
Paper List
-
GOPHER: Optimization-based Phenotype Randomization for Genome-Wide Association Studies with Differential Privacy
This paper addresses the core challenge of balancing rigorous privacy protection with data utility when releasing full GWAS summary statistics, overco...
-
Real-time Cricket Sorting By Sex A low-cost embedded solution using YOLOv8 and Raspberry Pi
This paper addresses the critical bottleneck in industrial insect farming: the lack of automated, real-time sex sorting systems for Acheta domesticus ...
-
Training Dynamics of Learning 3D-Rotational Equivariance
This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with dat...
-
Fast and Accurate Node-Age Estimation Under Fossil Calibration Uncertainty Using the Adjusted Pairwise Likelihood
This paper addresses the dual challenge of computational inefficiency and sensitivity to fossil calibration errors in Bayesian divergence time estimat...
-
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collecti...
-
scCluBench: Comprehensive Benchmarking of Clustering Algorithms for Single-Cell RNA Sequencing
This paper addresses the critical gap of fragmented and non-standardized benchmarking in single-cell RNA-seq clustering, which hinders objective compa...
-
Simulation and inference methods for non-Markovian stochastic biochemical reaction networks
This paper addresses the computational bottleneck of simulating and performing Bayesian inference for non-Markovian biochemical systems with history-d...
-
Assessment of Simulation-based Inference Methods for Stochastic Compartmental Models
This paper addresses the core challenge of performing accurate Bayesian parameter inference for stochastic epidemic models when the likelihood functio...
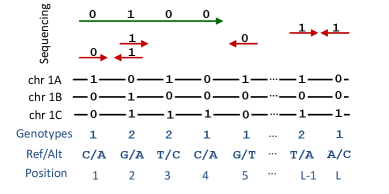
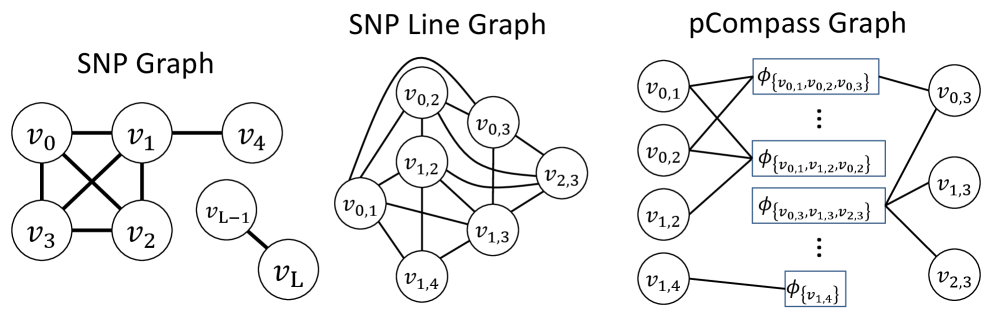
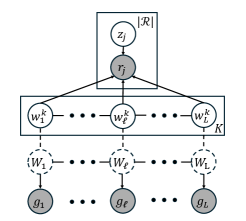
