
Paper List
-
Discovery of a Hematopoietic Manifold in scGPT Yields a Method for Extracting Performant Algorithms from Biological Foundation Model Internals
This work addresses the core challenge of extracting reusable, interpretable, and high-performance biological algorithms from the opaque internal repr...
-
MS2MetGAN: Latent-space adversarial training for metabolite–spectrum matching in MS/MS database search
This paper addresses the critical bottleneck in metabolite identification: the generation of high-quality negative training samples that are structura...
-
Toward Robust, Reproducible, and Widely Accessible Intracranial Language Brain-Computer Interfaces: A Comprehensive Review of Neural Mechanisms, Hardware, Algorithms, Evaluation, Clinical Pathways and Future Directions
This review addresses the core challenge of fragmented and heterogeneous evidence that hinders the clinical translation of intracranial language BCIs,...
-
Less Is More in Chemotherapy of Breast Cancer
通过纳入细胞周期时滞和竞争项,解决了现有肿瘤-免疫模型的过度简化问题,以定量比较化疗方案。
-
Fold-CP: A Context Parallelism Framework for Biomolecular Modeling
This paper addresses the critical bottleneck of GPU memory limitations that restrict AlphaFold 3-like models to processing only a few thousand residue...
-
Open Biomedical Knowledge Graphs at Scale: Construction, Federation, and AI Agent Access with Samyama Graph Database
This paper addresses the core pain point of fragmented biomedical data by constructing and federating large-scale, open knowledge graphs to enable sea...
-
Predictive Analytics for Foot Ulcers Using Time-Series Temperature and Pressure Data
This paper addresses the critical need for continuous, real-time monitoring of diabetic foot health by developing an unsupervised anomaly detection fr...
-
Hypothesis-Based Particle Detection for Accurate Nanoparticle Counting and Digital Diagnostics
This paper addresses the core challenge of achieving accurate, interpretable, and training-free nanoparticle counting in digital diagnostic assays, wh...
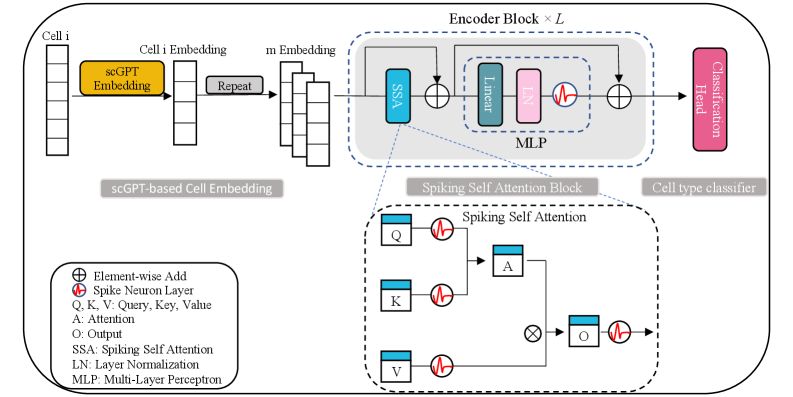
SpikGPT: A High-Accuracy and Interpretable Spiking Attention Framework for Single-Cell Annotation
Department of Biomedical Informatics, Emory University | Department of Surgery, Duke University
30秒速读
IN SHORT: This paper addresses the core challenge of robust single-cell annotation across heterogeneous datasets with batch effects and the critical need to identify previously unseen cell populations.
核心创新
- Methodology First integration of spiking neural networks with transformer architecture for single-cell analysis, using Leaky Integrate-and-Fire (LIF) neurons in a multi-head Spiking Self-Attention mechanism for energy-efficient computation.
- Methodology Novel two-step embedding expansion strategy: repeating cell embeddings along feature channels (default m=300) and temporal dimensions (default T=4) to enhance representation richness and training stability.
