
Paper List
-
Formation of Artificial Neural Assemblies by Biologically Plausible Inhibition Mechanisms
This work addresses the core limitation of the Assembly Calculus model—its fixed-size, biologically implausible k-WTA selection process—by introducing...
-
How to make the most of your masked language model for protein engineering
This paper addresses the critical bottleneck of efficiently sampling high-quality, diverse protein sequences from Masked Language Models (MLMs) for pr...
-
Module control in youth symptom networks across COVID-19
This paper addresses the core challenge of distinguishing whether a prolonged societal stressor (COVID-19) fundamentally reorganizes the architecture ...
-
JEDI: Jointly Embedded Inference of Neural Dynamics
This paper addresses the core challenge of inferring context-dependent neural dynamics from noisy, high-dimensional recordings using a single unified ...
-
ATP Level and Phosphorylation Free Energy Regulate Trigger-Wave Speed and Critical Nucleus Size in Cellular Biochemical Systems
This work addresses the core challenge of quantitatively predicting how the cellular energy state (ATP level and phosphorylation free energy) governs ...
-
Packaging Jupyter notebooks as installable desktop apps using LabConstrictor
This paper addresses the core pain point of ensuring Jupyter notebook reproducibility and accessibility across different computing environments, parti...
-
SNPgen: Phenotype-Supervised Genotype Representation and Synthetic Data Generation via Latent Diffusion
This paper addresses the core challenge of generating privacy-preserving synthetic genotype data that maintains both statistical fidelity and downstre...
-
Continuous Diffusion Transformers for Designing Synthetic Regulatory Elements
This paper addresses the challenge of efficiently generating novel, cell-type-specific regulatory DNA sequences with high predicted activity while min...
SSDLabeler: Realistic semi-synthetic data generation for multi-label artifact classification in EEG
Sony Computer Science Laboratories, Inc., Tokyo, Japan
30秒速读
