
Paper List
-
STAR-GO: Improving Protein Function Prediction by Learning to Hierarchically Integrate Ontology-Informed Semantic Embeddings
This paper addresses the core challenge of generalizing protein function prediction to unseen or newly introduced Gene Ontology (GO) terms by overcomi...
-
Incorporating indel channels into average-case analysis of seed-chain-extend
This paper addresses the core pain point of bridging the theoretical gap for the widely used seed-chain-extend heuristic by providing the first rigoro...
-
Competition, stability, and functionality in excitatory-inhibitory neural circuits
This paper addresses the core challenge of extending interpretable energy-based frameworks to biologically realistic asymmetric neural networks, where...
-
Enhancing Clinical Note Generation with ICD-10, Clinical Ontology Knowledge Graphs, and Chain-of-Thought Prompting Using GPT-4
This paper addresses the core challenge of generating accurate and clinically relevant patient notes from sparse inputs (ICD codes and basic demograph...
-
Learning From Limited Data and Feedback for Cell Culture Process Monitoring: A Comparative Study
This paper addresses the core challenge of developing accurate real-time bioprocess monitoring soft sensors under severe data constraints: limited his...
-
Cell-cell communication inference and analysis: biological mechanisms, computational approaches, and future opportunities
This review addresses the critical need for a systematic framework to navigate the rapidly expanding landscape of computational methods for inferring ...
-
Generating a Contact Matrix for Aged Care Settings in Australia: an agent-based model study
This study addresses the critical gap in understanding heterogeneous contact patterns within aged care facilities, where existing population-level con...
-
Emergent Spatiotemporal Dynamics in Large-Scale Brain Networks with Next Generation Neural Mass Models
This work addresses the core challenge of understanding how complex, brain-wide spatiotemporal patterns emerge from the interaction of biophysically d...
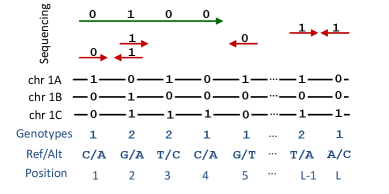
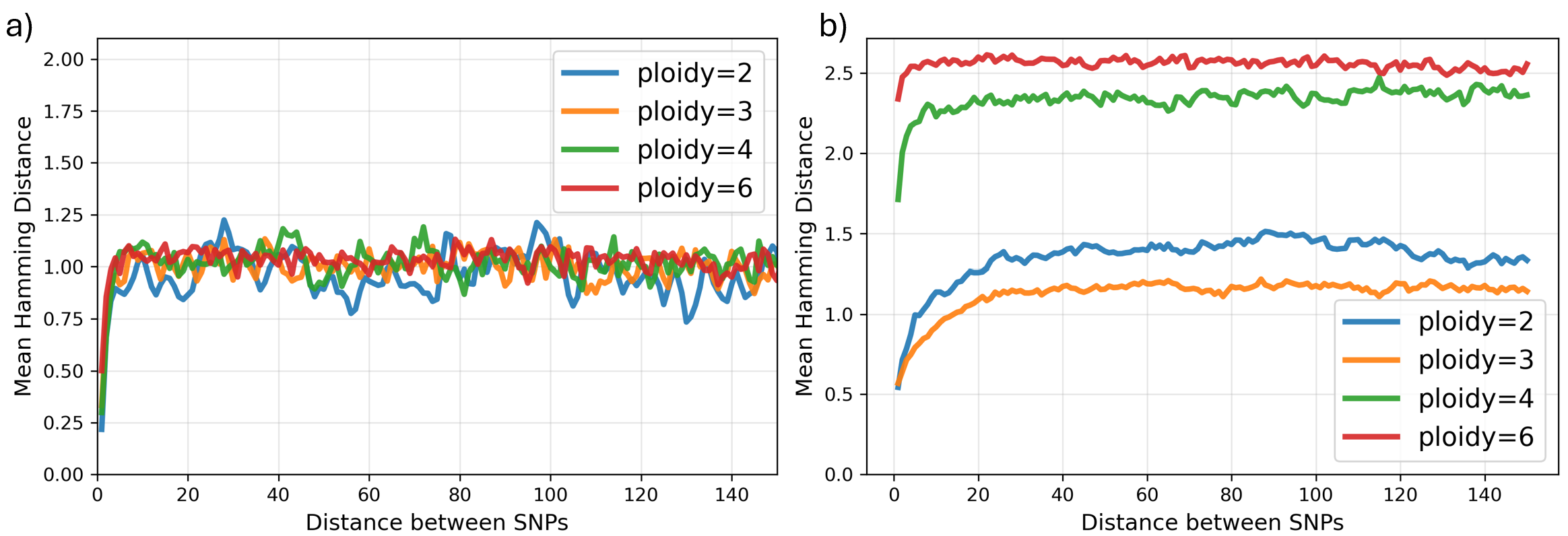
pHapCompass: Probabilistic Assembly and Uncertainty Quantification of Polyploid Haplotype Phase
School of Computing, University of Connecticut | Department of Entomology and Plant Pathology, University of Tennessee | Institute for Systems Genomics, University of Connecticut
30秒速读
IN SHORT: This paper addresses the core challenge of accurately assembling polyploid haplotypes from sequencing data, where read assignment ambiguity and an exponential search space of possible phasings have hindered reliable reconstruction and uncertainty quantification.
