
Paper List
-
Discovery of a Hematopoietic Manifold in scGPT Yields a Method for Extracting Performant Algorithms from Biological Foundation Model Internals
This work addresses the core challenge of extracting reusable, interpretable, and high-performance biological algorithms from the opaque internal repr...
-
MS2MetGAN: Latent-space adversarial training for metabolite–spectrum matching in MS/MS database search
This paper addresses the critical bottleneck in metabolite identification: the generation of high-quality negative training samples that are structura...
-
Toward Robust, Reproducible, and Widely Accessible Intracranial Language Brain-Computer Interfaces: A Comprehensive Review of Neural Mechanisms, Hardware, Algorithms, Evaluation, Clinical Pathways and Future Directions
This review addresses the core challenge of fragmented and heterogeneous evidence that hinders the clinical translation of intracranial language BCIs,...
-
Less Is More in Chemotherapy of Breast Cancer
通过纳入细胞周期时滞和竞争项,解决了现有肿瘤-免疫模型的过度简化问题,以定量比较化疗方案。
-
Fold-CP: A Context Parallelism Framework for Biomolecular Modeling
This paper addresses the critical bottleneck of GPU memory limitations that restrict AlphaFold 3-like models to processing only a few thousand residue...
-
Open Biomedical Knowledge Graphs at Scale: Construction, Federation, and AI Agent Access with Samyama Graph Database
This paper addresses the core pain point of fragmented biomedical data by constructing and federating large-scale, open knowledge graphs to enable sea...
-
Predictive Analytics for Foot Ulcers Using Time-Series Temperature and Pressure Data
This paper addresses the critical need for continuous, real-time monitoring of diabetic foot health by developing an unsupervised anomaly detection fr...
-
Hypothesis-Based Particle Detection for Accurate Nanoparticle Counting and Digital Diagnostics
This paper addresses the core challenge of achieving accurate, interpretable, and training-free nanoparticle counting in digital diagnostic assays, wh...
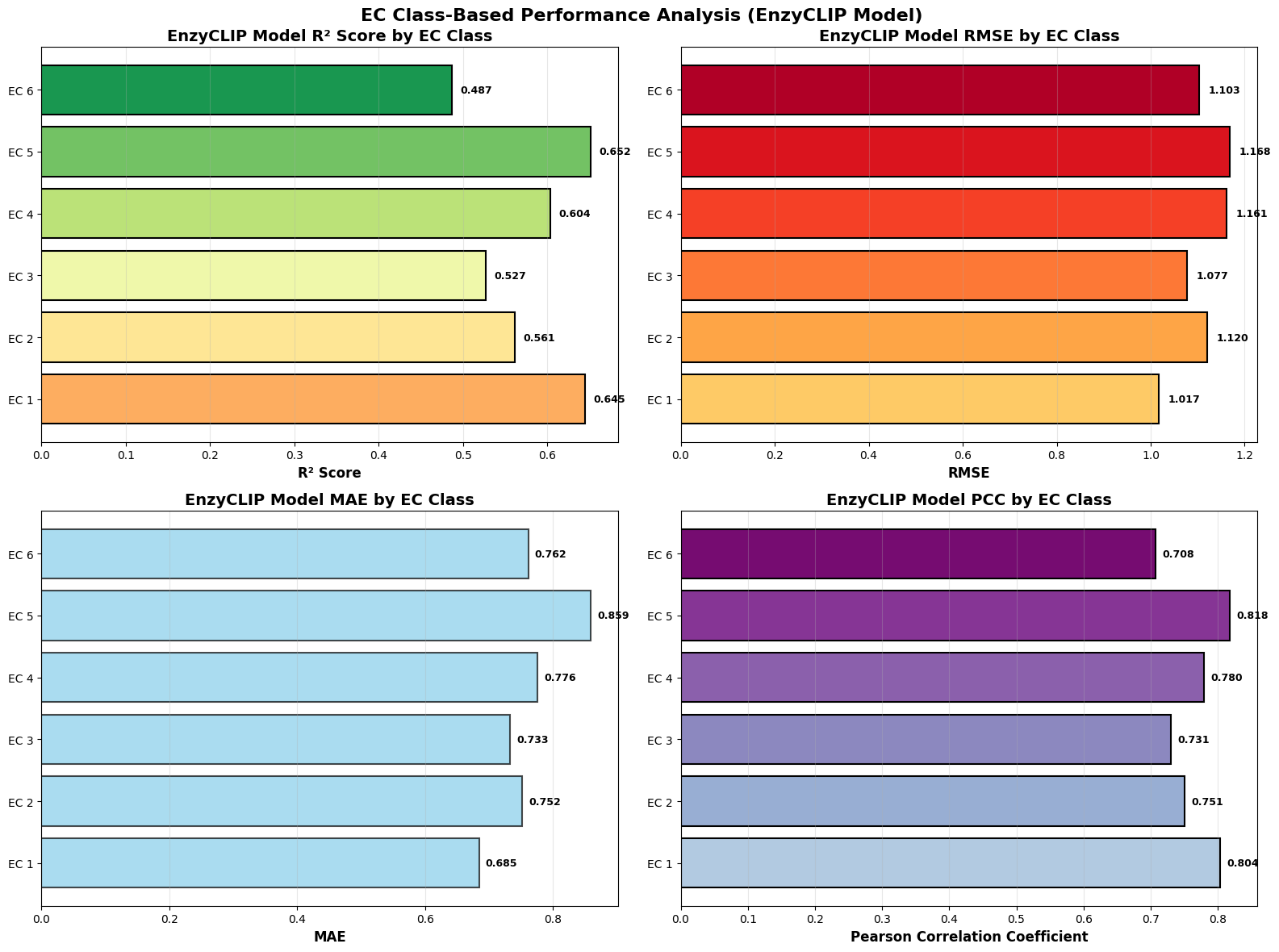