IN SHORT: This paper addresses the core challenge of training robust multi-label EEG artifact classifiers by overcoming the scarcity and limited diversity of manually labeled training data through a novel semi-synthetic data generation framework.
核心创新
- Methodology Introduces SSDLabeler, a framework that generates realistic semi-synthetic EEG data by simultaneously reinjecting multiple ICA-isolated artifact types into clean data, preserving the co-occurrence structure of real-world contamination.
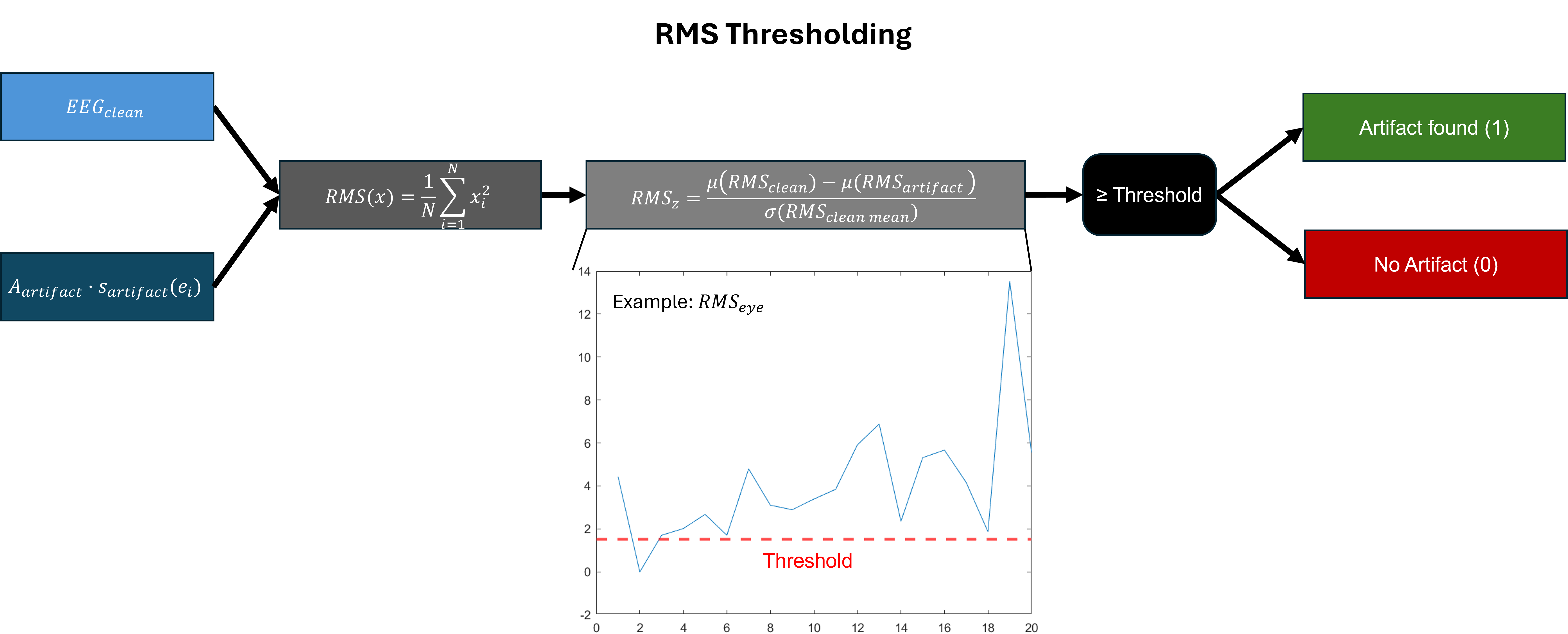
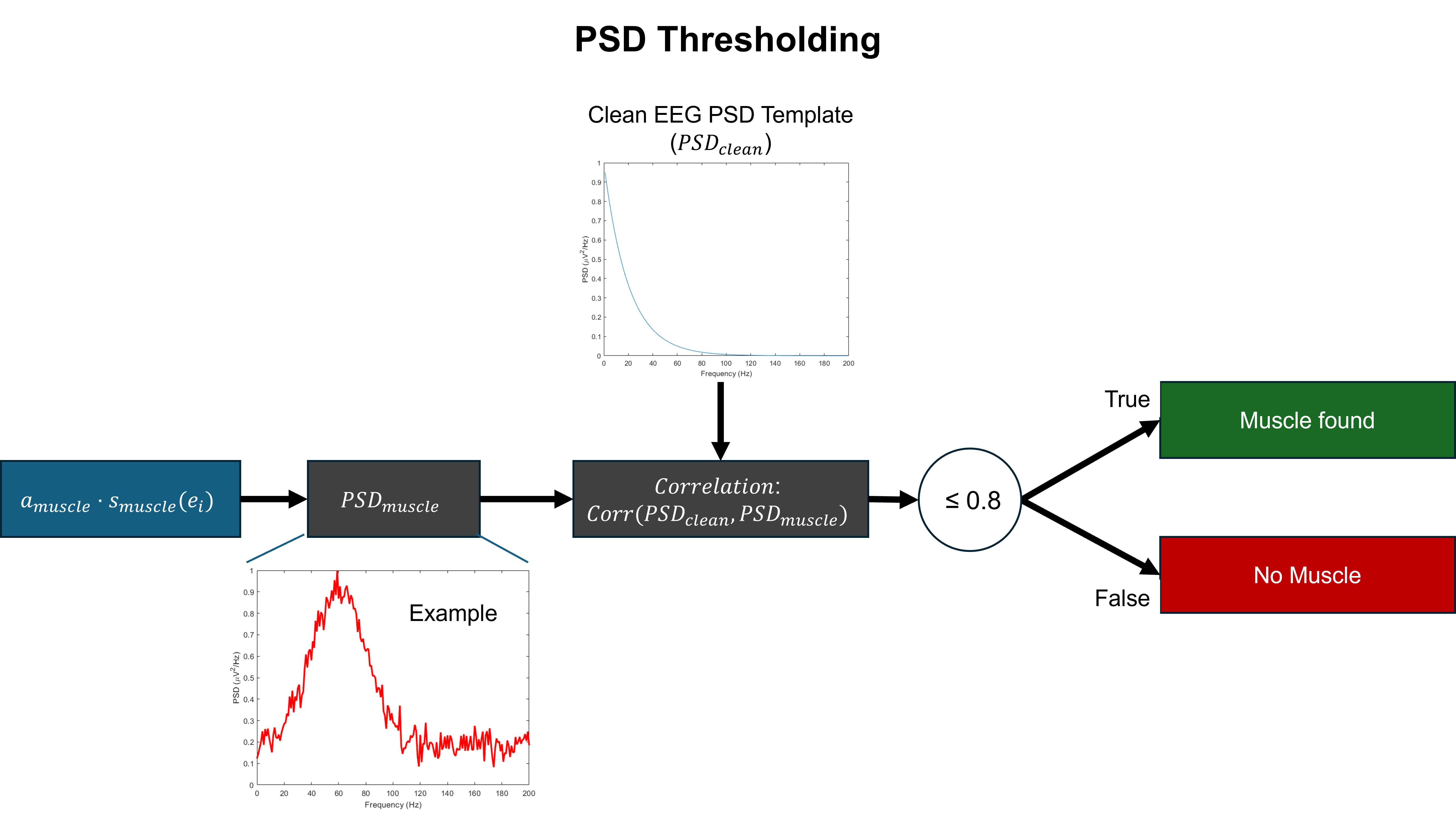
- Methodology Develops a novel artifact verification step using RMS and PSD thresholding criteria at the epoch level to ensure the physiological plausibility of generated contaminations, moving beyond simple ICA component injection.
- Biology Proposes a multi-label artifact classification paradigm that identifies multiple co-occurring artifact types (eye, muscle, heart, line, channel, other) within single EEG epochs, providing transparent contamination information for flexible preprocessing decisions.
主要结论
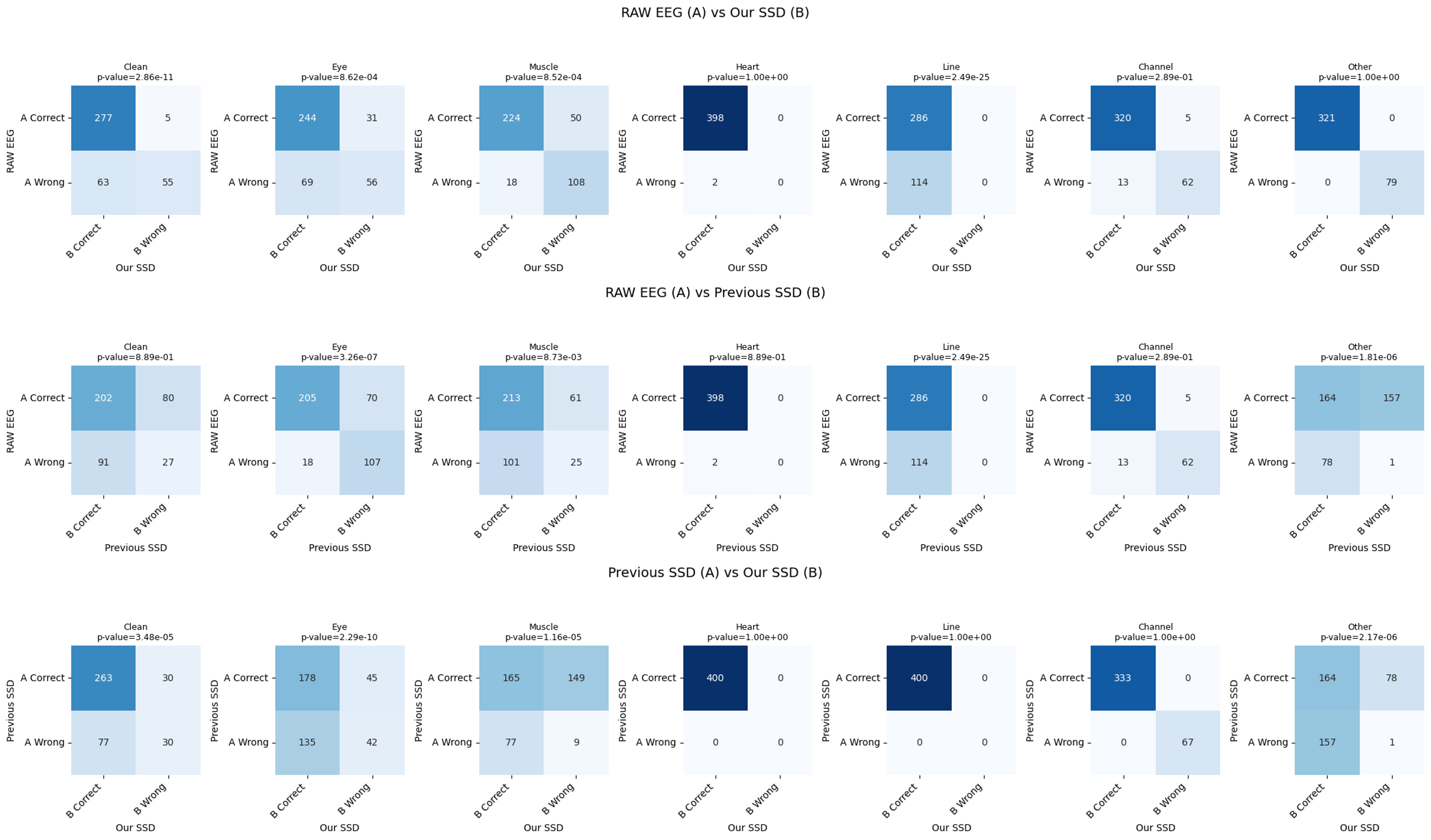
