
Paper List
-
Discovery of a Hematopoietic Manifold in scGPT Yields a Method for Extracting Performant Algorithms from Biological Foundation Model Internals
This work addresses the core challenge of extracting reusable, interpretable, and high-performance biological algorithms from the opaque internal repr...
-
MS2MetGAN: Latent-space adversarial training for metabolite–spectrum matching in MS/MS database search
This paper addresses the critical bottleneck in metabolite identification: the generation of high-quality negative training samples that are structura...
-
Toward Robust, Reproducible, and Widely Accessible Intracranial Language Brain-Computer Interfaces: A Comprehensive Review of Neural Mechanisms, Hardware, Algorithms, Evaluation, Clinical Pathways and Future Directions
This review addresses the core challenge of fragmented and heterogeneous evidence that hinders the clinical translation of intracranial language BCIs,...
-
Less Is More in Chemotherapy of Breast Cancer
通过纳入细胞周期时滞和竞争项,解决了现有肿瘤-免疫模型的过度简化问题,以定量比较化疗方案。
-
Fold-CP: A Context Parallelism Framework for Biomolecular Modeling
This paper addresses the critical bottleneck of GPU memory limitations that restrict AlphaFold 3-like models to processing only a few thousand residue...
-
Open Biomedical Knowledge Graphs at Scale: Construction, Federation, and AI Agent Access with Samyama Graph Database
This paper addresses the core pain point of fragmented biomedical data by constructing and federating large-scale, open knowledge graphs to enable sea...
-
Predictive Analytics for Foot Ulcers Using Time-Series Temperature and Pressure Data
This paper addresses the critical need for continuous, real-time monitoring of diabetic foot health by developing an unsupervised anomaly detection fr...
-
Hypothesis-Based Particle Detection for Accurate Nanoparticle Counting and Digital Diagnostics
This paper addresses the core challenge of achieving accurate, interpretable, and training-free nanoparticle counting in digital diagnostic assays, wh...
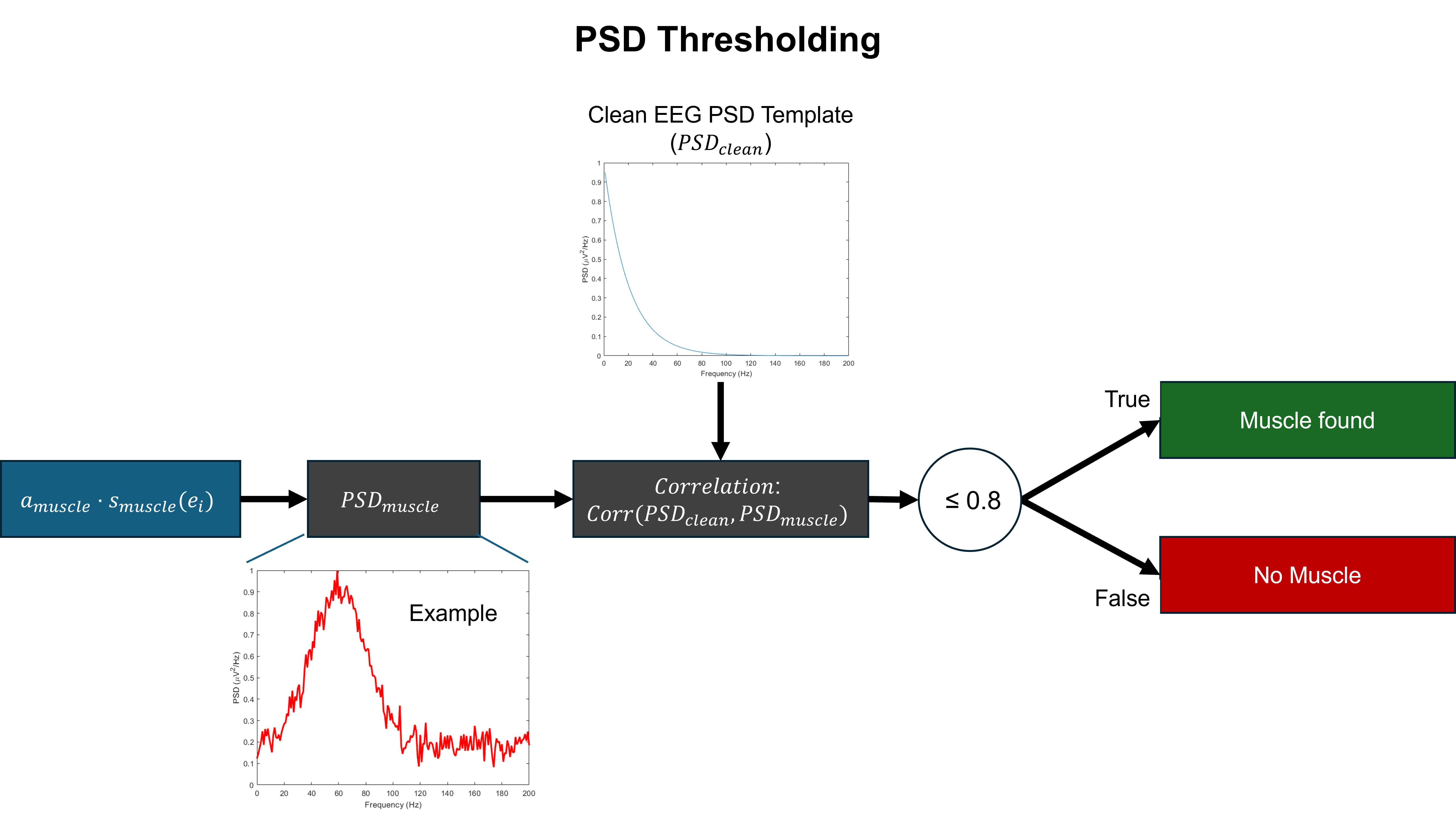
SSDLabeler: Realistic semi-synthetic data generation for multi-label artifact classification in EEG
