
Paper List
-
An AI Implementation Science Study to Improve Trustworthy Data in a Large Healthcare System
This paper addresses the critical gap between theoretical AI research and real-world clinical implementation by providing a practical framework for as...
-
The BEAT-CF Causal Model: A model for guiding the design of trials and observational analyses of cystic fibrosis exacerbations
This paper addresses the critical gap in cystic fibrosis exacerbation management by providing a formal causal framework that integrates expert knowled...
-
Hierarchical Molecular Language Models (HMLMs)
This paper addresses the core challenge of accurately modeling context-dependent signaling, pathway cross-talk, and temporal dynamics across multiple ...
-
Stability analysis of action potential generation using Markov models of voltage‑gated sodium channel isoforms
This work addresses the challenge of systematically characterizing how the high-dimensional parameter space of Markov models for different sodium chan...
-
Approximate Bayesian Inference on Mechanisms of Network Growth and Evolution
This paper addresses the core challenge of inferring the relative contributions of multiple, simultaneous generative mechanisms in network formation w...
-
EnzyCLIP: A Cross-Attention Dual Encoder Framework with Contrastive Learning for Predicting Enzyme Kinetic Constants
This paper addresses the core challenge of jointly predicting enzyme kinetic parameters (Kcat and Km) by modeling dynamic enzyme-substrate interaction...
-
Tissue stress measurements with Bayesian Inversion Stress Microscopy
This paper addresses the core challenge of measuring absolute, tissue-scale mechanical stress without making assumptions about tissue rheology, which ...
-
DeepFRI Demystified: Interpretability vs. Accuracy in AI Protein Function Prediction
This study addresses the critical gap between high predictive accuracy and biological interpretability in DeepFRI, revealing that the model often prio...
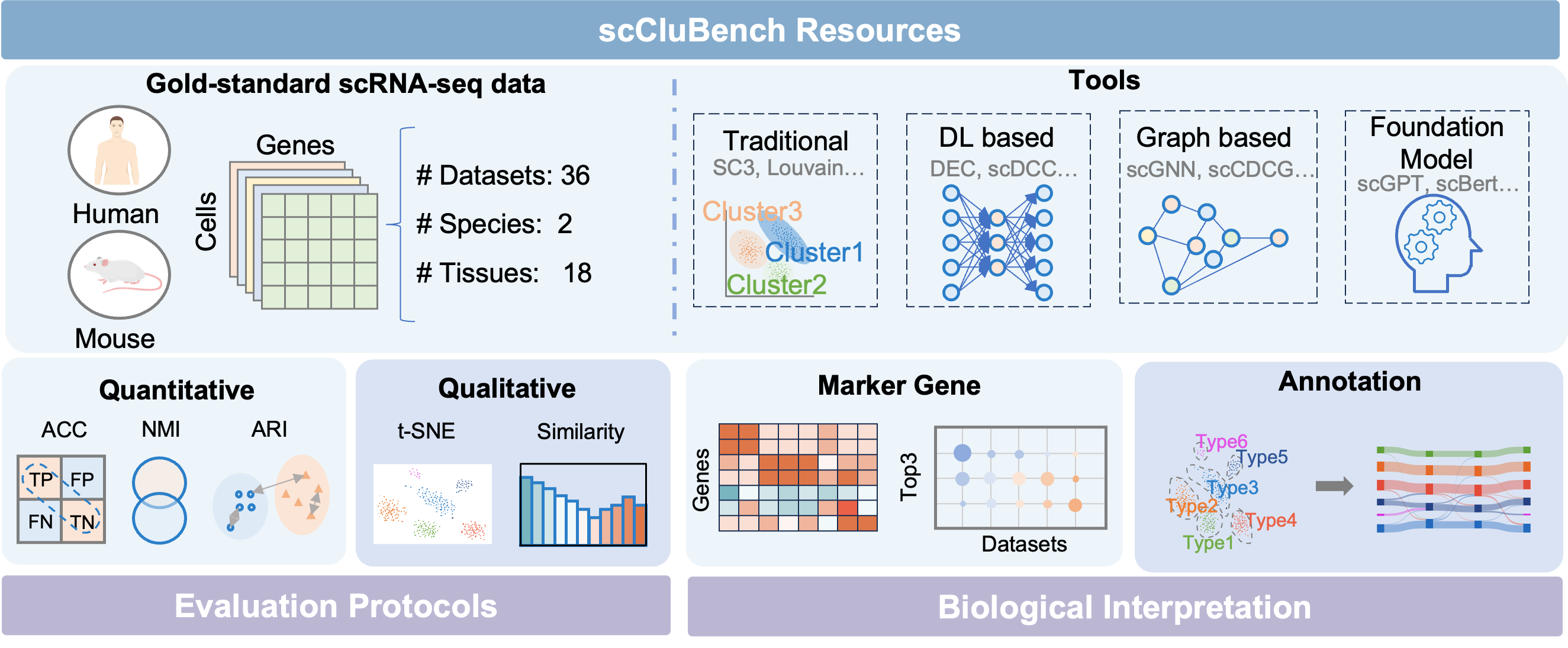
scCluBench: Comprehensive Benchmarking of Clustering Algorithms for Single-Cell RNA Sequencing
Not specified in provided content
30秒速读
IN SHORT: This paper addresses the critical gap of fragmented and non-standardized benchmarking in single-cell RNA-seq clustering, which hinders objective comparison and selection of appropriate methods for specific biological contexts.
核心创新
- Methodology Introduces scCluBench, the first comprehensive benchmarking framework that systematically evaluates 16 clustering methods across four categories (traditional, deep learning-based, graph-based, and foundation models) on 36 standardized datasets.
- Methodology Establishes standardized protocols for biological interpretation, including reproducible pipelines for marker gene identification and two distinct cell type annotation approaches (best-mapping and marker-overlap), validated with gold-standard references.