pHapCompass: Probabilistic Assembly and Uncertainty Quantification of Polyploid Haplotype Phase
School of Computing, University of Connecticut | Department of Entomology and Plant Pathology, University of Tennessee | Institute for Systems Genomics, University of Connecticut
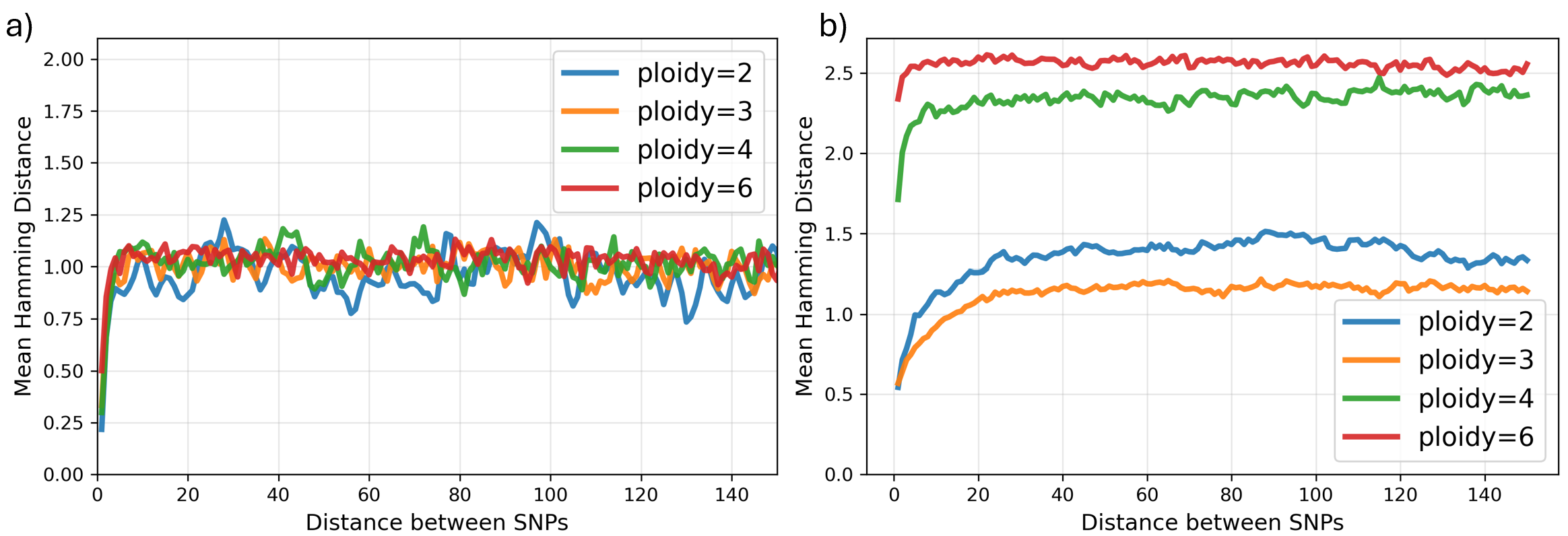
30秒速读
IN SHORT: This paper addresses the core challenge of accurately assembling polyploid haplotypes from sequencing data, where read assignment ambiguity and an exponential search space of possible phasings have hindered reliable reconstruction and uncertainty quantification.
核心创新
- Methodology Introduces pHapCompass, the first probabilistic haplotype assembler for diploid and polyploid genomes that explicitly models read assignment ambiguity to compute a distribution over haplotype phasings, enabling formal uncertainty quantification.
- Methodology Develops two distinct graph-theoretic algorithms: pHapCompass-short (a Markov random field for high-coverage short reads) and pHapCompass-long (a hierarchical mixture model for low-coverage long reads), both designed to scale with genomic complexity.
- Methodology Creates the first computational workflow for simulating realistic auto- and allopolyploid genomes and sequencing data, addressing a critical gap in benchmarking tools that previously relied on oversimplified synthetic genomes.
主要结论
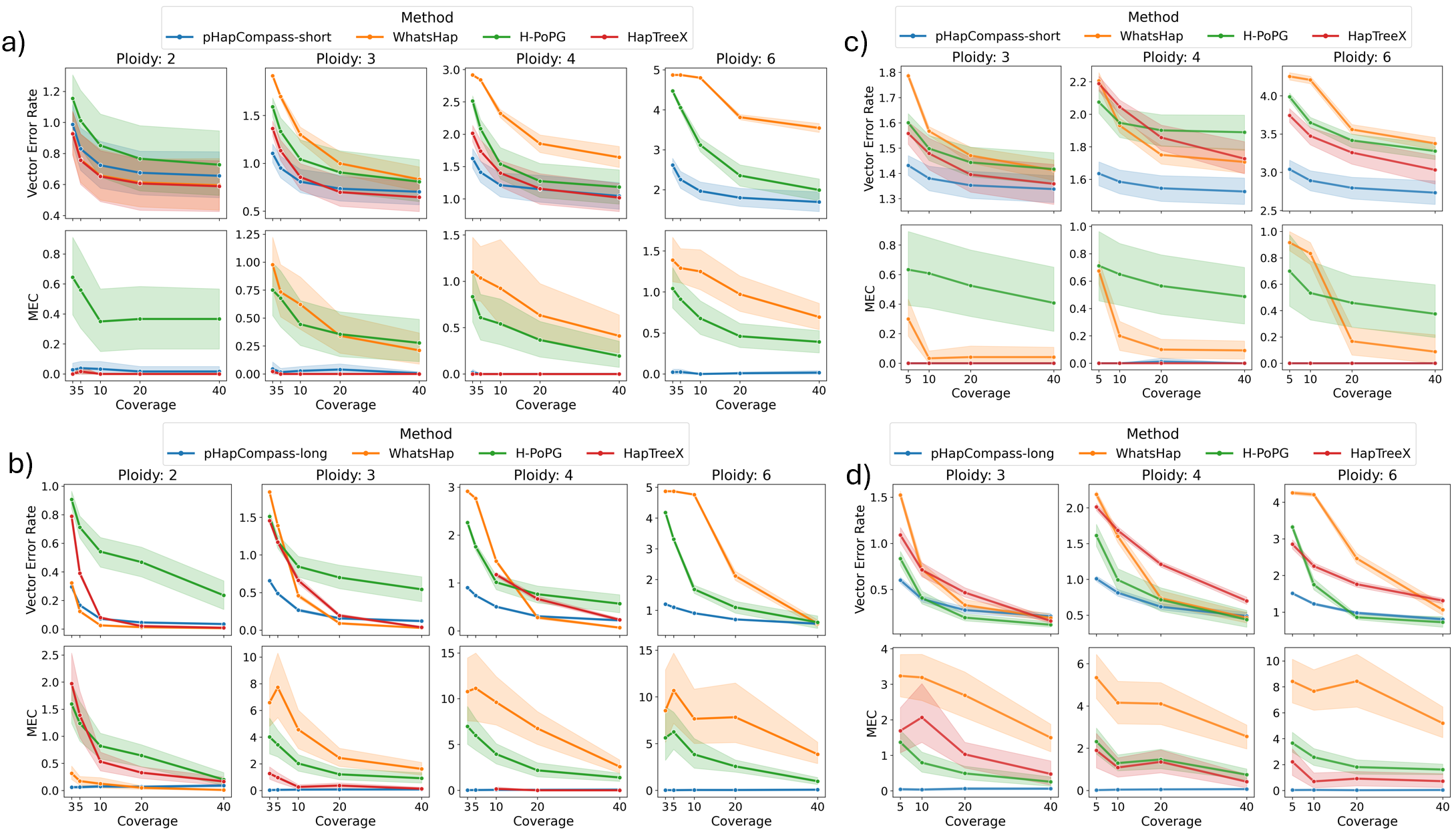
- pHapCompass demonstrates competitive performance against existing assemblers across varying ploidy levels, coverage depths, and mutation rates, while uniquely providing accurate quantification of phase uncertainty.
- The developed simulation workflow generates more realistic benchmarking datasets, revealing that prior methods often overestimate performance on simplistic synthetic genomes.
- The framework successfully assembled an allo-octoploid strawberry chromosome, showcasing practical applicability to complex, real-world polyploid genomes.
