
Paper List
-
A Theoretical Framework for the Formation of Large Animal Groups: Topological Coordination, Subgroup Merging, and Velocity Inheritance
This paper addresses the core problem of how large, coordinated animal groups form in nature, challenging the classical view of gradual aggregation by...
-
CONFIDE: Hallucination Assessment for Reliable Biomolecular Structure Prediction and Design
This paper addresses the critical limitation of current protein structure prediction models (like AlphaFold3) where high-confidence scores (pLDDT) can...
-
Generative design and validation of therapeutic peptides for glioblastoma based on a potential target ATP5A
This paper addresses the critical bottleneck in therapeutic peptide design: how to efficiently optimize lead peptides with geometric constraints while...
-
Pharmacophore-based design by learning on voxel grids
This paper addresses the computational bottleneck and limited novelty in conventional pharmacophore-based virtual screening by introducing a voxel cap...
-
Human-Centred Evaluation of Text-to-Image Generation Models for Self-expression of Mental Distress: A Dataset Based on GPT-4o
This paper addresses the critical gap in evaluating how AI-generated images can effectively support cross-cultural mental distress communication, part...
-
ANNE Apnea Paper
This paper addresses the core challenge of achieving accurate, event-level sleep apnea detection and characterization using a non-intrusive, multimoda...
-
DeeDeeExperiment: Building an infrastructure for integrating and managing omics data analysis results in R/Bioconductor
This paper addresses the critical bottleneck of managing and organizing the growing volume of differential expression and functional enrichment analys...
-
Cross-Species Antimicrobial Resistance Prediction from Genomic Foundation Models
This paper addresses the core challenge of predicting antimicrobial resistance across phylogenetically distinct bacterial species, where traditional m...
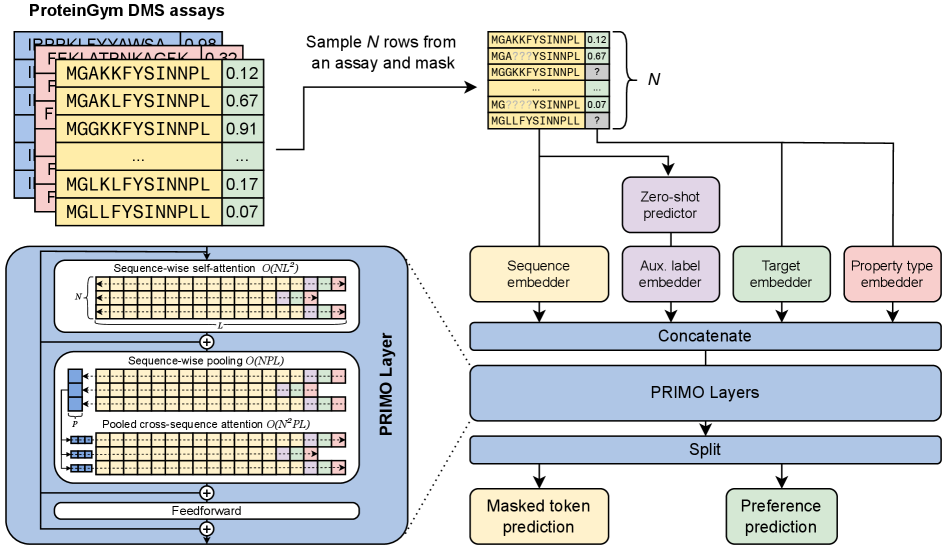
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.