
Paper List
-
A Theoretical Framework for the Formation of Large Animal Groups: Topological Coordination, Subgroup Merging, and Velocity Inheritance
This paper addresses the core problem of how large, coordinated animal groups form in nature, challenging the classical view of gradual aggregation by...
-
CONFIDE: Hallucination Assessment for Reliable Biomolecular Structure Prediction and Design
This paper addresses the critical limitation of current protein structure prediction models (like AlphaFold3) where high-confidence scores (pLDDT) can...
-
Generative design and validation of therapeutic peptides for glioblastoma based on a potential target ATP5A
This paper addresses the critical bottleneck in therapeutic peptide design: how to efficiently optimize lead peptides with geometric constraints while...
-
Pharmacophore-based design by learning on voxel grids
This paper addresses the computational bottleneck and limited novelty in conventional pharmacophore-based virtual screening by introducing a voxel cap...
-
Human-Centred Evaluation of Text-to-Image Generation Models for Self-expression of Mental Distress: A Dataset Based on GPT-4o
This paper addresses the critical gap in evaluating how AI-generated images can effectively support cross-cultural mental distress communication, part...
-
ANNE Apnea Paper
This paper addresses the core challenge of achieving accurate, event-level sleep apnea detection and characterization using a non-intrusive, multimoda...