- Methodology Provides a unified and modular benchmarking workflow covering data preprocessing, clustering, and annotation with standardized input-output formats, ensuring reproducibility and fair comparison.
主要结论
- scCDCG (a cut-informed graph embedding model) achieved the highest average clustering accuracy (81.29 ± 1.45) across 36 datasets, outperforming other graph-based, deep learning, and traditional methods.
- Biological foundation models (scGPT, GeneFormer, GeneCompass) showed strong performance in classification tasks (e.g., scGPT achieved 98.14% ACC on Sapiens Ear Crista Ampullaris) but underperformed in direct clustering, highlighting a trade-off between general representation and task-specific optimization.
- The benchmark reveals method-specific limitations: traditional methods struggle with sparse data, deep learning models may fail to capture cell relationships, and graph-based models can suffer from over-smoothing, while most methods decouple embedding learning from clustering optimization.
摘要: Cell clustering is crucial for uncovering cellular heterogeneity in single-cell RNA sequencing (scRNA-seq) data by identifying cell types and marker genes. Despite its importance, benchmarks for scRNA-seq clustering methods remain fragmented, often lacking standardized protocols and failing to incorporate recent advances in artificial intelligence. To fill these gaps, we present scCluBench, a comprehensive benchmark of clustering algorithms for scRNA-seq data. First, scCluBench provides 36 scRNA-seq datasets collected from diverse public sources, covering multiple tissues, which are uniformly processed and standardized to ensure consistency for systematic evaluation and downstream analyses. To evaluate performance, we collect and reproduce a range of scRNA-seq clustering methods, including traditional, deep learning-based, graph-based, and biological foundation models. We comprehensively evaluate each method both quantitatively and qualitatively, using core performance metrics as well as visualization analyses. Furthermore, we construct representative downstream biological tasks, such as marker gene identification and cell type annotation, to further assess the practical utility. scCluBench then investigates the performance differences and applicability boundaries of various clustering models across diverse analytical tasks, systematically assessing their robustness and scalability in real-world scenarios. Overall, scCluBench offers a standardized and user-friendly benchmark for scRNA-seq clustering, with curated datasets, unified evaluation protocols, and transparent analyses, facilitating informed method selection and providing valuable insights into model generalizability and application scope.222All datasets, code, and the Extended version for scCluBench are available at the link: https://github.com/XPgogogo/scCluBench. More details for each stage are provided in the extended version.