
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
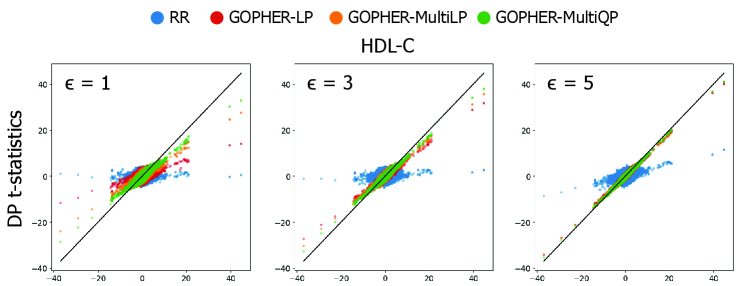
GOPHER: Optimization-based Phenotype Randomization for Genome-Wide Association Studies with Differential Privacy
Department of Biomedical Informatics & Data Science, Yale School of Medicine | Department of Technology and Operations Management, Harvard Business School | Department of Computer Science, Yale University
30秒速读
IN SHORT: This paper addresses the core challenge of balancing rigorous privacy protection with data utility when releasing full GWAS summary statistics, overcoming the limitations of prior methods that either add excessive noise or restrict output to a small subset of results.
核心创新
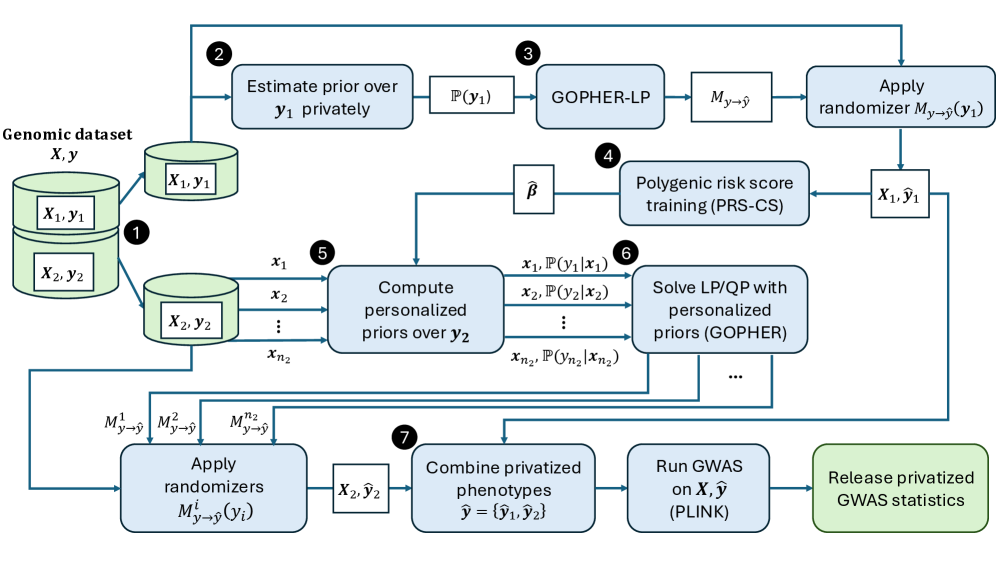
- Methodology Introduces an optimization-based phenotype randomization mechanism (GOPHER-LP) that directly minimizes expected error in GWAS statistics, formulated as a linear programming problem to enhance utility beyond baseline methods like randomized response.
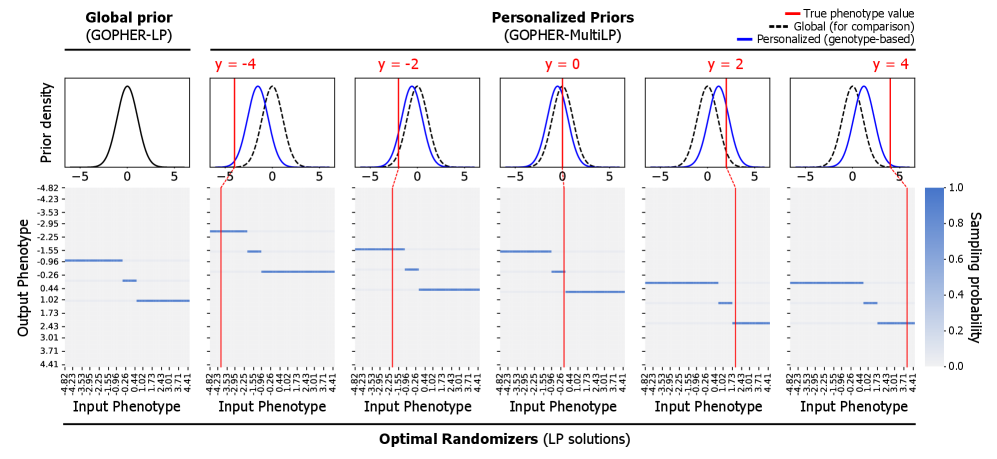
- Methodology Proposes GOPHER-MultiLP, which incorporates personalized priors derived from predictive models (e.g., polygenic risk scores) trained on a held-out subset, enabling sample-specific optimization that leverages genotype information to further reduce noise.