摘要: Computing haplotypes from sequencing data, i.e. haplotype assembly, is an important component of foundational molecular and population genetics problems, including interpreting the effects of genetic variation on complex traits and reconstructing genealogical relationships. Assembling the haplotypes of polyploid genomes remains a significant challenge due to the exponential search space of haplotype phasings and read assignment ambiguity; the latter challenge is particularly difficult for polyploid haplotype assemblers since the information contained within the observed sequence reads is often insufficient for unambiguous haplotype assignment in polyploid genomes. We present pHapCompass, probabilistic haplotype assembly algorithms for diploid and polyploid genomes that explicitly model and propagate read assignment ambiguity to compute a distribution over polyploid haplotype phasings. We develop graph theoretic algorithms to enable statistical inference and uncertainty quantification despite an exponential space of possible phasings. Since prior work evaluates polyploid haplotype assembly on synthetic genomes that do not reflect the realistic genomic complexity of polyploidy organisms, we develop a computational workflow for simulating genomes and DNA-seq for auto- and allopolyploids. Additionally, we generalize the vector error rate and minimum error correction evaluation criteria for partially phased haplotypes. Benchmarking of pHapCompass and several existing polyploid haplotype assemblers shows that pHapCompass yields competitive performance across varying genomic complexities and polyploid structures while retaining an accurate quantification of phase uncertainty. The source code for pHapCompass, simulation scripts, and datasets are freely available at https://github.com/bayesomicslab/pHapCompass.