Sony Computer Science Laboratories, Inc., Tokyo, Japan
30秒速读
IN SHORT: This paper addresses the core challenge of training robust multi-label EEG artifact classifiers by overcoming the scarcity and limited diversity of manually labeled training data through a novel semi-synthetic data generation framework.
核心创新
- Methodology Introduces SSDLabeler, a framework that generates realistic semi-synthetic EEG data by simultaneously reinjecting multiple ICA-isolated artifact types into clean data, preserving the co-occurrence structure of real-world contamination.
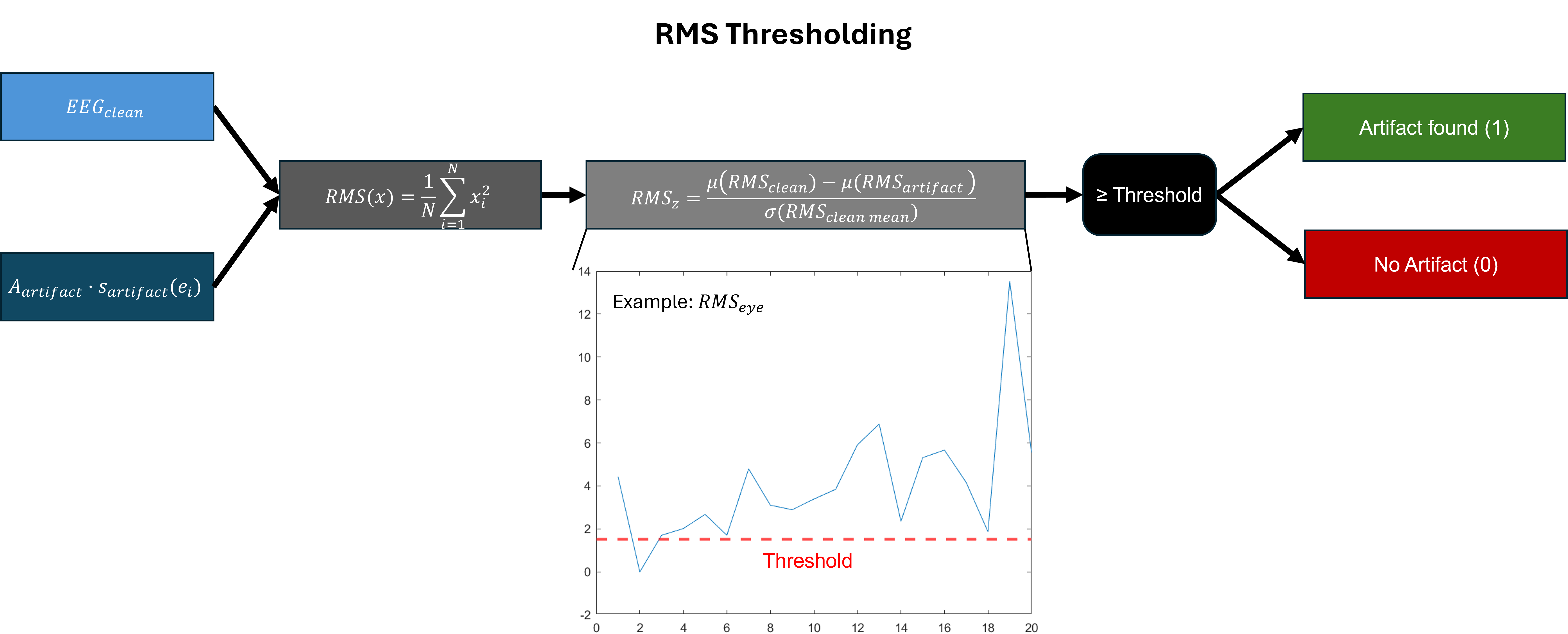
- Methodology Develops a novel artifact verification step using RMS and PSD thresholding criteria at the epoch level to ensure the physiological plausibility of generated contaminations, moving beyond simple ICA component injection.
- Biology Proposes a multi-label artifact classification paradigm that identifies multiple co-occurring artifact types (eye, muscle, heart, line, channel, other) within single EEG epochs, providing transparent contamination information for flexible preprocessing decisions.
