
Paper List
-
Formation of Artificial Neural Assemblies by Biologically Plausible Inhibition Mechanisms
This work addresses the core limitation of the Assembly Calculus model—its fixed-size, biologically implausible k-WTA selection process—by introducing...
-
How to make the most of your masked language model for protein engineering
This paper addresses the critical bottleneck of efficiently sampling high-quality, diverse protein sequences from Masked Language Models (MLMs) for pr...
-
Module control in youth symptom networks across COVID-19
This paper addresses the core challenge of distinguishing whether a prolonged societal stressor (COVID-19) fundamentally reorganizes the architecture ...
-
JEDI: Jointly Embedded Inference of Neural Dynamics
This paper addresses the core challenge of inferring context-dependent neural dynamics from noisy, high-dimensional recordings using a single unified ...
-
ATP Level and Phosphorylation Free Energy Regulate Trigger-Wave Speed and Critical Nucleus Size in Cellular Biochemical Systems
This work addresses the core challenge of quantitatively predicting how the cellular energy state (ATP level and phosphorylation free energy) governs ...
-
Packaging Jupyter notebooks as installable desktop apps using LabConstrictor
This paper addresses the core pain point of ensuring Jupyter notebook reproducibility and accessibility across different computing environments, parti...
-
SNPgen: Phenotype-Supervised Genotype Representation and Synthetic Data Generation via Latent Diffusion
This paper addresses the core challenge of generating privacy-preserving synthetic genotype data that maintains both statistical fidelity and downstre...
-
Continuous Diffusion Transformers for Designing Synthetic Regulatory Elements
This paper addresses the challenge of efficiently generating novel, cell-type-specific regulatory DNA sequences with high predicted activity while min...
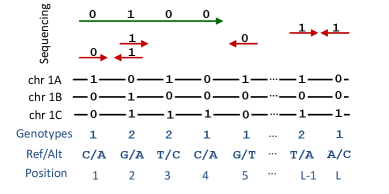
pHapCompass: Probabilistic Assembly and Uncertainty Quantification of Polyploid Haplotype Phase
School of Computing, University of Connecticut | Department of Entomology and Plant Pathology, University of Tennessee | Institute for Systems Genomics, University of Connecticut
30秒速读
IN SHORT: This paper addresses the core challenge of accurately assembling polyploid haplotypes from sequencing data, where read assignment ambiguity and an exponential search space of possible phasings have hindered reliable reconstruction and uncertainty quantification.
核心创新
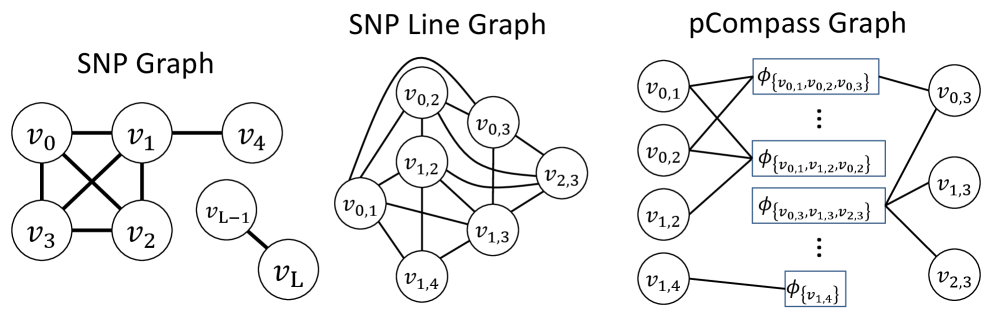
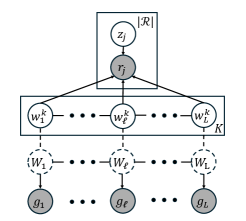
- Methodology Introduces pHapCompass, the first probabilistic haplotype assembler for diploid and polyploid genomes that explicitly models read assignment ambiguity to compute a distribution over haplotype phasings, enabling formal uncertainty quantification.
- Methodology Develops two distinct graph-theoretic algorithms: pHapCompass-short (a Markov random field for high-coverage short reads) and pHapCompass-long (a hierarchical mixture model for low-coverage long reads), both designed to scale with genomic complexity.
- Methodology Creates the first computational workflow for simulating realistic auto- and allopolyploid genomes and sequencing data, addressing a critical gap in benchmarking tools that previously relied on oversimplified synthetic genomes.
