
Paper List
-
Autonomous Agents Coordinating Distributed Discovery Through Emergent Artifact Exchange
This paper addresses the fundamental limitation of current AI-assisted scientific research by enabling truly autonomous, decentralized investigation w...
-
D-MEM: Dopamine-Gated Agentic Memory via Reward Prediction Error Routing
This paper addresses the fundamental scalability bottleneck in LLM agentic memory systems: the O(N²) computational complexity and unbounded API token ...
-
Countershading coloration in blue shark skin emerges from hierarchically organized and spatially tuned photonic architectures inside skin denticles
This paper solves the core problem of how blue sharks achieve their striking dorsoventral countershading camouflage, revealing that coloration origina...
-
Human-like Object Grouping in Self-supervised Vision Transformers
This paper addresses the core challenge of quantifying how well self-supervised vision models capture human-like object grouping in natural scenes, br...
-
Hierarchical pp-Adic Framework for Gene Regulatory Networks: Theory and Stability Analysis
This paper addresses the core challenge of mathematically capturing the inherent hierarchical organization and multi-scale stability of gene regulator...
-
Towards unified brain-to-text decoding across speech production and perception
This paper addresses the core challenge of developing a unified brain-to-text decoding framework that works across both speech production and percepti...
-
Dual-Laws Model for a theory of artificial consciousness
This paper addresses the core challenge of developing a comprehensive, testable theory of consciousness that bridges biological and artificial systems...
-
Pulse desynchronization of neural populations by targeting the centroid of the limit cycle in phase space
This work addresses the core challenge of determining optimal pulse timing and intensity for desynchronizing pathological neural oscillations when the...
Contrastive Deep Learning for Variant Detection in Wastewater Genomic Sequencing
Georgia State University, Atlanta, Georgia, USA
30秒速读
IN SHORT: This paper addresses the core challenge of detecting viral variants in wastewater sequencing data without reference genomes or labeled annotations, overcoming issues of high noise, low coverage, and fragmented reads.
核心创新
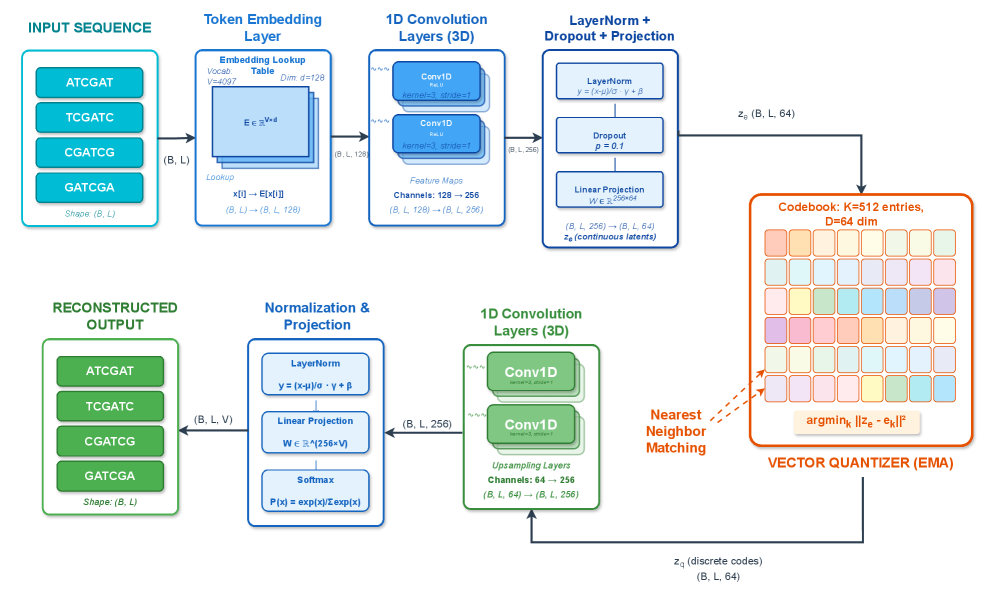
- Methodology First comprehensive application of VQ-VAE with EMA quantization to wastewater genomic surveillance, achieving 99.52% token-level reconstruction accuracy with 19.73% codebook utilization.