-
DeeDeeExperiment: Building an infrastructure for integrating and managing omics data analysis results in R/Bioconductor
This paper addresses the critical bottleneck of managing and organizing the growing volume of differential expression and functional enrichment analys...
-
Cross-Species Antimicrobial Resistance Prediction from Genomic Foundation Models
This paper addresses the core challenge of predicting antimicrobial resistance across phylogenetically distinct bacterial species, where traditional m...
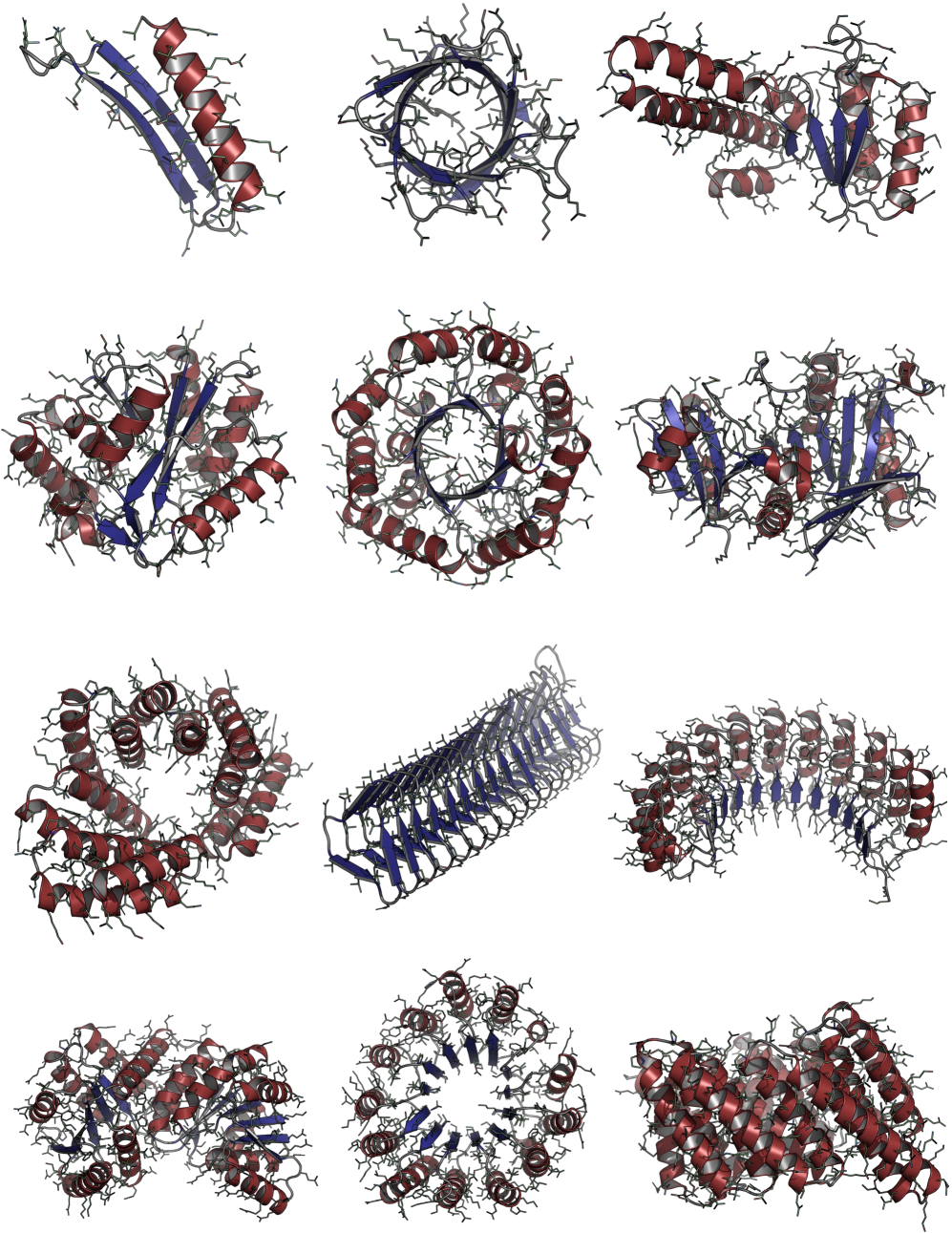
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
NVIDIA | Mila - Quebec AI Institute | Université de Montréal | HEC Montréal | CIFAR AI Chair
30秒速读
IN SHORT: This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the performance of fully atomistic protein generative models.
核心创新
- Methodology Introduces a novel high-quality synthetic dataset (D_SYN-ours, ~0.46M samples) by leveraging ProteinMPNN for sequence generation and ESMFold for refolding, ensuring aligned and recoverable sequence-structure pairs.
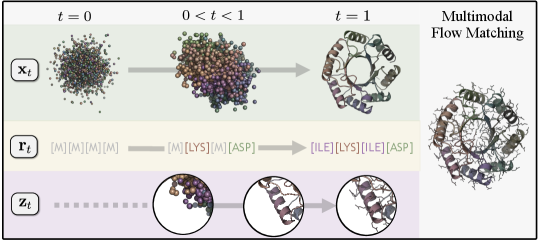
- Methodology Proposes Proteína-Atomística, a unified multi-modal flow-based framework that jointly models the distribution of Cα backbone atoms, discrete amino acid sequences, and non-Cα side-chain atoms in explicit observable space without latent variables.