主要结论
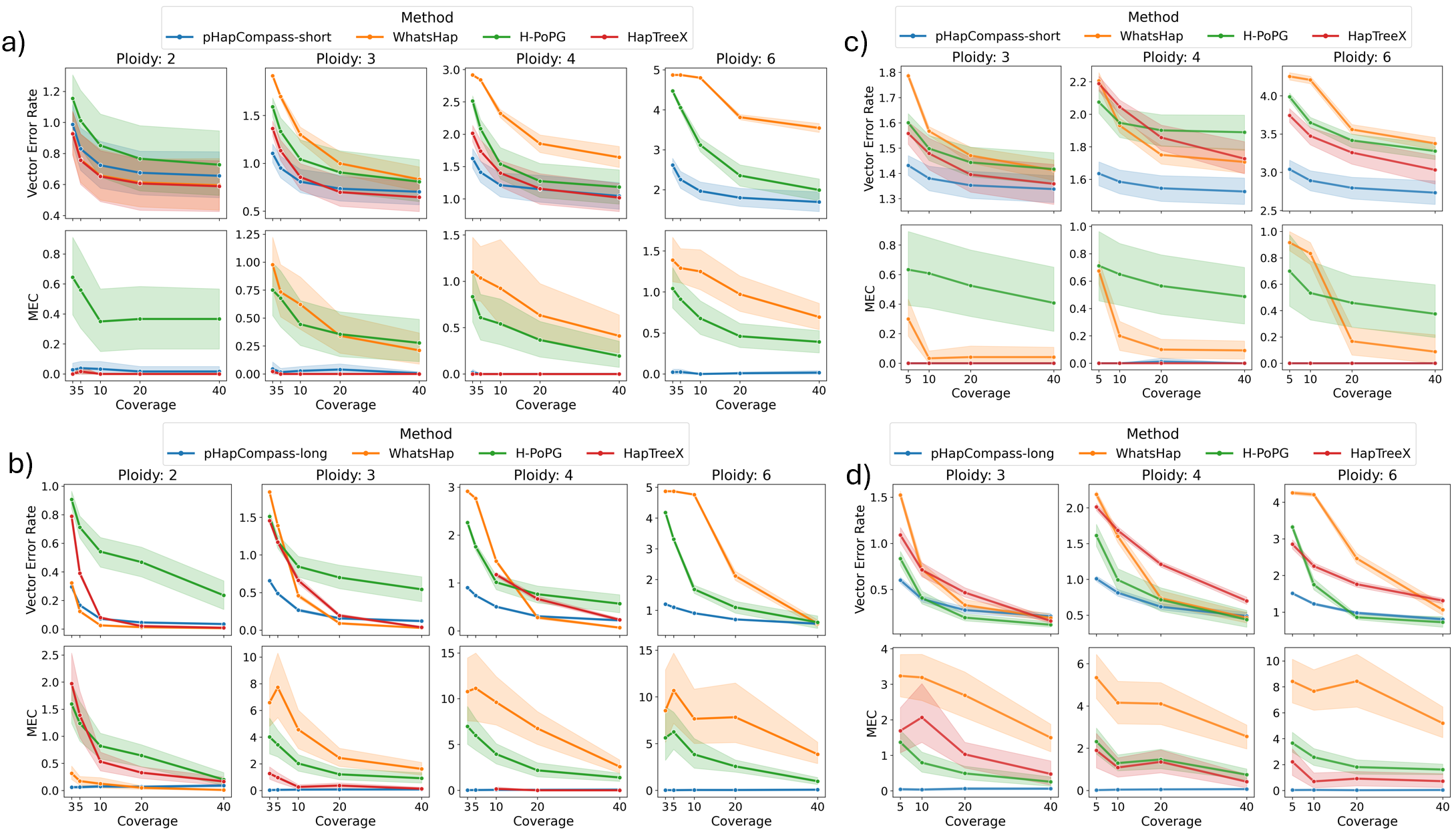
- pHapCompass demonstrates competitive performance against existing assemblers across varying ploidy levels, coverage depths, and mutation rates, while uniquely providing accurate quantification of phase uncertainty.
- The developed simulation workflow generates more realistic benchmarking datasets, revealing that prior methods often overestimate performance on simplistic synthetic genomes.
- The framework successfully assembled an allo-octoploid strawberry chromosome, showcasing practical applicability to complex, real-world polyploid genomes.
摘要: Computing haplotypes from sequencing data, i.e. haplotype assembly, is an important component of foundational molecular and population genetics problems, including interpreting the effects of genetic variation on complex traits and reconstructing genealogical relationships. Assembling the haplotypes of polyploid genomes remains a significant challenge due to the exponential search space of haplotype phasings and read assignment ambiguity; the latter challenge is particularly difficult for polyploid haplotype assemblers since the information contained within the observed sequence reads is often insufficient for unambiguous haplotype assignment in polyploid genomes. We present pHapCompass, probabilistic haplotype assembly algorithms for diploid and polyploid genomes that explicitly model and propagate read assignment ambiguity to compute a distribution over polyploid haplotype phasings. We develop graph theoretic algorithms to enable statistical inference and uncertainty quantification despite an exponential space of possible phasings. Since prior work evaluates polyploid haplotype assembly on synthetic genomes that do not reflect the realistic genomic complexity of polyploidy organisms, we develop a computational workflow for simulating genomes and DNA-seq for auto- and allopolyploids. Additionally, we generalize the vector error rate and minimum error correction evaluation criteria for partially phased haplotypes. Benchmarking of pHapCompass and several existing polyploid haplotype assemblers shows that pHapCompass yields competitive performance across varying genomic complexities and polyploid structures while retaining an accurate quantification of phase uncertainty. The source code for pHapCompass, simulation scripts, and datasets are freely available at https://github.com/bayesomicslab/pHapCompass.