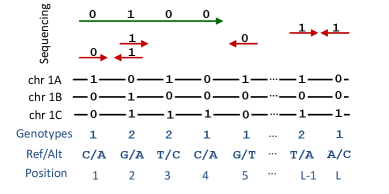
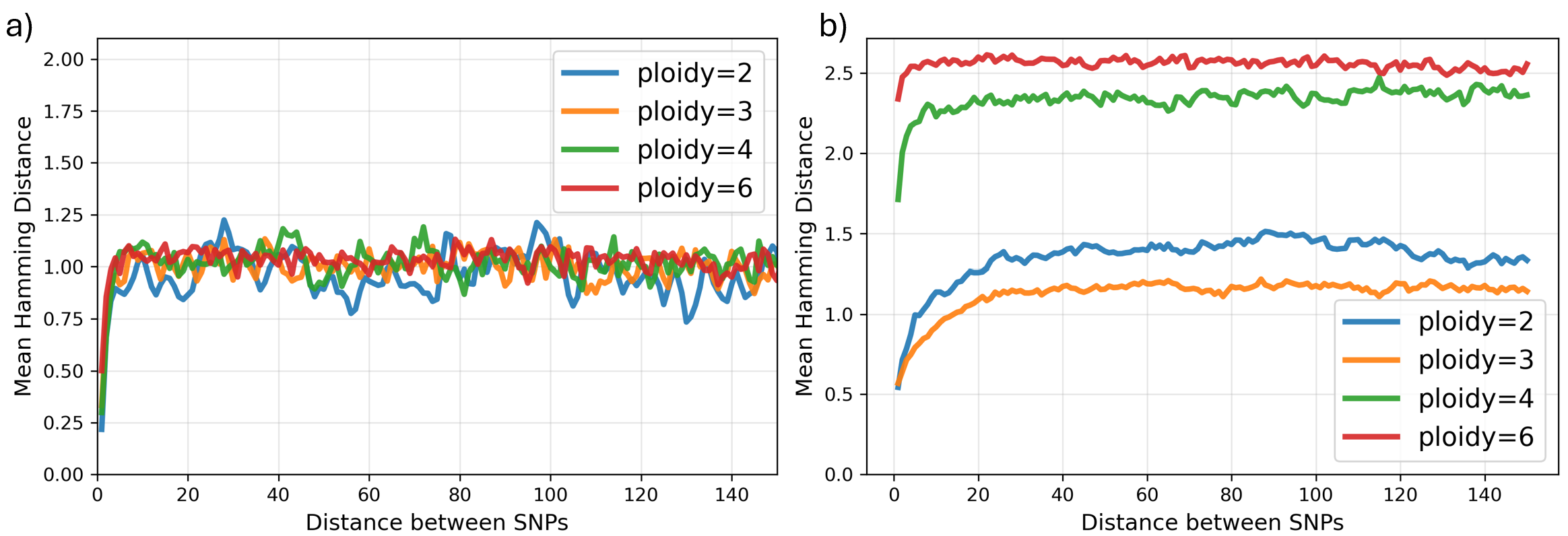
pHapCompass: Probabilistic Assembly and Uncertainty Quantification of Polyploid Haplotype Phase
School of Computing, University of Connecticut | Department of Entomology and Plant Pathology, University of Tennessee | Institute for Systems Genomics, University of Connecticut
30秒速读
IN SHORT: This paper addresses the core challenge of accurately assembling polyploid haplotypes from sequencing data, where read assignment ambiguity and an exponential search space of possible phasings have hindered reliable reconstruction and uncertainty quantification.
核心创新
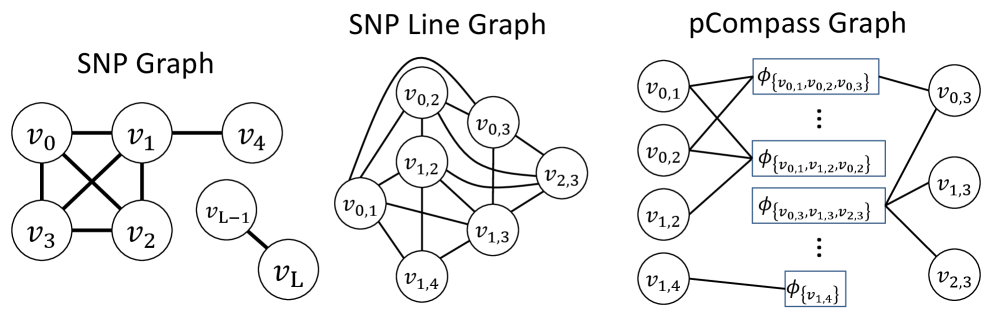
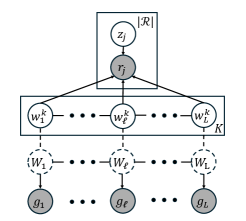
- Methodology Introduces pHapCompass, the first probabilistic haplotype assembler for diploid and polyploid genomes that explicitly models read assignment ambiguity to compute a distribution over haplotype phasings, enabling formal uncertainty quantification.
- Methodology Develops two distinct graph-theoretic algorithms: pHapCompass-short (a Markov random field for high-coverage short reads) and pHapCompass-long (a hierarchical mixture model for low-coverage long reads), both designed to scale with genomic complexity.
- Methodology Creates the first computational workflow for simulating realistic auto- and allopolyploid genomes and sequencing data, addressing a critical gap in benchmarking tools that previously relied on oversimplified synthetic genomes.