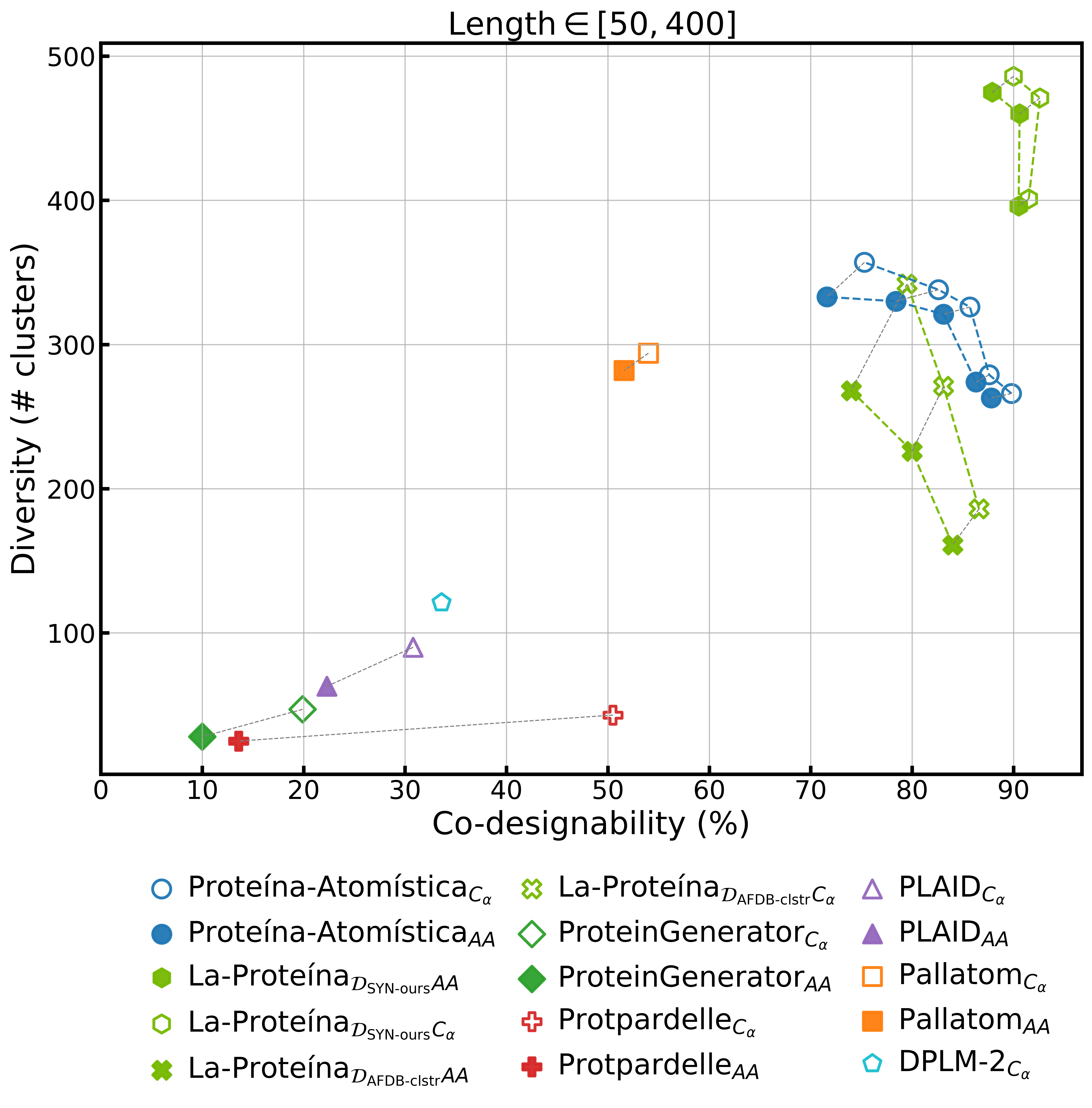
- Biology Demonstrates that consistent synthetic sequences are critical for unlocking structural diversity, with retrained La-Proteína achieving +54% structural diversity and +27% co-designability, and Proteína-Atomística achieving +73% structural diversity and +5% co-designability.