核心创新
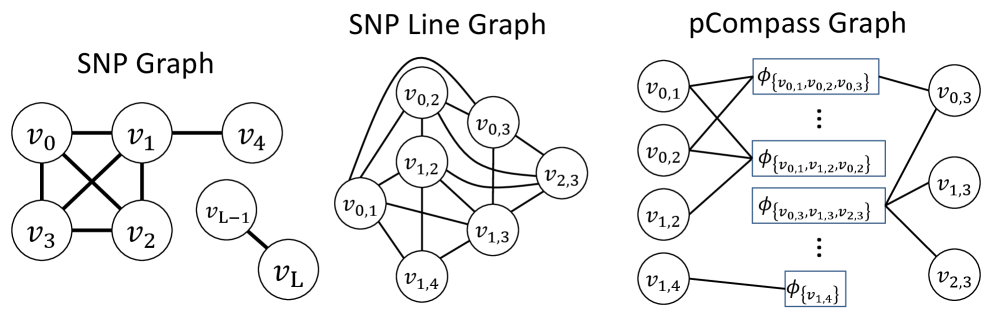
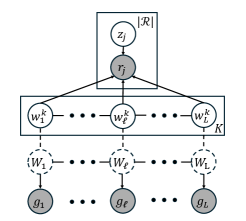
- Methodology Introduces pHapCompass, the first probabilistic haplotype assembler for diploid and polyploid genomes that explicitly models read assignment ambiguity to compute a distribution over haplotype phasings, enabling formal uncertainty quantification.
- Methodology Develops two distinct graph-theoretic algorithms: pHapCompass-short (a Markov random field for high-coverage short reads) and pHapCompass-long (a hierarchical mixture model for low-coverage long reads), both designed to scale with genomic complexity.
- Methodology Creates the first computational workflow for simulating realistic auto- and allopolyploid genomes and sequencing data, addressing a critical gap in benchmarking tools that previously relied on oversimplified synthetic genomes.
主要结论
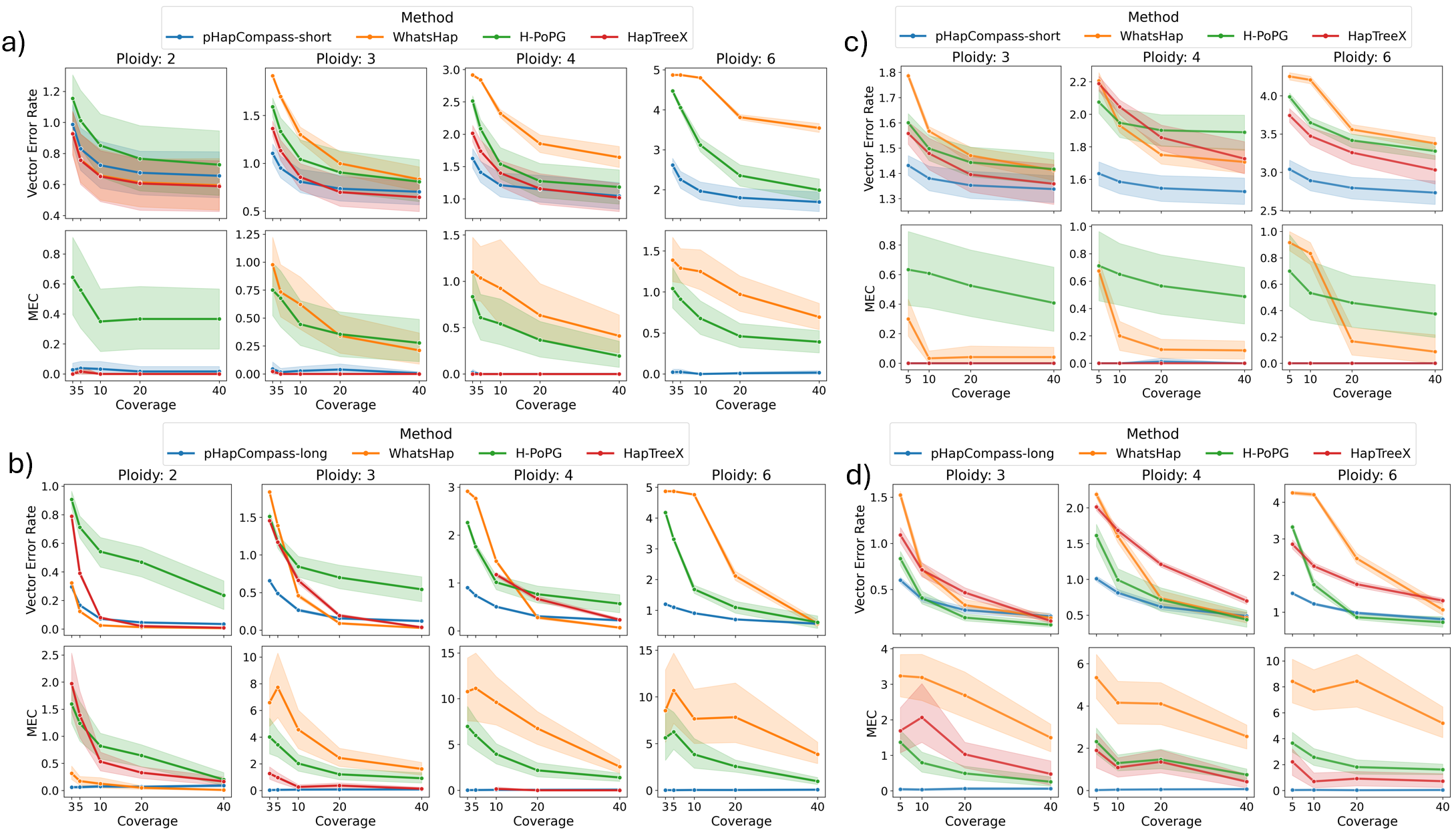
- pHapCompass demonstrates competitive performance against existing assemblers across varying ploidy levels, coverage depths, and mutation rates, while uniquely providing accurate quantification of phase uncertainty.
- The developed simulation workflow generates more realistic benchmarking datasets, revealing that prior methods often overestimate performance on simplistic synthetic genomes.
- The framework successfully assembled an allo-octoploid strawberry chromosome, showcasing practical applicability to complex, real-world polyploid genomes.