EnzyCLIP: A Cross-Attention Dual Encoder Framework with Contrastive Learning for Predicting Enzyme Kinetic Constants
Vellore Institute of Technology | BIT (Department of Computer Science) | BIT (Department of Bioengineering and Biotechnology)
30秒速读
IN SHORT: This paper addresses the core challenge of jointly predicting enzyme kinetic parameters (Kcat and Km) by modeling dynamic enzyme-substrate interactions through a multimodal contrastive learning framework.
核心创新
- Methodology Proposes a CLIP-inspired dual-encoder architecture with bidirectional cross-attention that dynamically models enzyme-substrate interactions, overcoming the limitation of separate processing in existing methods.
- Methodology Integrates contrastive learning (InfoNCE loss) with multi-task regression (Huber loss) to learn aligned multimodal representations while jointly predicting both Kcat and Km parameters.
- Biology Addresses the critical gap in existing literature that typically focuses on single parameter prediction (mainly Kcat) by providing a unified framework for joint prediction of both fundamental kinetic constants.
主要结论
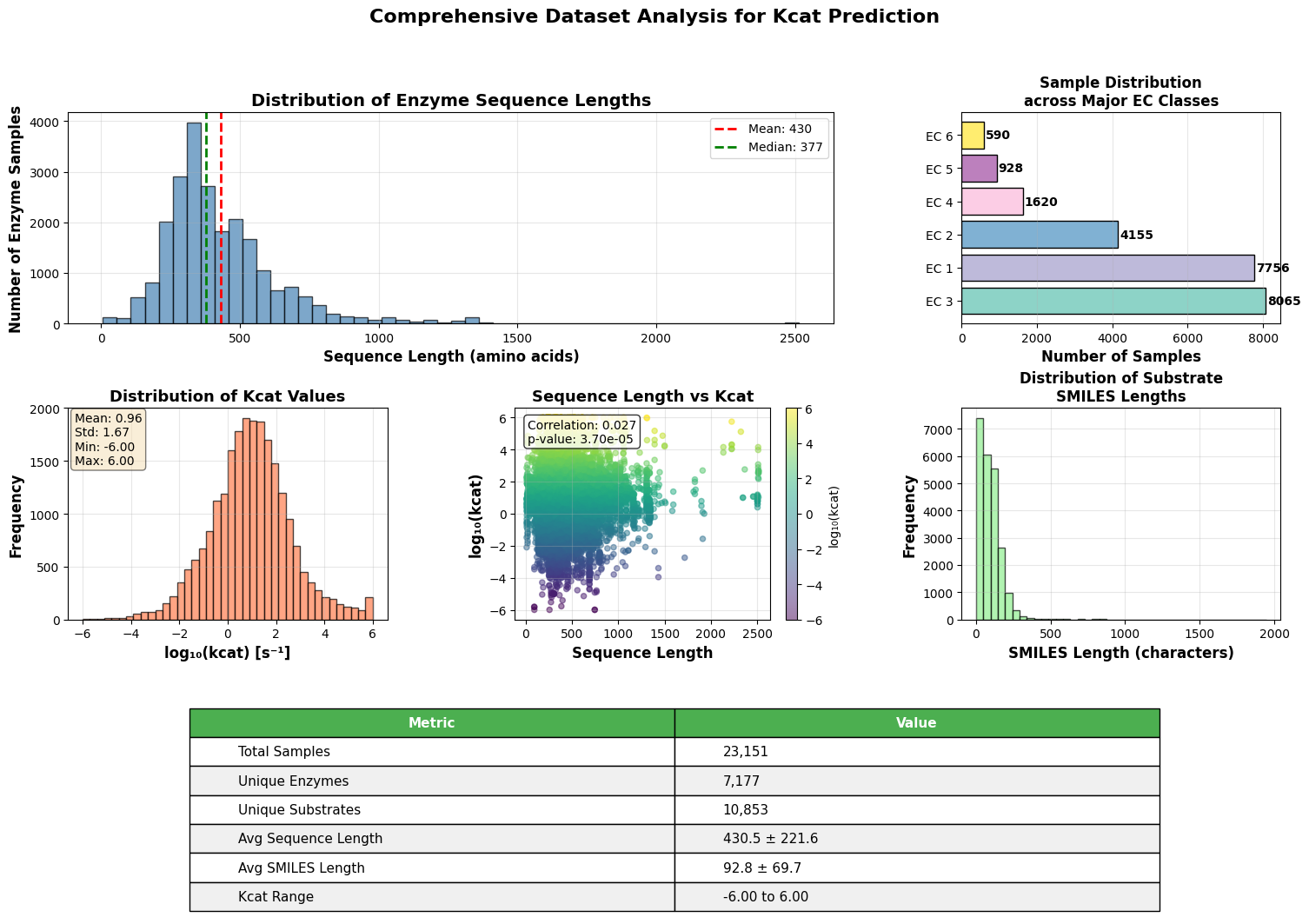
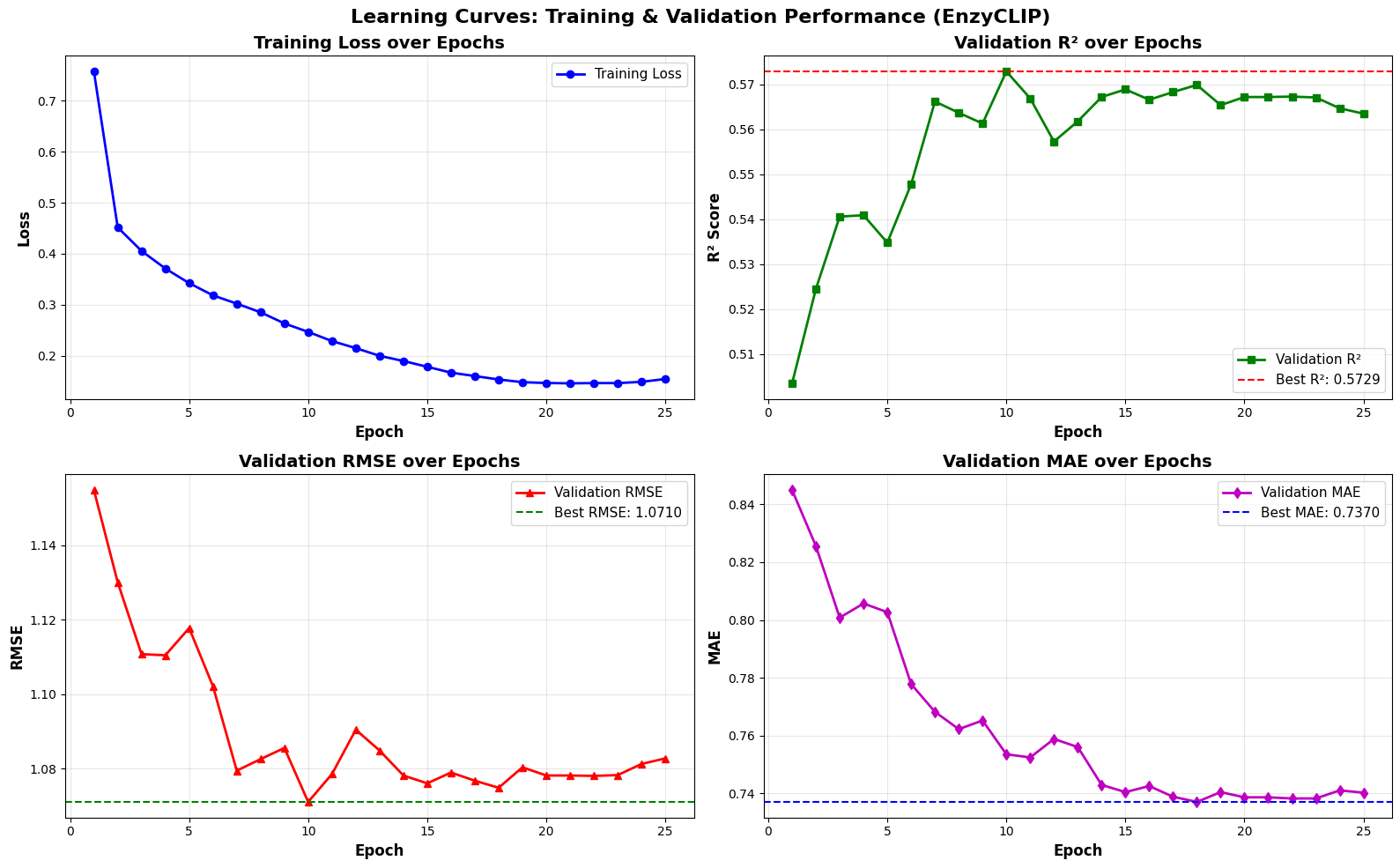
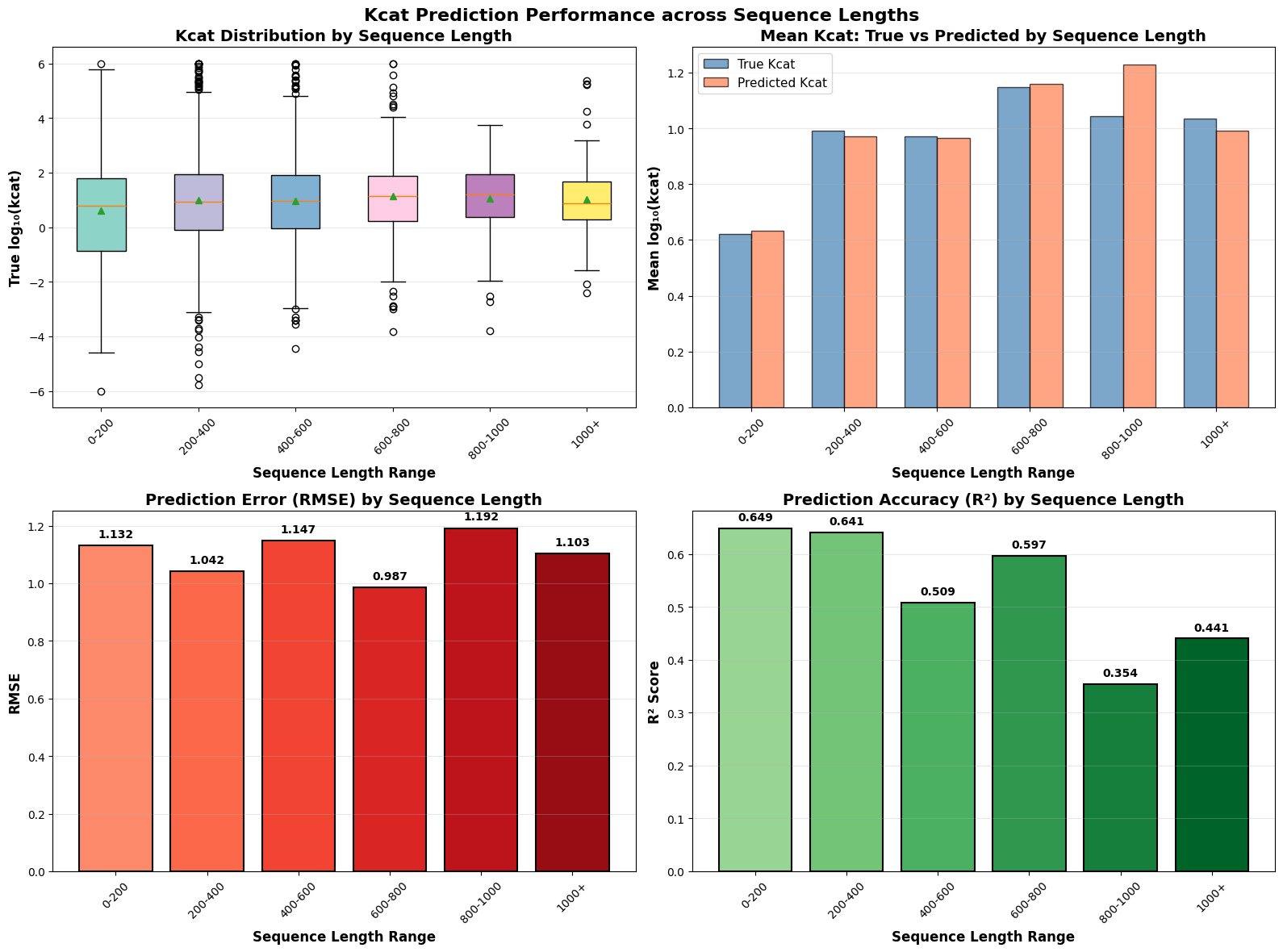
- EnzyCLIP achieves competitive baseline performance with R² scores of 0.593 for Kcat and 0.607 for Km prediction on the CatPred-DB dataset containing 23,151 Kcat and 41,174 Km measurements.
- The integration of contrastive learning with cross-attention mechanisms enables the model to capture biochemical relationships and substrate preferences even for unseen enzyme-substrate pairs.
- XGBoost ensemble methods applied to learned embeddings further improved Km prediction performance to R² = 0.61 while maintaining robust Kcat prediction capabilities.
摘要: Accurate prediction of enzyme kinetic parameters is crucial for drug discovery, metabolic engineering, and synthetic biology applications. Current computational approaches face limitations in capturing complex enzyme–substrate interactions and often focus on single parameters while neglecting the joint prediction of catalytic turnover numbers (Kcat) and Michaelis–Menten constants (Km). We present EnzyCLIP, a novel dual-encoder framework that leverages contrastive learning and cross-attention mechanisms to predict enzyme kinetic parameters from protein sequences and substrate molecular structures. Our approach integrates ESM-2 protein language model embeddings with ChemBERTa chemical representations through a CLIP-inspired architecture enhanced with bidirectional cross-attention for dynamic enzyme–substrate interaction modeling. EnzyCLIP combines InfoNCE contrastive loss with Huber regression loss to learn aligned multimodal representations while predicting log10-transformed kinetic parameters. EnzyCLIP is trained on the CatPred-DB database containing 23,151 Kcat and 41,174 Km experimentally validated measurements, and achieved competitive baseline performance with R2 scores of 0.593 for Kcat and 0.607 for Km prediction. XGBoost ensemble methods on learned embeddings further improved Km prediction (R2 = 0.61) while maintaining robust Kcat performance.