主要结论
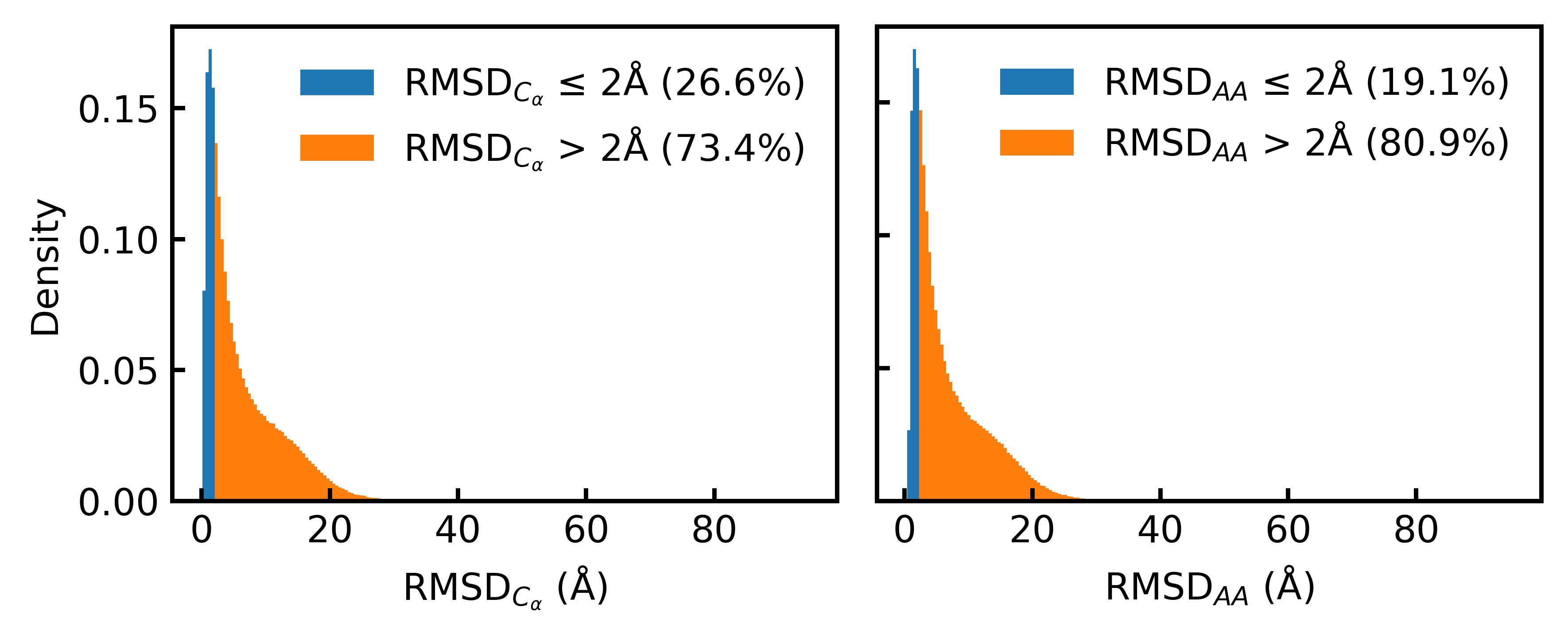
- Only 19.1% of the Foldseek-clustered AFDB dataset (D_AFDB-clstr) meets the standard 2Å all-atom RMSD co-designability threshold when refolded with ESMFold, revealing severe sequence-structure misalignment.
- Training on the new aligned dataset D_SYN-ours boosts La-Proteína's performance by +54% in structural diversity and +27% in co-designability, setting a new state-of-the-art.
- The proposed Proteína-Atomística framework, when trained on D_SYN-ours, shows a dramatic +73% improvement in structural diversity and a +5% improvement in co-designability, validating the dataset's broad utility.
摘要: High-quality training datasets are crucial for the development of effective protein design models, but existing synthetic datasets often include unfavorable sequence-structure pairs, impairing generative model performance. We leverage ProteinMPNN, whose sequences are experimentally favorable as well as amenable to folding, together with structure prediction models to align high-quality synthetic structures with recoverable synthetic sequences. In that way, we create a new dataset designed specifically for training expressive, fully atomistic protein generators. By retraining La-Proteína, which models discrete residue type and side chain structure in a continuous latent space, on this dataset, we achieve new state-of-the-art results, with improvements of +54% in structural diversity and +27% in co-designability. To validate the broad utility of our approach, we further introduce Proteína-Atomística, a unified flow-based framework that jointly learns the distribution of protein backbone structure, discrete sequences, and atomistic side chains without latent variables. We again find that training on our new sequence-structure data dramatically boosts benchmark performance, improving Proteína-Atomística’s structural diversity by +73% and co-designability by +5%. Our work highlights the critical importance of aligned sequence-structure data for training high-performance de novo protein design models. All data will be publicly released.