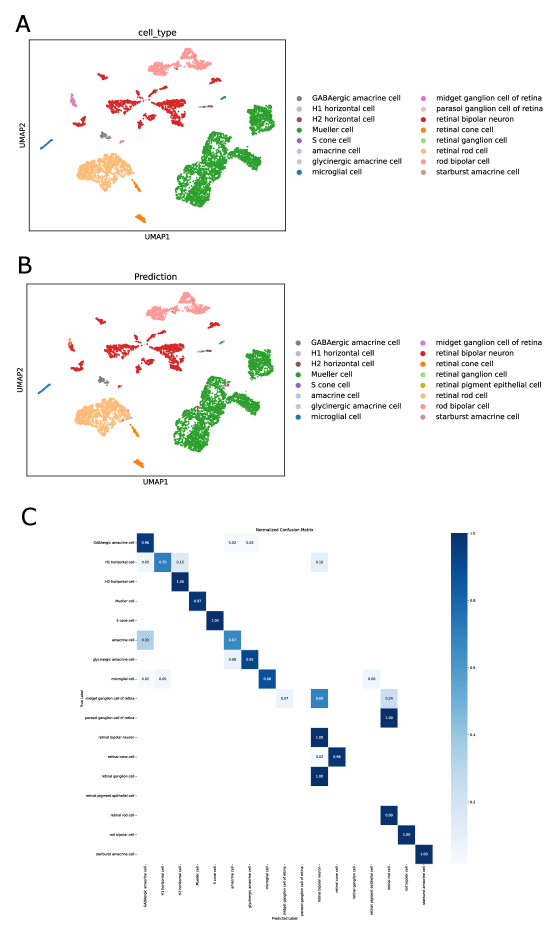
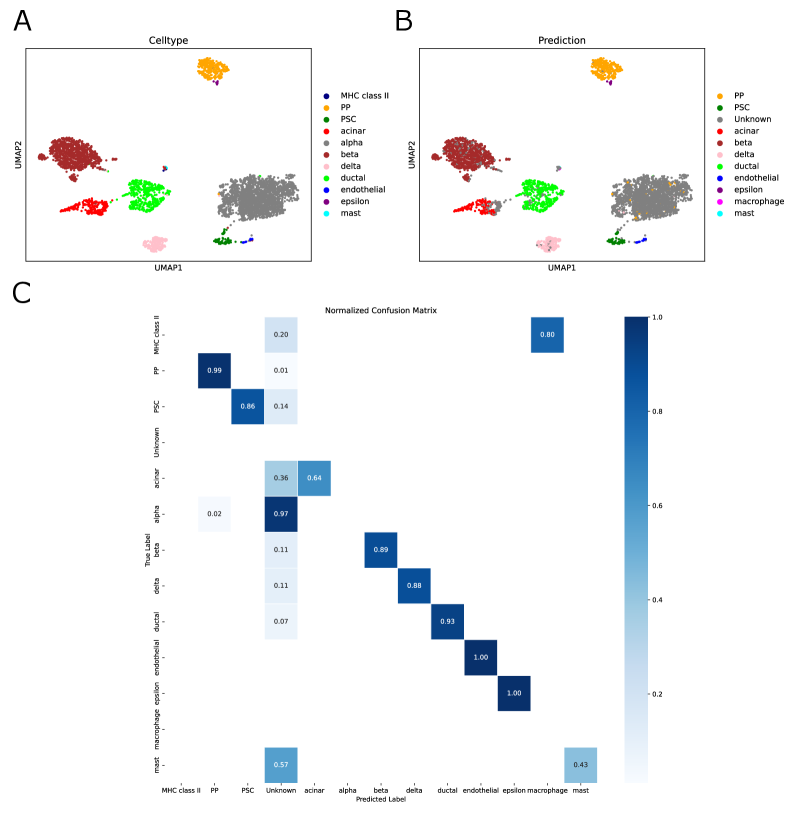
- Biology Confidence-based rejection mechanism that successfully identifies 97% of unseen 'alpha cells' as 'Unknown' in pancreas datasets, enabling robust detection of novel cell types absent from training data.
主要结论
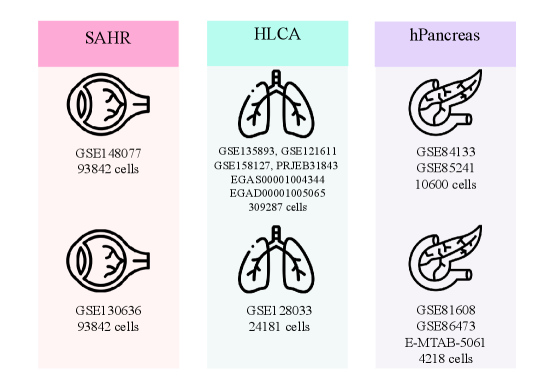
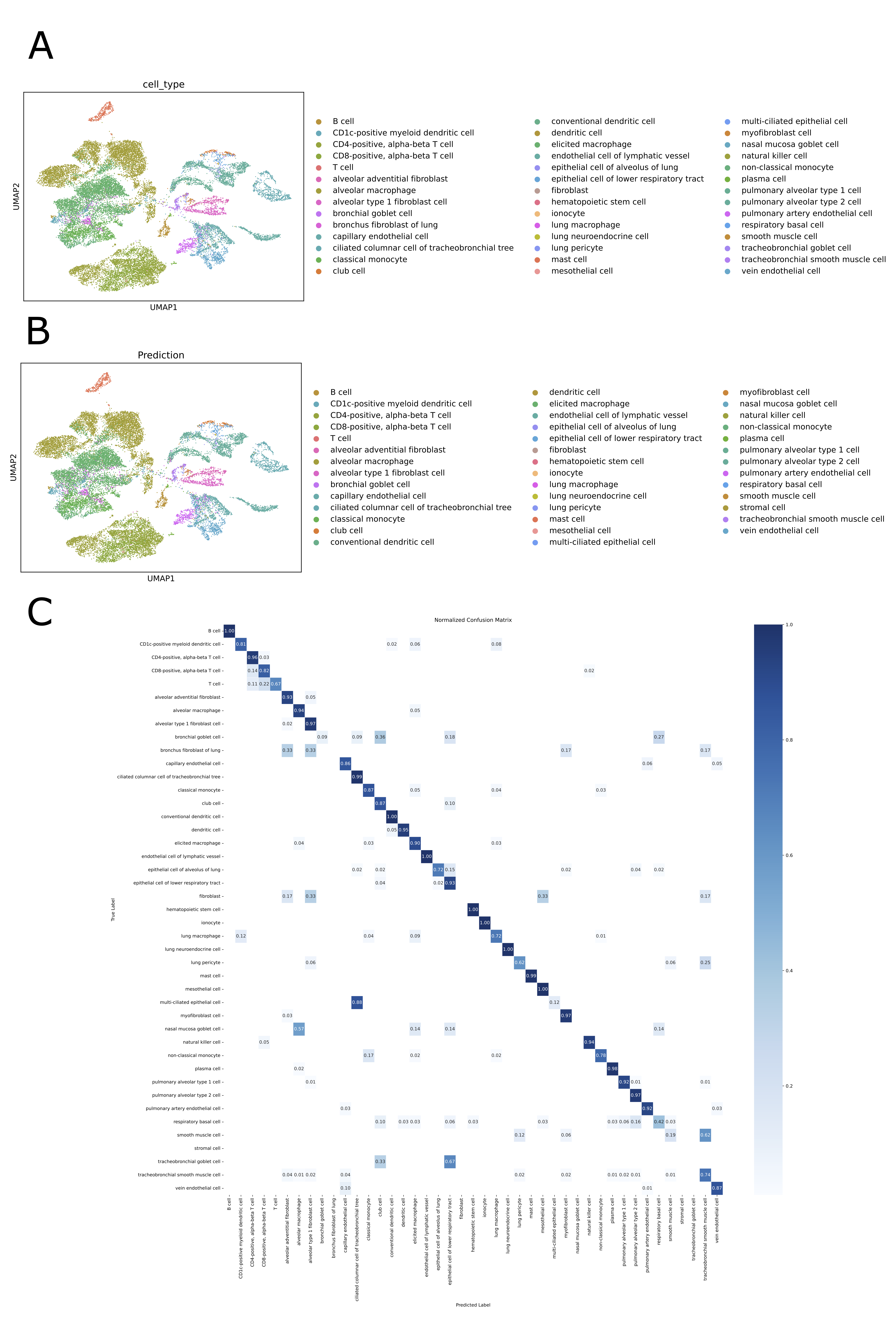
- SpikGPT achieves accuracy of 0.991 on SAHR dataset and 0.920 on HLCA dataset, outperforming or matching 8 benchmark methods including scGPT, CCA, and scPred.
- The model demonstrates superior robustness to batch effects, maintaining macro F1-score of 0.711 on heterogeneous HLCA data where traditional methods like SingleR drop to 0.207 F1-score.
- SpikGPT successfully identifies 97% of unseen 'alpha cells' as 'Unknown' using confidence thresholding (p<0.05), enabling reliable detection of novel cell populations.
摘要: Accurate and scalable cell type annotation remains a challenge in single-cell transcriptomics, especially when datasets exhibit strong batch effects or contain previously unseen cell populations. Here we introduce SpikGPT, a hybrid deep learning framework that integrates scGPT-derived cell embeddings with a spiking Transformer architecture to achieve efficient and robust annotation. scGPT provides biologically informed dense representations of each cell, which are further processed by a multi-head Spiking Self-Attention mechanism, energy-efficient feature extraction. Across multiple benchmark datasets, SpikGPT consistently matches or exceeds the performance of leading annotation tools. Notably, SpikGPT uniquely identifies unseen cell types by assigning low-confidence predictions to an 'Unknown' category, allowing accurate rejection of cell states absent from the training reference. Together, these results demonstrate that SpikGPT is a versatile and reliable annotation tool capable of generalizing across datasets, resolving complex cellular heterogeneity, and facilitating discovery of novel or disease-associated cell populations.