
Paper List
-
Nyxus: A Next Generation Image Feature Extraction Library for the Big Data and AI Era
This paper addresses the core pain point of efficiently extracting standardized, comparable features from massive (terabyte to petabyte-scale) biomedi...
-
Topological Enhancement of Protein Kinetic Stability
This work addresses the long-standing puzzle of why knotted proteins exist by demonstrating that deep knots provide a functional advantage through enh...
-
A Multi-Label Temporal Convolutional Framework for Transcription Factor Binding Characterization
This paper addresses the critical limitation of existing TF binding prediction methods that treat transcription factors as independent entities, faili...
-
Social Distancing Equilibria in Games under Conventional SI Dynamics
This paper solves the core problem of proving the existence and uniqueness of Nash equilibria in finite-duration SI epidemic games, showing they are a...
-
Binding Free Energies without Alchemy
This paper addresses the core bottleneck of computational expense in Absolute Binding Free Energy calculations by eliminating the need for numerous al...
-
SHREC: A Spectral Embedding-Based Approach for Ab-Initio Reconstruction of Helical Molecules
This paper addresses the core bottleneck in cryo-EM helical reconstruction: eliminating the dependency on accurate initial symmetry parameter estimati...
-
Budget-Sensitive Discovery Scoring: A Formally Verified Framework for Evaluating AI-Guided Scientific Selection
This paper addresses the critical gap in evaluating AI-guided scientific selection strategies under realistic budget constraints, where existing metri...
-
Probabilistic Joint and Individual Variation Explained (ProJIVE) for Data Integration
This paper addresses the core challenge of accurately decomposing shared (joint) and dataset-specific (individual) sources of variation in multi-modal...
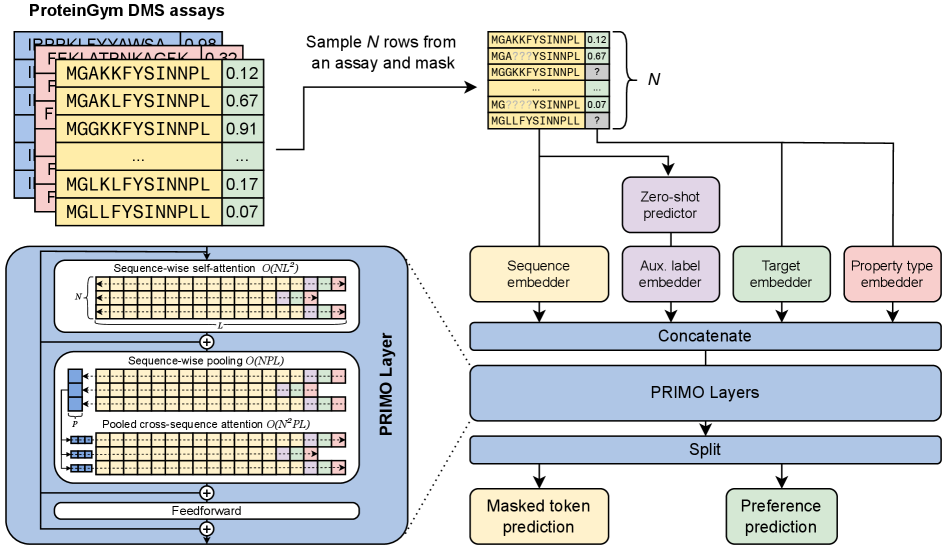
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.