主要结论
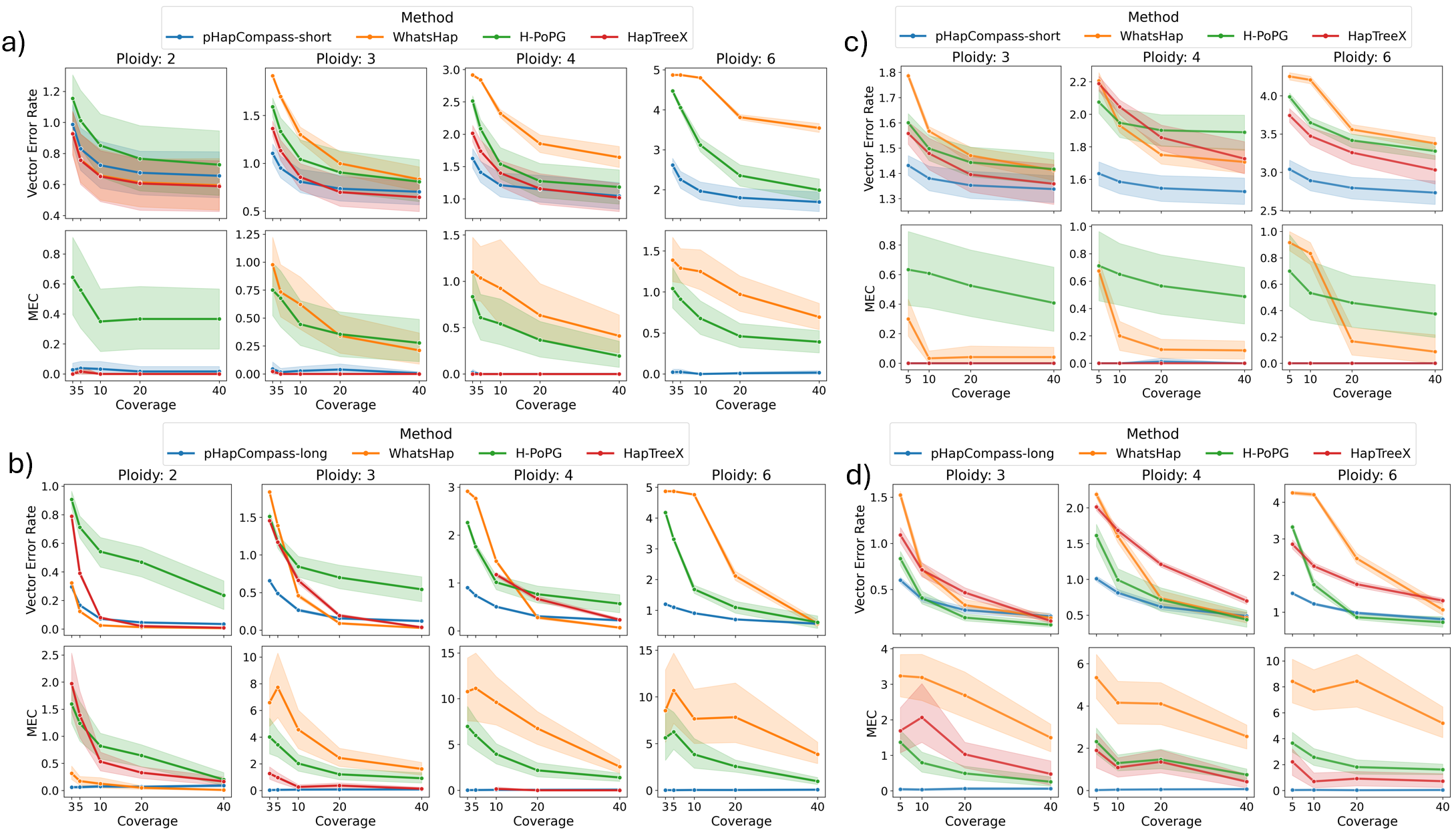
- pHapCompass demonstrates competitive performance against existing assemblers across varying ploidy levels, coverage depths, and mutation rates, while uniquely providing accurate quantification of phase uncertainty.
- The developed simulation workflow generates more realistic benchmarking datasets, revealing that prior methods often overestimate performance on simplistic synthetic genomes.
- The framework successfully assembled an allo-octoploid strawberry chromosome, showcasing practical applicability to complex, real-world polyploid genomes.
摘要: Computing haplotypes from sequencing data, i.e. haplotype assembly, is an important component of foundational molecular and population genetics problems, including interpreting the effects of genetic variation on complex traits and reconstructing genealogical relationships. Assembling the haplotypes of polyploid genomes remains a significant challenge due to the exponential search space of haplotype phasings and read assignment ambiguity; the latter challenge is particularly difficult for polyploid haplotype assemblers since the information contained within the observed sequence reads is often insufficient for unambiguous haplotype assignment in polyploid genomes. We present pHapCompass, probabilistic haplotype assembly algorithms for diploid and polyploid genomes that explicitly model and propagate read assignment ambiguity to compute a distribution over polyploid haplotype phasings. We develop graph theoretic algorithms to enable statistical inference and uncertainty quantification despite an exponential space of possible phasings. Since prior work evaluates polyploid haplotype assembly on synthetic genomes that do not reflect the realistic genomic complexity of polyploidy organisms, we develop a computational workflow for simulating genomes and DNA-seq for auto- and allopolyploids. Additionally, we generalize the vector error rate and minimum error correction evaluation criteria for partially phased haplotypes. Benchmarking of pHapCompass and several existing polyploid haplotype assemblers shows that pHapCompass yields competitive performance across varying genomic complexities and polyploid structures while retaining an accurate quantification of phase uncertainty. The source code for pHapCompass, simulation scripts, and datasets are freely available at https://github.com/bayesomicslab/pHapCompass.