主要结论
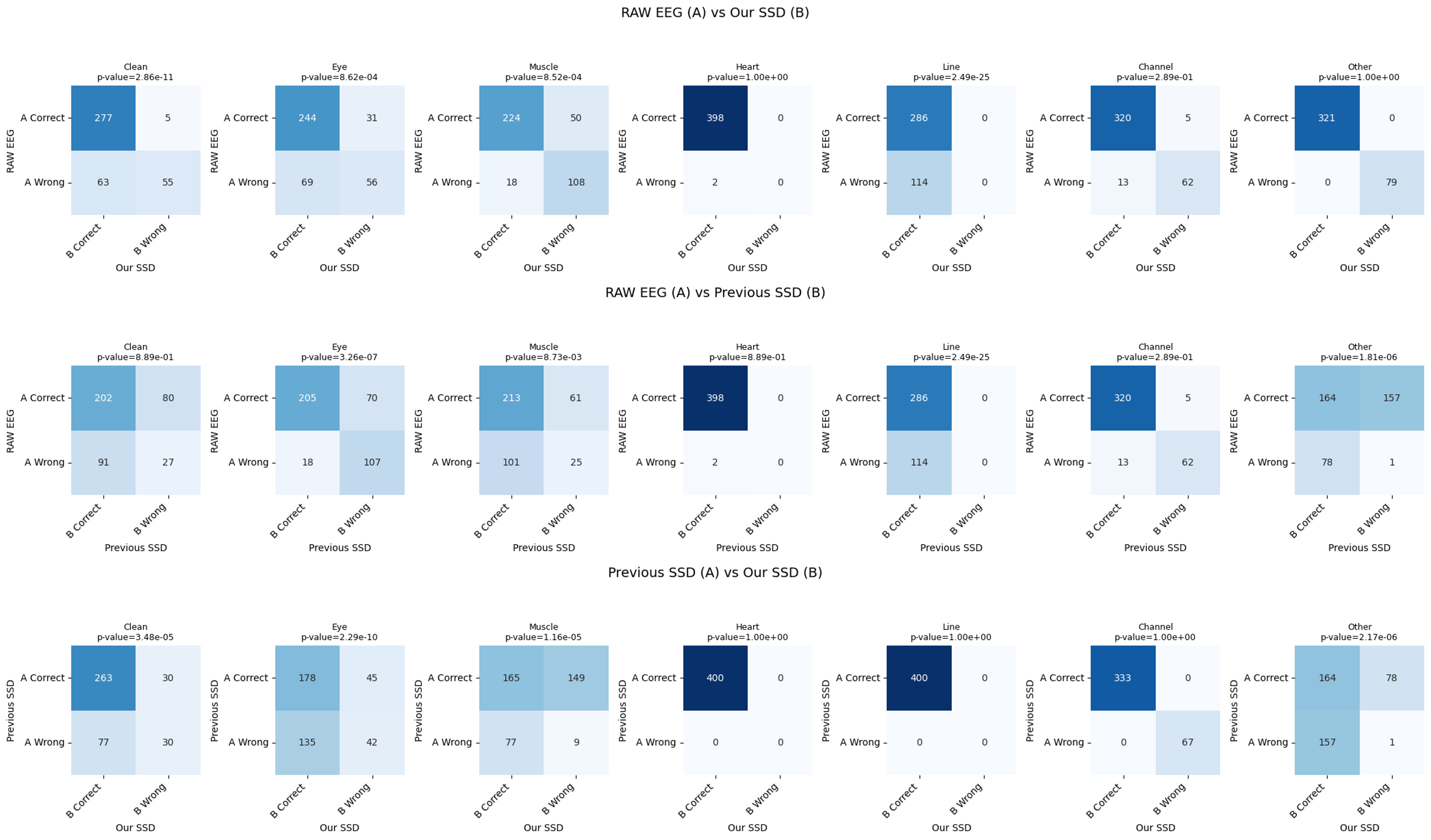
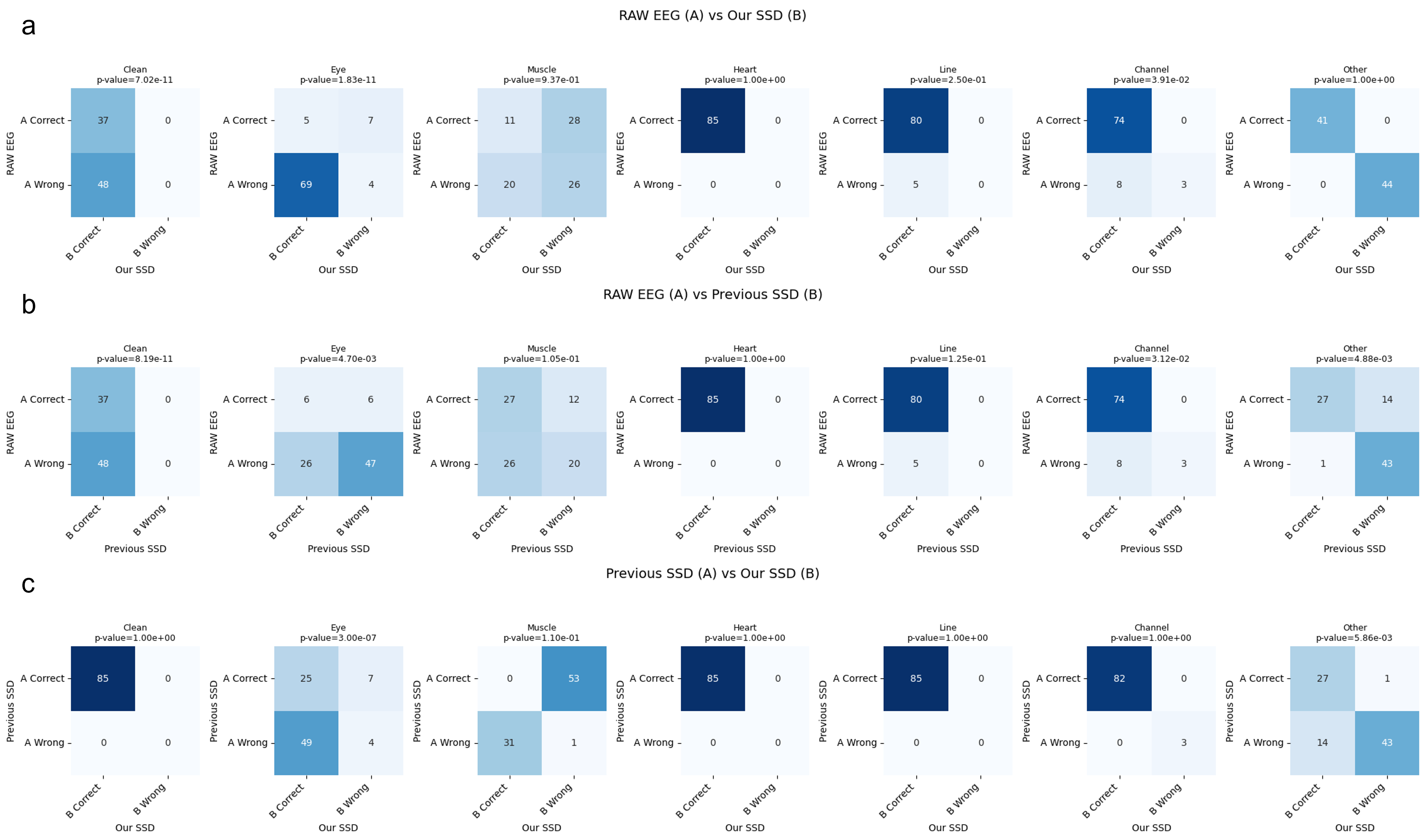
- SSDLabeler-trained classifiers achieved the highest overall accuracy (0.839) on motor execution test data, significantly outperforming raw EEG training (0.772, p<0.05 for Clean, Eye, and Line categories) and prior SSD methods (0.788).
- On instructed-noise session data, the proposed method achieved 0.812 accuracy, demonstrating strong generalization with significant improvements over raw EEG (0.618, p<0.05 for Clean, Eye, and Channel categories) and prior SSD (0.756).
- The framework successfully captures artifact co-occurrence, with the classifier showing balanced performance across most artifact types, though muscle artifact detection remained challenging (accuracy 0.605 vs. 0.785 for prior SSD).
摘要: EEG recordings are inherently contaminated by artifacts such as ocular, muscular, and environmental noise, which obscure neural activity and complicate preprocessing. Artifact classification offers advantages in stability and transparency, providing a viable alternative to ICA-based methods that enable flexible use alongside human inspections and across various applications. However, artifact classification is limited by its training data as it requires extensive manual labeling, which cannot fully cover the diversity of real-world EEG. Semi-synthetic data (SSD) methods have been proposed to address this limitation, but prior approaches typically injected single artifact types using ICA components or required separately recorded artifact signals, reducing both the realism of the generated data and the applicability of the method. To overcome these issues, we introduce SSDLabeler, a framework that generates realistic, annotated SSDs by decomposing real EEG with ICA, epoch-level artifact verification using RMS and PSD criteria, and reinjecting multiple artifact types into clean data. When applied to train a multi-label artifact classifier, it improved accuracy on raw EEG across diverse conditions compared to prior SSD and raw EEG training, establishing a scalable foundation for artifact handling that captures the co-occurrence and complexity of real EEG.