
Paper List
-
A Theoretical Framework for the Formation of Large Animal Groups: Topological Coordination, Subgroup Merging, and Velocity Inheritance
This paper addresses the core problem of how large, coordinated animal groups form in nature, challenging the classical view of gradual aggregation by...
-
CONFIDE: Hallucination Assessment for Reliable Biomolecular Structure Prediction and Design
This paper addresses the critical limitation of current protein structure prediction models (like AlphaFold3) where high-confidence scores (pLDDT) can...
-
Generative design and validation of therapeutic peptides for glioblastoma based on a potential target ATP5A
This paper addresses the critical bottleneck in therapeutic peptide design: how to efficiently optimize lead peptides with geometric constraints while...
-
Pharmacophore-based design by learning on voxel grids
This paper addresses the computational bottleneck and limited novelty in conventional pharmacophore-based virtual screening by introducing a voxel cap...
-
Human-Centred Evaluation of Text-to-Image Generation Models for Self-expression of Mental Distress: A Dataset Based on GPT-4o
This paper addresses the critical gap in evaluating how AI-generated images can effectively support cross-cultural mental distress communication, part...
-
ANNE Apnea Paper
This paper addresses the core challenge of achieving accurate, event-level sleep apnea detection and characterization using a non-intrusive, multimoda...
-
DeeDeeExperiment: Building an infrastructure for integrating and managing omics data analysis results in R/Bioconductor
This paper addresses the critical bottleneck of managing and organizing the growing volume of differential expression and functional enrichment analys...
-
Cross-Species Antimicrobial Resistance Prediction from Genomic Foundation Models
This paper addresses the core challenge of predicting antimicrobial resistance across phylogenetically distinct bacterial species, where traditional m...
Incorporating indel channels into average-case analysis of seed-chain-extend
Carnegie Mellon University, Pittsburgh, PA, USA
30秒速读
IN SHORT: This paper addresses the core pain point of bridging the theoretical gap for the widely used seed-chain-extend heuristic by providing the first rigorous average-case analysis that accounts for insertions and deletions (indels), not just substitutions.
核心创新
- Methodology Introduces a generalized definition of 'recoverability' and a 'homologous path' to mathematically model the correct alignment under indel mutation channels, moving beyond the simpler 'homologous diagonal' used for substitutions only.
- Theory Develops new mathematical machinery to handle the dependence structure of neighboring anchors and the existence of 'clipping anchors' (partially correct anchors), which are unique challenges introduced by indels.
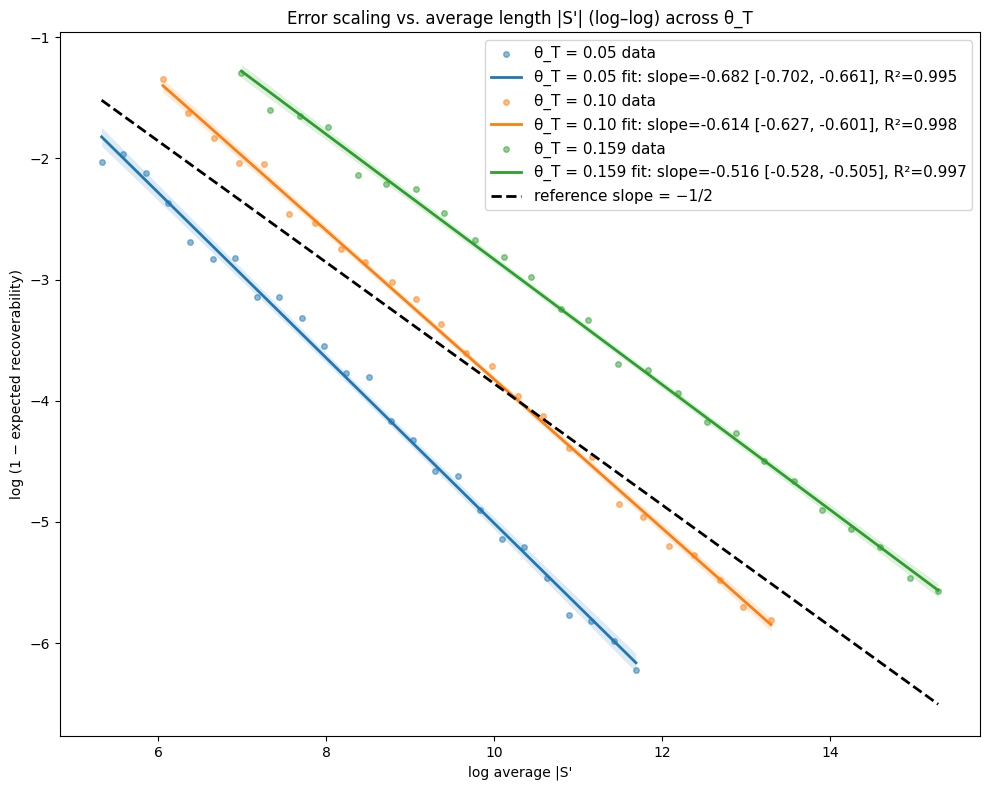
- Theory Proves that under a total mutation rate θ_T < 0.159, optimal linear-gap cost chaining achieves an expected recoverability of ≥ 1 - O(1/√m), generalizing the prior substitution-only result to a biologically realistic model.
主要结论
- The expected recoverability of an optimal chain under linear-gap cost chaining is ≥ 1 - O(1/√m) when the total mutation rate θ_T (sum of substitution, insertion, deletion rates) is less than 0.159.
- The expected runtime of the algorithm is O(m n^(3.15·θ_T) log n). For example, at a θ_T of 0.05 (similar to human-chimp divergence), the exponent is ~1.12, leading to near-linear scaling.
- The analysis successfully bridges theory and practice by extending the proof framework to handle indels, justifying the heuristic's empirical effectiveness on real genomic data which contains indels.
摘要: Given a sequence s1 of n letters drawn i.i.d. from an alphabet of size σ and a mutated substring s2 of length m<n, we often want to recover the mutation history that generated s2 from s1. Modern sequence aligners are widely used for this task, and many employ the seed-chain-extend heuristic with k-mer seeds. Previously, Shaw and Yu showed that optimal linear-gap cost chaining can produce a chain with 1−O(1/m) recoverability, the proportion of the mutation history that is recovered, in O(mn^(2.43θ) log n) expected time, where θ<0.206 is the mutation rate under a substitution-only channel and s1 is assumed to be uniformly random. However, a gap remains between theory and practice, since real genomic data includes insertions and deletions (indels), and yet seed-chain-extend remains effective. In this paper, we generalize those prior results by introducing mathematical machinery to deal with the two new obstacles introduced by indel channels: the dependence of neighboring anchors and the presence of anchors that are only partially correct. We are thus able to prove that the expected recoverability of an optimal chain is ≥1−O(1/√m) and the expected runtime is O(mn^(3.15·θ_T) log n), when the total mutation rate given by the sum of the substitution, insertion, and deletion mutation rates (θ_T = θ_i + θ_d + θ_s) is less than 0.159.