
Paper List
-
Translating Measures onto Mechanisms: The Cognitive Relevance of Higher-Order Information
This review addresses the core challenge of translating abstract higher-order information theory metrics (e.g., synergy, redundancy) into defensible, ...
-
Emergent Bayesian Behaviour and Optimal Cue Combination in LLMs
This paper addresses the critical gap in understanding whether LLMs spontaneously develop human-like Bayesian strategies for processing uncertain info...
-
Vessel Network Topology in Molecular Communication: Insights from Experiments and Theory
This work addresses the critical lack of experimentally validated channel models for molecular communication within complex vessel networks, which is ...
-
Modulation of DNA rheology by a transcription factor that forms aging microgels
This work addresses the fundamental question of how the transcription factor NANOG, essential for embryonic stem cell pluripotency, physically regulat...
-
Imperfect molecular detection renormalizes apparent kinetic rates in stochastic gene regulatory networks
This paper addresses the core challenge of distinguishing genuine stochastic dynamics of gene regulatory networks from artifacts introduced by imperfe...
-
PanFoMa: A Lightweight Foundation Model and Benchmark for Pan-Cancer
This paper addresses the dual challenge of achieving computational efficiency without sacrificing accuracy in whole-transcriptome single-cell represen...
-
Beyond Bayesian Inference: The Correlation Integral Likelihood Framework and Gradient Flow Methods for Deterministic Sampling
This paper addresses the core challenge of calibrating complex biological models (e.g., PDEs, agent-based models) with incomplete, noisy, or heterogen...
-
Contrastive Deep Learning for Variant Detection in Wastewater Genomic Sequencing
This paper addresses the core challenge of detecting viral variants in wastewater sequencing data without reference genomes or labeled annotations, ov...
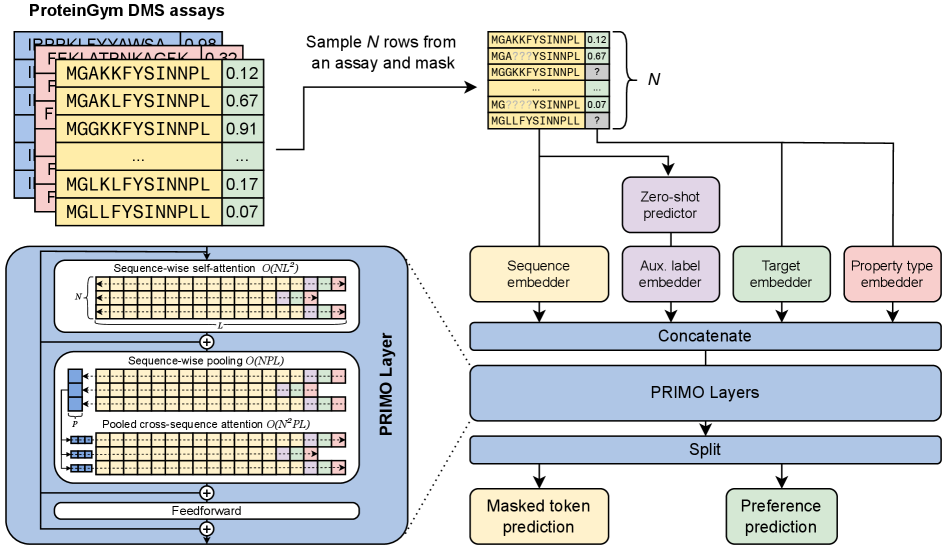
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.