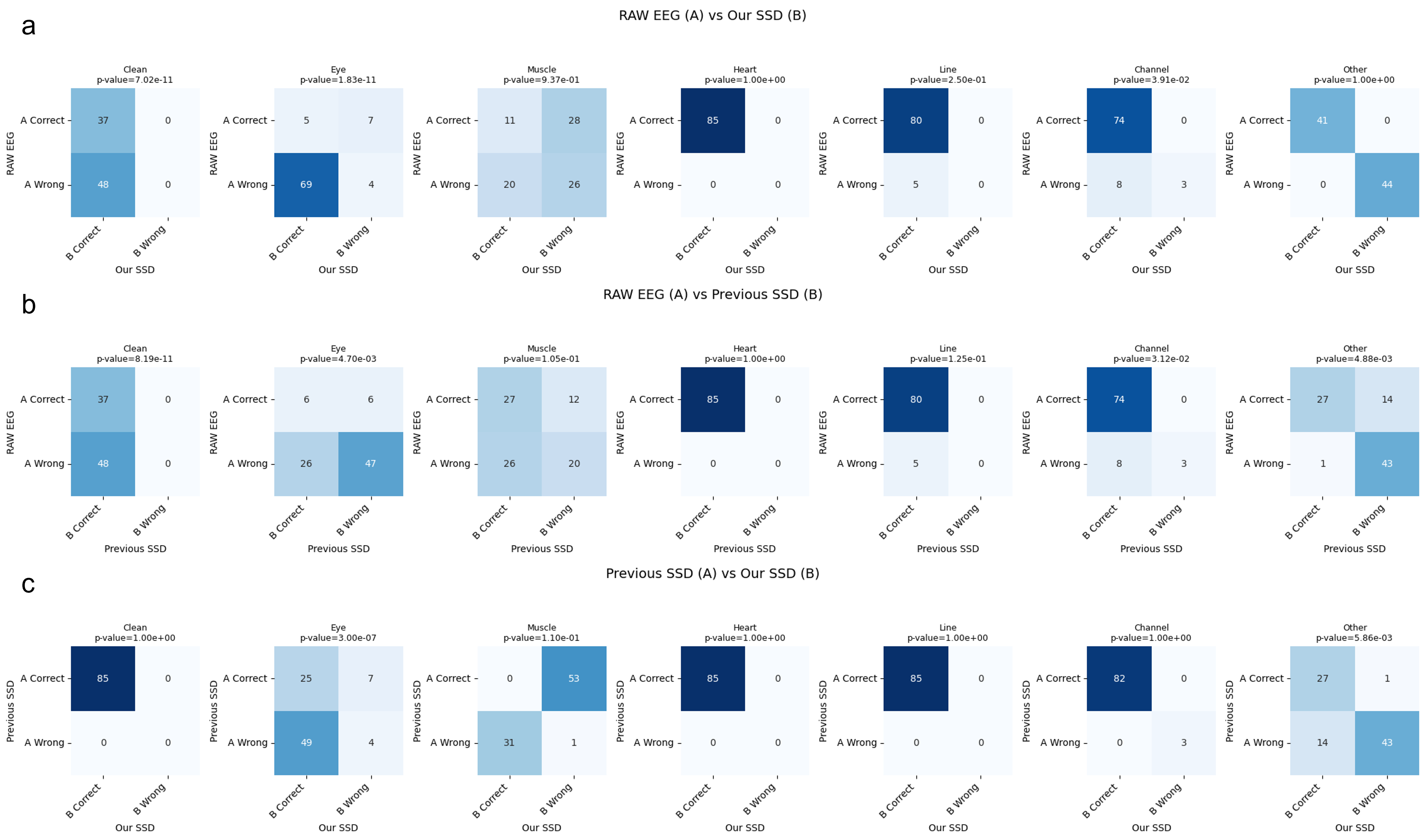
- SSDLabeler-trained classifiers achieved the highest overall accuracy (0.839) on motor execution test data, significantly outperforming raw EEG training (0.772, p<0.05 for Clean, Eye, and Line categories) and prior SSD methods (0.788).
- On instructed-noise session data, the proposed method achieved 0.812 accuracy, demonstrating strong generalization with significant improvements over raw EEG (0.618, p<0.05 for Clean, Eye, and Channel categories) and prior SSD (0.756).
- The framework successfully captures artifact co-occurrence, with the classifier showing balanced performance across most artifact types, though muscle artifact detection remained challenging (accuracy 0.605 vs. 0.785 for prior SSD).
摘要: EEG recordings are inherently contaminated by artifacts such as ocular, muscular, and environmental noise, which obscure neural activity and complicate preprocessing. Artifact classification offers advantages in stability and transparency, providing a viable alternative to ICA-based methods that enable flexible use alongside human inspections and across various applications. However, artifact classification is limited by its training data as it requires extensive manual labeling, which cannot fully cover the diversity of real-world EEG. Semi-synthetic data (SSD) methods have been proposed to address this limitation, but prior approaches typically injected single artifact types using ICA components or required separately recorded artifact signals, reducing both the realism of the generated data and the applicability of the method. To overcome these issues, we introduce SSDLabeler, a framework that generates realistic, annotated SSDs by decomposing real EEG with ICA, epoch-level artifact verification using RMS and PSD criteria, and reinjecting multiple artifact types into clean data. When applied to train a multi-label artifact classifier, it improved accuracy on raw EEG across diverse conditions compared to prior SSD and raw EEG training, establishing a scalable foundation for artifact handling that captures the co-occurrence and complexity of real EEG.