- Theory Adopts and extends the concept of phenotypic differential privacy (analogous to label DP), focusing protection on sensitive phenotypes while treating genotypes as public, providing a practical middle ground between full DP and unrestricted release.
主要结论
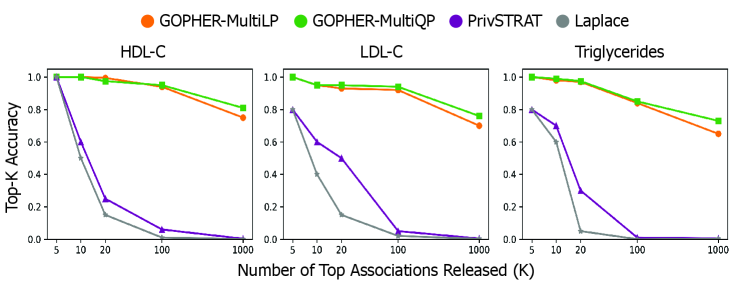
- The GOPHER framework enables the release of complete GWAS statistics (e.g., over 500,000 variants) with provable privacy guarantees, a significant scalability advance over prior methods limited to releasing only 3-5 top associations.
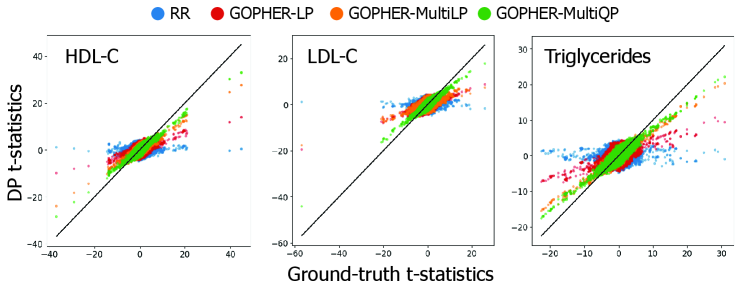
- Experiments on UK Biobank data (n=100,000) demonstrate that the mechanisms yield association statistics that accurately match non-private GWAS results while maintaining rigorous (ε, δ)-DP guarantees.
- The phenotype-randomization approach decouples the added noise from the number of genetic variants analyzed, addressing a fundamental scalability challenge not previously solved in the DP-GWAS literature.
摘要: Genome-wide association studies (GWAS) are an essential tool in biomedical research for identifying genetic factors linked to health and disease. However, publicly releasing GWAS summary statistics poses well-recognized privacy risks, including the potential to infer an individual’s participation in the study or to reveal sensitive phenotypic information (e.g., disease status). While differential privacy (DP) offers a rigorous mathematical framework for mitigating these risks, existing DP techniques for GWAS either introduce excessive noise or restrict the release to a limited set of results. In this work, we present practical DP mechanisms for releasing the complete set of genome-wide association statistics with privacy guarantees. We demonstrate the accuracy of the privacy-preserving statistics released by our mechanisms on a range of GWAS datasets from the UK Biobank, utilizing both real and simulated phenotypes. We introduce two key techniques to overcome the limitations of prior approaches: (1) an optimization-based randomization mechanism that directly minimizes the expected error in GWAS results to enhance utility, and (2) the use of personalized priors, derived from predictive models privately trained on a subset of the dataset, to enable sample-specific optimization which further reduces the amount of noise introduced by DP. Overall, our work provides practical tools for accurately releasing comprehensive GWAS results with provable protection of study participants.