摘要: Computing haplotypes from sequencing data, i.e. haplotype assembly, is an important component of foundational molecular and population genetics problems, including interpreting the effects of genetic variation on complex traits and reconstructing genealogical relationships. Assembling the haplotypes of polyploid genomes remains a significant challenge due to the exponential search space of haplotype phasings and read assignment ambiguity; the latter challenge is particularly difficult for polyploid haplotype assemblers since the information contained within the observed sequence reads is often insufficient for unambiguous haplotype assignment in polyploid genomes. We present pHapCompass, probabilistic haplotype assembly algorithms for diploid and polyploid genomes that explicitly model and propagate read assignment ambiguity to compute a distribution over polyploid haplotype phasings. We develop graph theoretic algorithms to enable statistical inference and uncertainty quantification despite an exponential space of possible phasings. Since prior work evaluates polyploid haplotype assembly on synthetic genomes that do not reflect the realistic genomic complexity of polyploidy organisms, we develop a computational workflow for simulating genomes and DNA-seq for auto- and allopolyploids. Additionally, we generalize the vector error rate and minimum error correction evaluation criteria for partially phased haplotypes. Benchmarking of pHapCompass and several existing polyploid haplotype assemblers shows that pHapCompass yields competitive performance across varying genomic complexities and polyploid structures while retaining an accurate quantification of phase uncertainty. The source code for pHapCompass, simulation scripts, and datasets are freely available at https://github.com/bayesomicslab/pHapCompass.