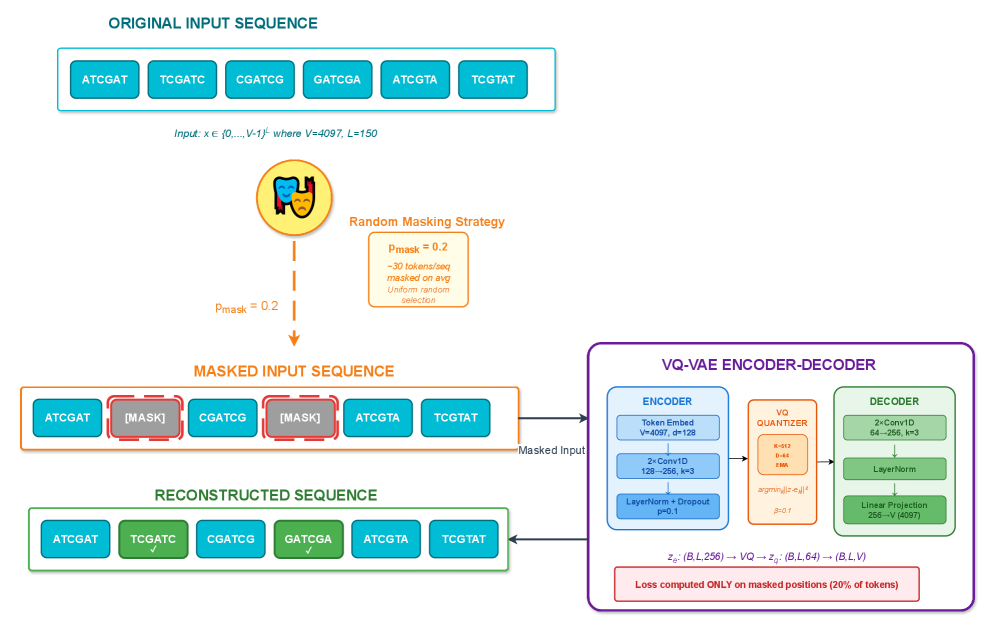
- Methodology Integration of masked reconstruction pretraining (BERT-style) maintaining ~95% accuracy under 20% token corruption, enabling robust inference with missing/low-quality data.
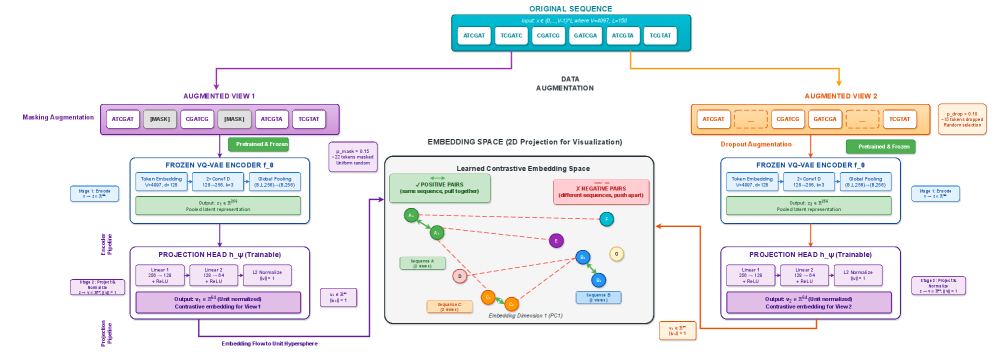
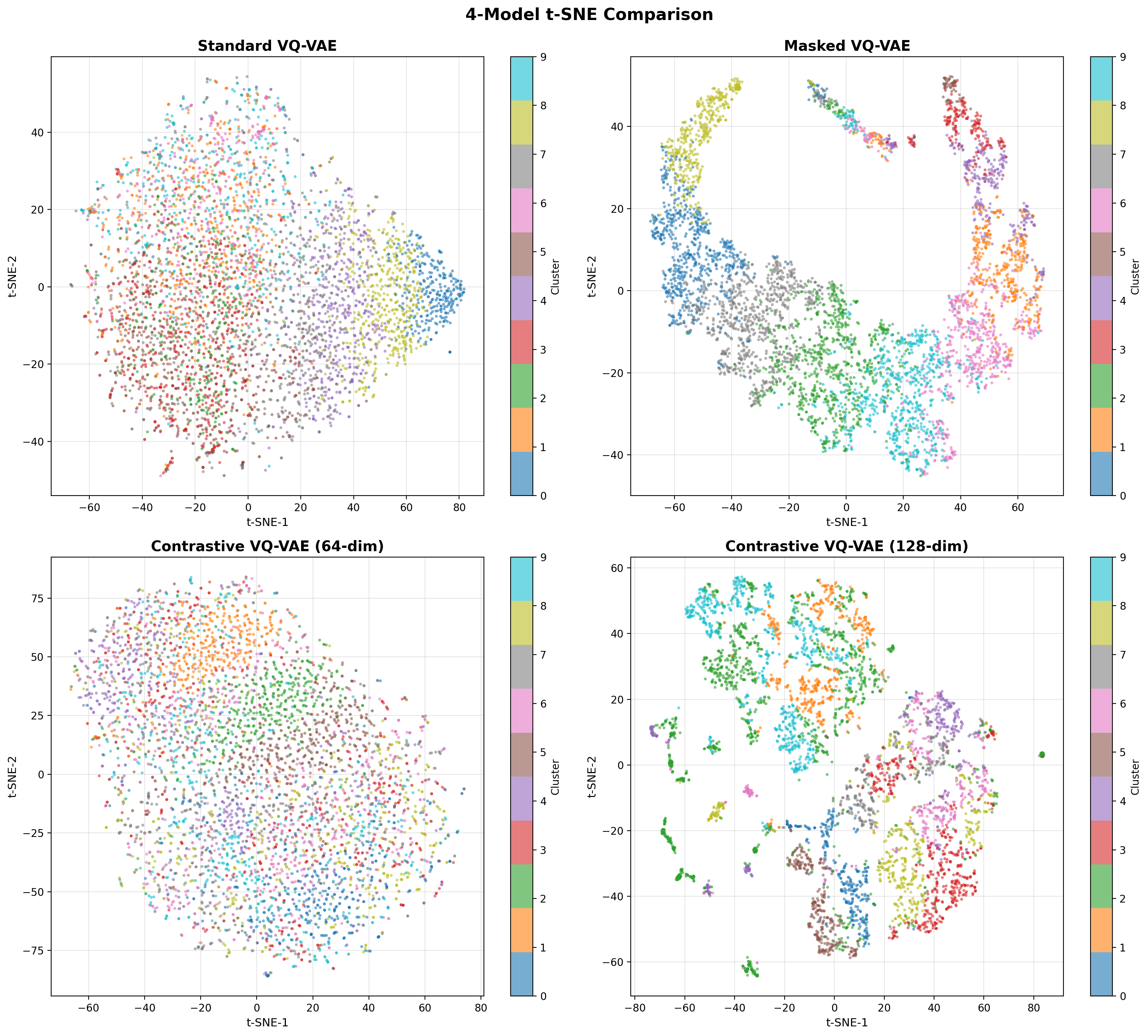
- Methodology Contrastive fine-tuning with varying embedding dimensions showing +35% (64-dim) and +42% (128-dim) Silhouette score improvements, establishing representation capacity impact on variant discrimination.
主要结论
- VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate on SARS-CoV-2 wastewater data with 100,000 reads.
- Contrastive fine-tuning improves clustering performance by +35% (0.31→0.42) with 64-dim embeddings and +42% (0.31→0.44) with 128-dim embeddings.
- The framework maintains efficient codebook utilization (19.73%, 101 of 512 codes active) while providing robust performance under data corruption.
摘要: Wastewater-based genomic surveillance has emerged as a powerful tool for population-level viral monitoring, offering comprehensive insights into circulating viral variants across entire communities. However, this approach faces significant computational challenges stemming from high sequencing noise, low viral coverage, fragmented reads, and the complete absence of labeled variant annotations. Traditional reference-based variant calling pipelines struggle with novel mutations and require extensive computational resources. We present a comprehensive framework for unsupervised viral variant detection using Vector-Quantized Variational Autoencoders (VQ-VAE) that learns discrete codebooks of genomic patterns from k-mer tokenized sequences without requiring reference genomes or variant labels. Our approach extends the base VQ-VAE architecture with masked reconstruction pretraining for robustness to missing data and contrastive learning for highly discriminative embeddings. Evaluated on SARS-CoV-2 wastewater sequencing data comprising approximately 100,000 reads, our VQ-VAE achieves 99.52% mean token-level accuracy and 56.33% exact sequence match rate while maintaining 19.73% codebook utilization (101 of 512 codes active), demonstrating efficient discrete representation learning. Contrastive fine-tuning with different projection dimensions yields substantial clustering improvements: 64-dimensional embeddings achieve +35% Silhouette score improvement (0.31→0.42), while 128-dimensional embeddings achieve +42% improvement (0.31→0.44), clearly demonstrating the impact of embedding dimensionality on variant discrimination capability. Our reference-free framework provides a scalable, interpretable approach to genomic surveillance with direct applications to public health monitoring.